
This is the fifth article in our series on data quality problems for process mining. Make sure you also read the previous articles on formatting errors, missing data, Zero timestamps, and wrong timestamp configurations.
In the previous article on wrong timestamp configurations we have seen how timestamp problems can influence the process flows and the process variants. One reason for why timestamps can cause problems is that they are not sufficiently different. For example, if you only have a date (and no time) then it may easily happen that two activities within the same case happen on the same day. As a result you don’t know in which order they actually happened!
Take a look at the following example: We can see a simple document signing process with four activities and three cases.

The order of the rows in each case is arbitrary. When importing this data set, the sequence of events is determined based on the timestamps. For example, the sequence of the steps ‘Created’ and ‘Sent to Customer’ for case 1 is reversed (compared to the original file), because the dates reflect that the two steps have happened in the opposite order (see screenshot below).
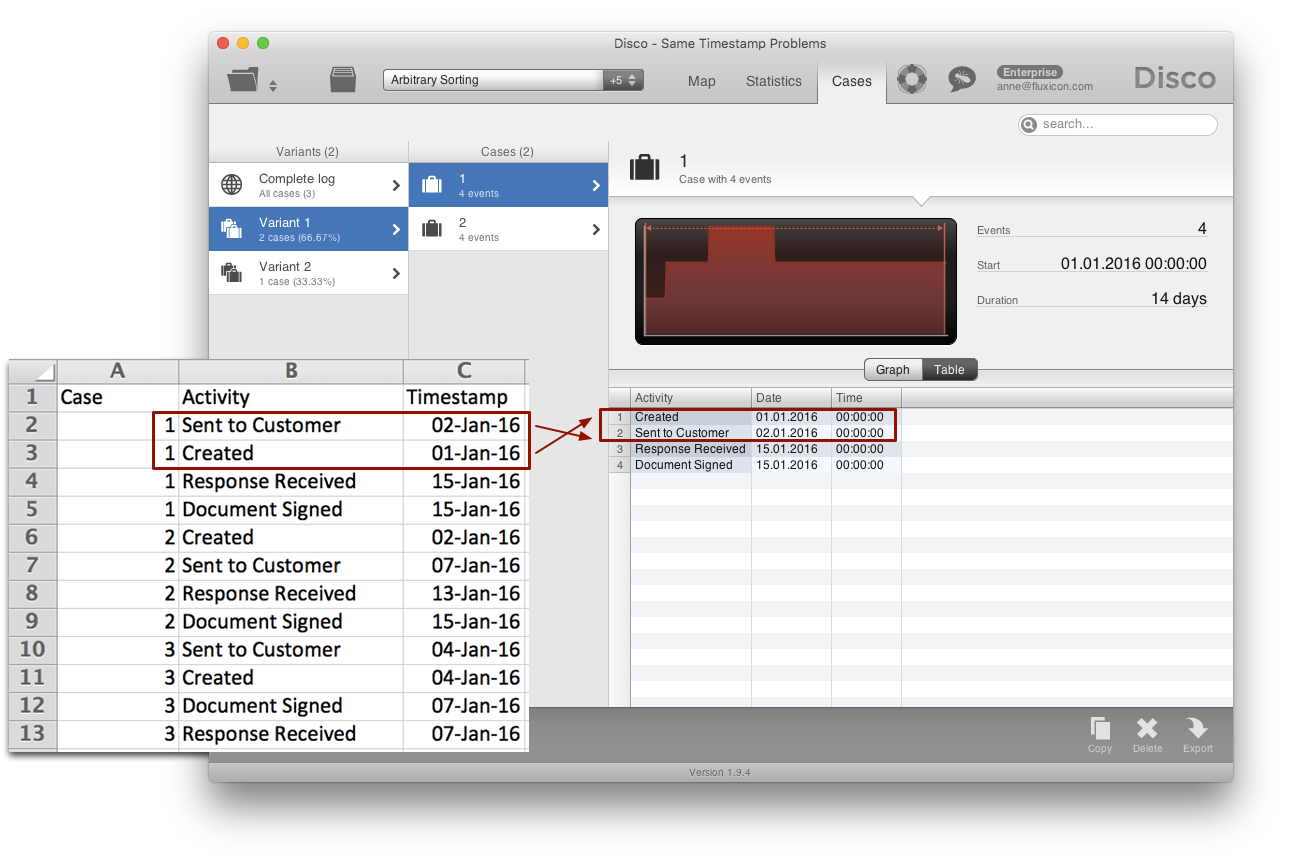
However, if two activities happen at the same time (on the same day in this example), then Disco does not know in which order they actually occurred. So, it keeps the order in which they appear in the original file. Because the order of the activities in the example file is random, this creates some additional variation in the process map (and in the variants) that should not be there.
