
[This article previously appeared in the Process Mining News Sign up now to receive regular articles about the practical application of process mining.]
Data for process mining can come from many different places. One of the big advantages of process mining is that it is not specific to some kind of system. Any workflow or ticketing system, ERPs, data warehouses, click-streams, legacy systems, and even data that was collected manually in Excel, can be analyzed as long as a Case ID, an Activity name, and a Timestamp column can be identified.
However, most of that data was not originally collected for process mining purposes. And especially data that has been manually entered can always contain errors. How do you make sure that errors in the data will not jeopardize your analysis results?
Data quality is an important topic for any data analysis technique: If you base your analysis results on data, then you have to make sure that the data is sound and correct. Otherwise, your results will be wrong! If you show your analysis results to a business user and they turn out to be incorrect due to some data problems, then you can lose their trust into process mining forever.
There are some challenges regarding data quality that are specific to process mining. Many of these challenges revolve around problems with timestamps. In fact, you could say that timestamps are the achilles heel of data quality in process mining. But timestamps are not the only problem.
In this series, we will look into the most common data quality problems and how to address them.
- Part 1: Formatting Errors (this article)
- Part 2: Missing Data
- Part 3: Zero Timestamps
- Part 4: Wrong Timestamp Configuration
- Part 5: Same Timestamp Activities
- Part 6: Different Timestamp Granularities
- Part 7: Recorded Timestamps Do Not Reflect Actual Time of Activities
- Part 8: Different Clocks
- Part 9: Missing Timestamps
- Part 10: Missing Timestamps For Activity Repetitions
- Part 11: Data Validation Session with Domain Expert
- Part 12: Missing History
- Part 13: Missing Complete Timestamps for Ongoing Activities
- Part 14: Unwanted Parallelism
- Part 15: To be continued
Here is the first part.
Errors During Import
A first check is to pay attention to any errors that you get in Disco during the import step. In many situations, errors stem from improperly formatted CSV files, because writing good CSV files is harder than you might think.
For example, the delimiting character (, ; I etc.) cannot be used in the content of a field without proper escaping. If you look at the example snippet below then you can see that the , delimiter has been used to separate the columns. However, in the last row the activity name itself contains a comma:
Case ID, Activity case1, Register claim case1, Check case1, File report, notify customer
Proper CSV requires that the File report, notify customer activity is enclosed in quotes to indicate that the , is part of the name:
Case ID, Activity case1, Register claim case1, Check case1, "File report, notify customer"
Another problem might be that your file has less columns in some rows compared to others (see example below).
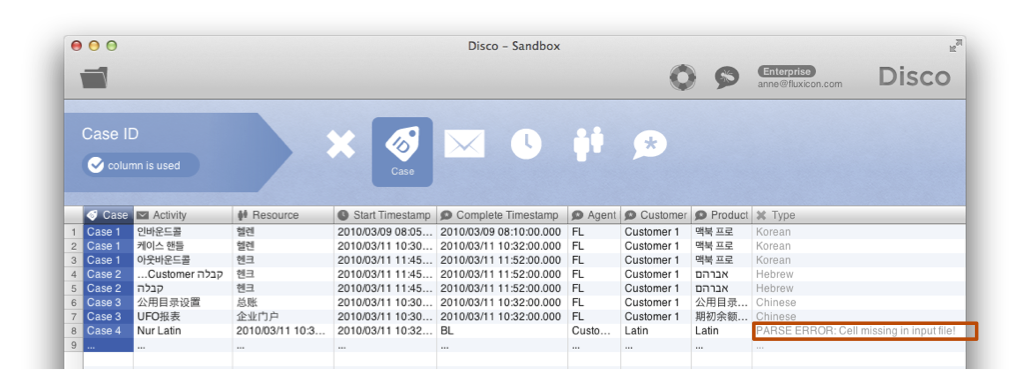
Other typical problems are invalid characters, quotes that open but do not close, and there are many more.
If Disco encounters a formatting problem, it gives you the following error message with the sad triangle and also tries to indicate in which line the problem occurs (see below).

In most cases, Disco will still import your data and you can take a first look at it, but make sure to go back and investigate the problem before you continue with any serious analysis.
We recommend to open the file in a text editor and look around the indicated line number (a bit before and afterwards, too) to see whether you can identify the root cause.
How to fix: Occasionally, the formatting problems have no impact on your data (for example, an extra comma at the end of some of the lines in your file). Or the number of lines impacted are so few that you choose to ignore it. But in most cases you do need to fix it.
Sometimes, it is enough to use Find and Replace in Excel to replace a delimiting character from the content of your cells and export a new, cleaned CSV that you then import.
However, in most cases it will be the easiest to point out the problem that you found to the person who extracted the data for you and ask them to give you a new file that avoids the problem.

Anne Rozinat
Market, customers, and everything else
Anne knows how to mine a process like no other. She has conducted a large number of process mining projects with companies such as Philips Healthcare, Océ, ASML, Philips Consumer Lifestyle, and many others.