
Previously, we discussed how you can take different perspectives on your data by choosing what you want to see as your activity name, case ID, and timestamps.
One of the ways in which you can take different perspectives is to bring an additional dimension into your process map by combining more than one column into the activity name. You can do this in Disco by simply configuring more than one column as ‘Activity’ (learn how to do this in the Disco user guide here).
By bringing in an additional dimension, you can “unfold” your process map in a way that does not only show which activities took place in the process, but also in which department, for which problem category, or in which location the activity took place. For example, by bringing in the agent position from your callcenter data set you can see which activities took place in the first level support team and differentiate them from the steps that were performed by the backoffice workers, even if the activity labels for their tasks are the same.
You can experiment with bringing in all kinds of attributes into your process view. When you do this, you can observe two different effects.
1. Comparing Processes
When you bring in a case-level attribute that does not change over the course of the case, you will effectively see the processes for all values of your case-level attribute next to each other – in the same process map. For example, the screenshot below shows a customer refund process for both the Internet and the Callcenter channel next to each other.
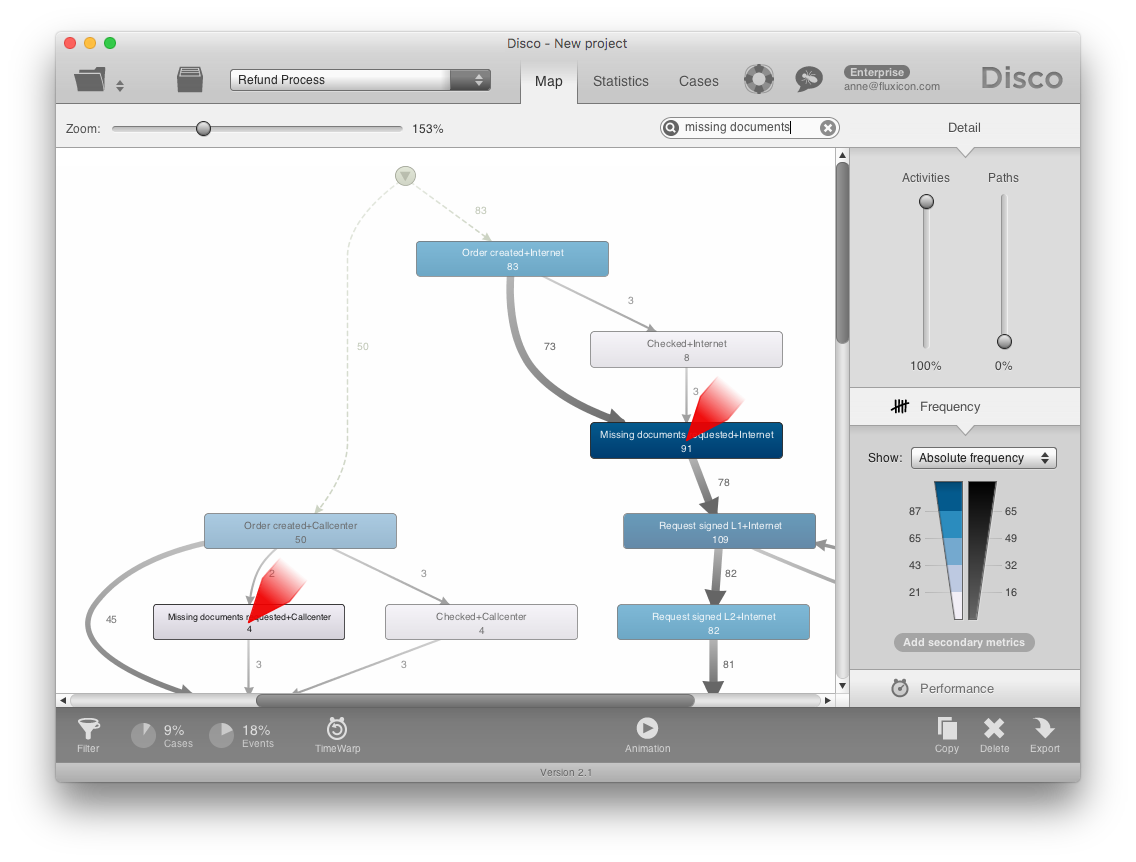
Seeing two or more processes next to each other in one picture side by side can be an alternative to filtering the process in this dimension. Of course, you can still apply filters to only compare a few of the processes at once.
2. Unfolding Single Activities
When you have an attribute that is only filled for certain events, then bringing in this attribute into your activity name will only unfold the activities for which it is filled.
For example, a document authoring process may consist of the steps Create, Update, Submit, Approve, Request rework, Revise, Publish, and Discard (performed by different people such as authors and editors). Imagine that in this document authoring process, you have additional information in an extra column about the level of required rework (major vs. minor) in the Request rework step.
If you just use the regular process step column as your activity, then Request rework will show up as one activity node in your process map (see image below).

However, if you include the ‘Rework type’ attribute in the activity name, then two different process steps Request rework - major and Request rework - minor will appear in the process map (see below).

This can be handy in many other processes. For example, think of a credit application process that has a ‘Reject reason’ attribute that provides more information about why the application was rejected. Unfolding the ‘Reject’ activity in the ‘Reject reason’ dimension will enable you to visualize the different types of rejections right in the process map in a powerful way.
Conclusion
So, already while you are in the stage of preparing your data set it is worth thinking about how you can best structure your attribute data.
As a rule of thumb:
-
Put your data into separate columns rather than combining them already in the source data. You will still be able to combine them during the import step and this will preserve your flexibility to combine them in different ways than you anticipated. It will also allow you to take a more high-level view (like the document authoring process view above that did not distinguish the ‘major’ and ‘minor’ rework steps).
-
Think about whether the attribute is related to a particular activity or to the whole case. If an attribute is only about one particular activity, it will be better to keep the cells for this attribute empty for the other activities. This way, you can decide to unfold just that one particular activity if you want to (rather than duplicating the whole process).

Anne Rozinat
Market, customers, and everything else
Anne knows how to mine a process like no other. She has conducted a large number of process mining projects with companies such as Philips Healthcare, Océ, ASML, Philips Consumer Lifestyle, and many others.