For example, the three cases in the above example come from a purely sequential process. However, because sometimes multiple steps happen on the same day, and the order between them is arbitrary, you can see some additional interleavings in the process map. They reflect the different orderings of the same timestamp activities in the file (see screenshot below).
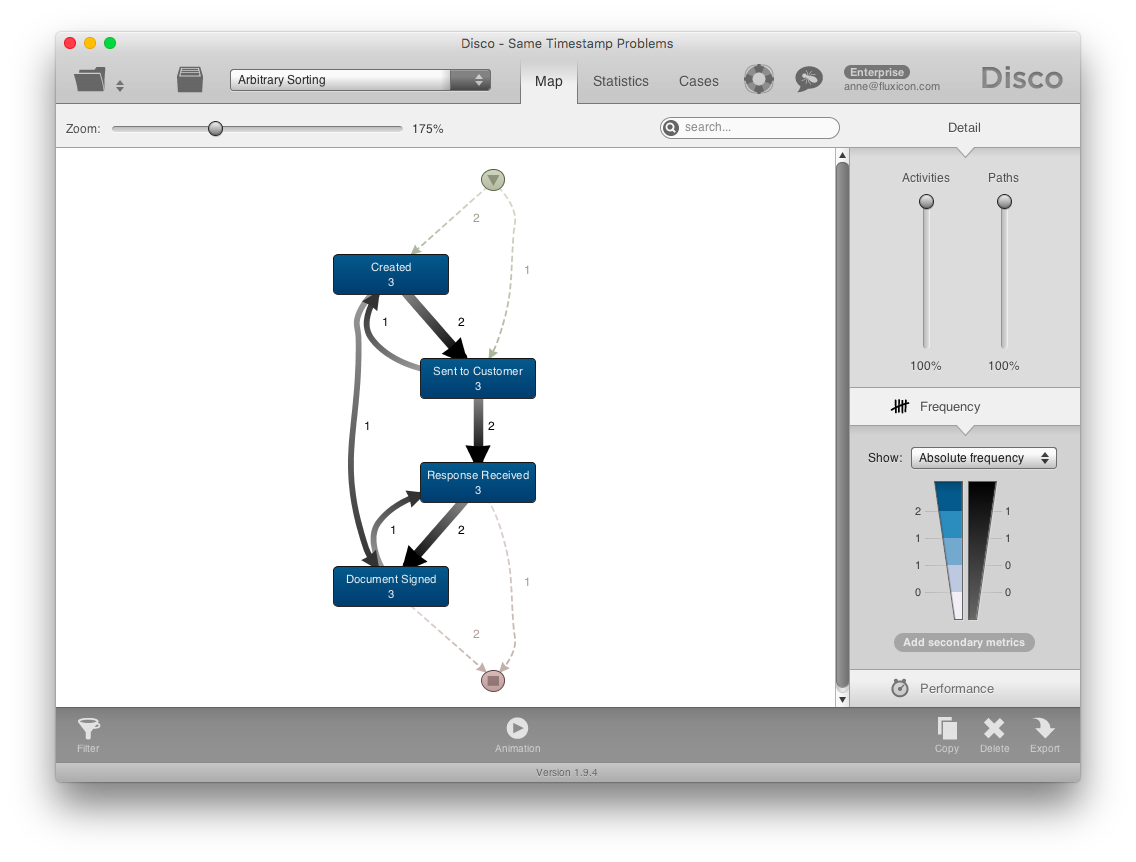
So, if you don’t have sufficiently fine-granular timestamps to determine the order of all activities, or if you have many steps in your process occurring exactly at the same time, it often creates more complexity than is already there. What can you do to distinguish the real process complexity from the one just caused by the same timestamp problem?
How to fix: You can either leave out events that have the same timestamps by choosing a “representative” event (see strategy 1 below), or you can try pre-sorting the data (see strategies 2-4 below) to reduce the variation that is caused by the same timestamp activities.
Strategy 1: “Representative” (Leaving out events)
The reason for ‘Same Timestamp’ activities is not always an insufficient level of granularity in the timestamp pattern. Sometimes, it is simply a fact that many events are logged at the same time.
