
In earlier articles of this series we already discussed how you can change your perspective of the process by how you configure your case ID and activity columns during the import step, and by combining multiple case ID fields and by bringing additional attribute dimensions into your process view.
All of these articles were about changing how you interpret your case and your activity fields. But you can also create different perspectives with respect to the third data requirement for process mining – Your timestamps.
There are two things that you need to keep in mind when you look at the timestamps in your data set:
1. The Meaning of Your Timestamps
Even if you have just one timestamp column in your data set, you need to be really clear about what exactly the meaning of these timestamps is. Does the timestamp indicate that the activity was started, scheduled or completed?
For example, if you look at the following HR process snippet then it looks like the ‘Process automated’ step is a bottleneck: 4.8 days median delay are shown at the big red arrow (see screenshot below).1
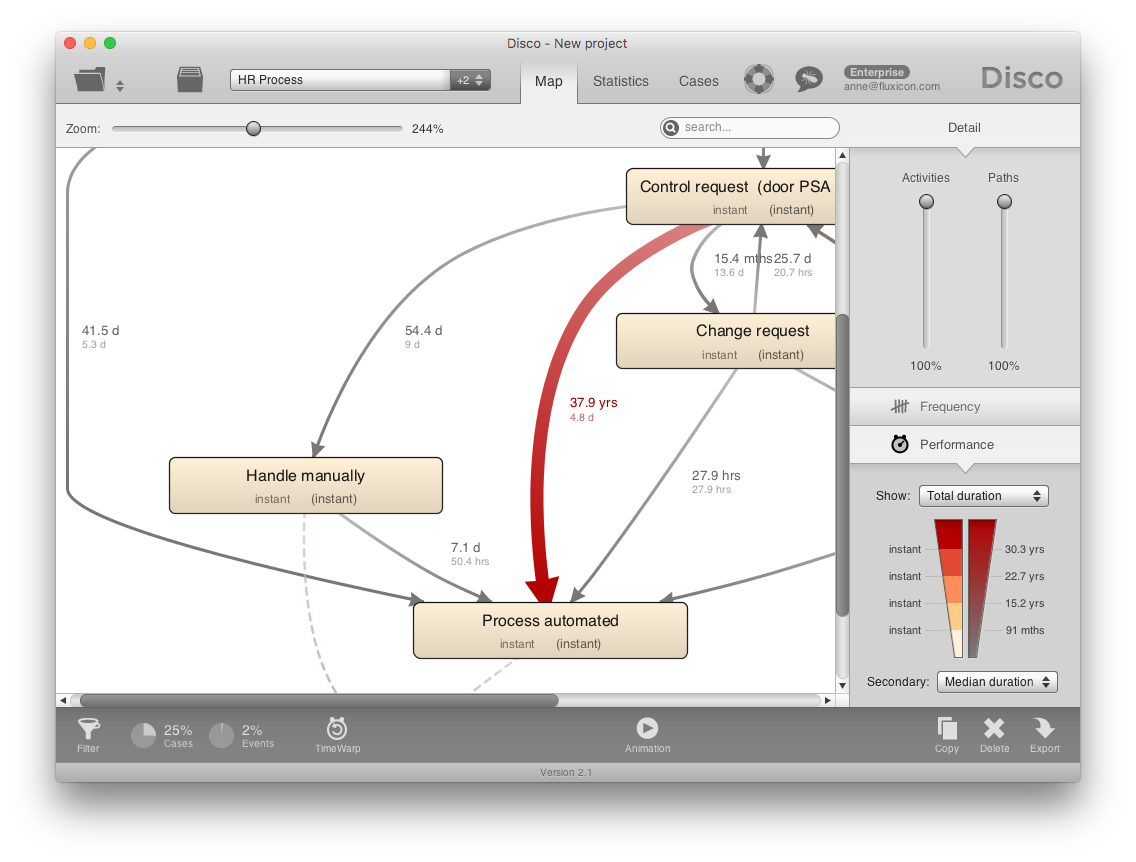
However, in fact the timestamps in this data set have the meaning that an activity has become available in the HR workflow tool. This means that at the moment that one completes an activity automatically the next activity is scheduled (and the timestamp is recorded for the newly scheduled activity).
This shifts the interpretation of the bottleneck back to the activity ‘Control request’, which is a step that is performed by the HR department: At the moment that the ‘Control request’ activity was completed, the ‘Process automated’ step was scheduled. So, the big red path shows us the time between when the step ‘Control request’ became available until it was completed.
You can see how knowing that the timestamp in the data set has the meaning of ‘scheduled’ rather than ‘completed’ shifts the interpretation of which activity is causing the delay from the target activity (the activity where the paths is going to) to the source activity (the activity from which the path is starting out).
2. Multiple Timestamp Columns
If you have a start and a complete timestamp column in your data set, then you can include both timestamps during your data import and distinguish active and passive time in your process analysis (see below).

However, sometimes you have even more than two timestamp columns. For example, let’s say that you have a ‘schedule’, a ‘start’ and a ‘complete’ timestamp for each activity. In this case you can choose different combinations of these timestamps to take different perspectives on the performance of your process.
For the example above you have three options.
Option a: Start and Complete timestamps

If you choose the ‘start’ and ‘complete’ timestamps as Timestamp columns during the import step, you will see the time between ‘start’ and ‘complete’ as the activity duration and the times between ‘complete’ and ‘start’ as the waiting times in the performance view (see above).
Option b: Schedule and Complete timestamps

If you choose the ‘schedule’ and ‘complete’ timestamps as Timestamp columns during the import step, you will see the time between ‘schedule’ and ‘complete’ as the activity duration and the times between ‘complete’ and ‘schedule’ as the waiting times in the performance view (see above). So, it shows the time between when an activity became available until it was completed rather than focusing on the time that somebody was actively working on a particular process step.
Option c: Schedule and Start timestamps

If you choose the ‘schedule’ and ‘start’ timestamps as Timestamp columns during the import step, you will see the time between ‘schedule’ and ‘start’ as the activity duration and the times between ‘start’ and ‘schedule’ as the waiting times in the performance view (see above). Here, the activity durations show the time between when an activity became available until it was started.
All of these views can be useful and you can import your data set in different ways to take these different views and answer your analysis questions.
Conclusion
Timestamps are really important in process mining, because they determine the order of the event sequences on which the process maps and variants are based. And they can bring all kinds of problems (see also our series on data quality problems for process mining here).
But the meaning of your timestamps also influences how you should interpret the durations and waiting times in your process map. So, in summary:
-
Make sure that you fully understand the meaning of the timestamps in your data set. Especially, if you only have one timestamp for each activity: Does this timestamp mean that the activity was ready to be performed? Was it started? Was it completed?
-
If you have more than two timestamps, be clear on which are the ones that you want to use for your analysis. For example: The time from ‘Started’ to ‘Completed’? Or the time from ‘Scheduled’ to ‘Completed’? Also here you can take different perspectives by importing your data set in different configurations to support different types of analyses.
-
Learn more about how to perform a bottleneck analysis with process mining here. ↩︎

Anne Rozinat
Market, customers, and everything else
Anne knows how to mine a process like no other. She has conducted a large number of process mining projects with companies such as Philips Healthcare, Océ, ASML, Philips Consumer Lifestyle, and many others.