Imagine, for example, a workflow system in a municipality, where the service employee types in the new address of a citizen who moved to a new apartment. After the street, street number, postal code, city, etc., fields in the screen have been filled, they press ‘Next’ to finalize the registration change and print the receipt.
In the history log of the workflow system, you will most likely see individual records of the changes to each of these fields (for example, a record of the ‘Old value’ and the ‘New value’ of the ‘Street’ attribute). However, all of them may have the same timestamp, which is the time when the employee pressed the ‘Next’ button and the data field changes were all finalized (at once).
Below, you can see another example of a highly automated process. Many steps happen at the same time.
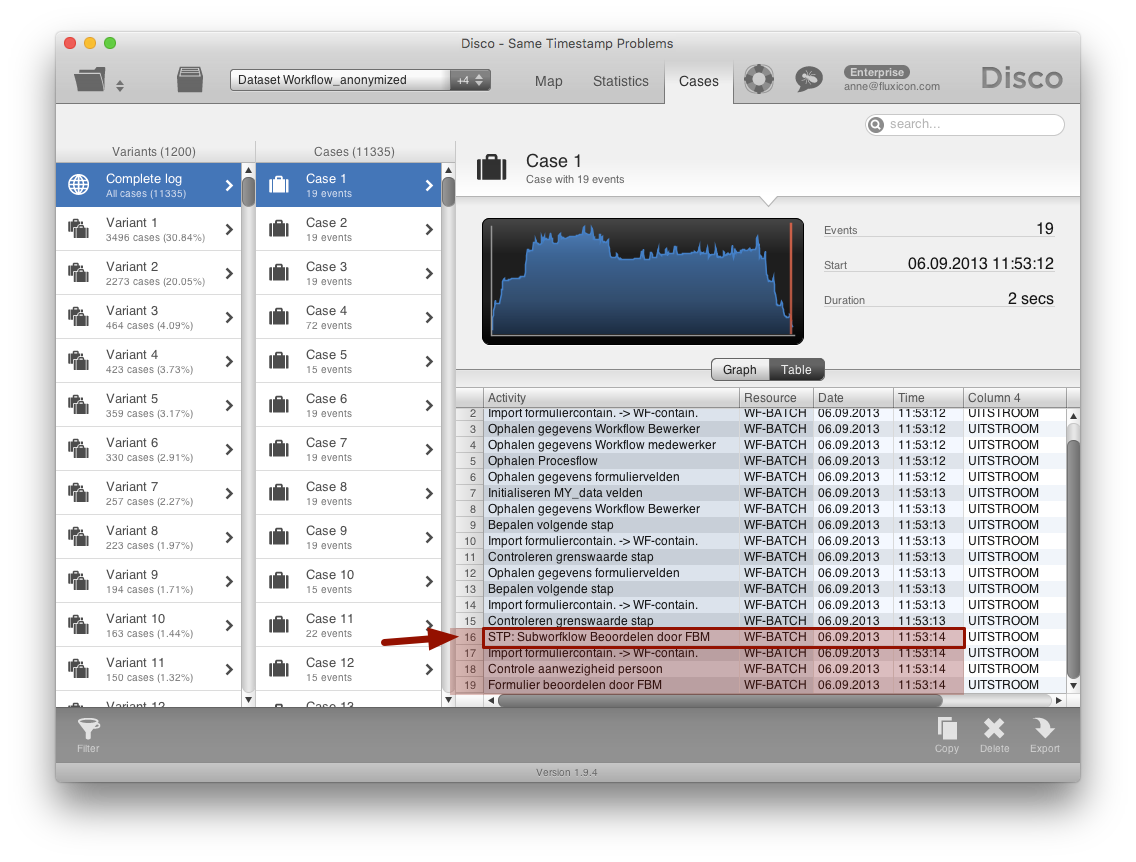
However, you may not need all of these detailed events and can choose one of them to represent the whole subsequence. For example, in the case below the first of the four highlighted events could stand for the sequence of four. You can deselect the other steps via the Keep selected option in the Attribute filter.
In general, focusing on just a few - the most relevant - milestone activities is one of the most effective methods to trim down the data set to more meaningful variants if you have too many - See also Strategy No. 9 in this article about How to Manage Complexity in Process Mining.
Strategy 2: Sorting based on sequence number
Sometimes you actually have information about in which sequence the activities occurred in some kind of sequence number attribute. This is great, because you can now sort your data set based on the sequence number (see below) and avoid the whole Same Timestamp Activities problem altogether.
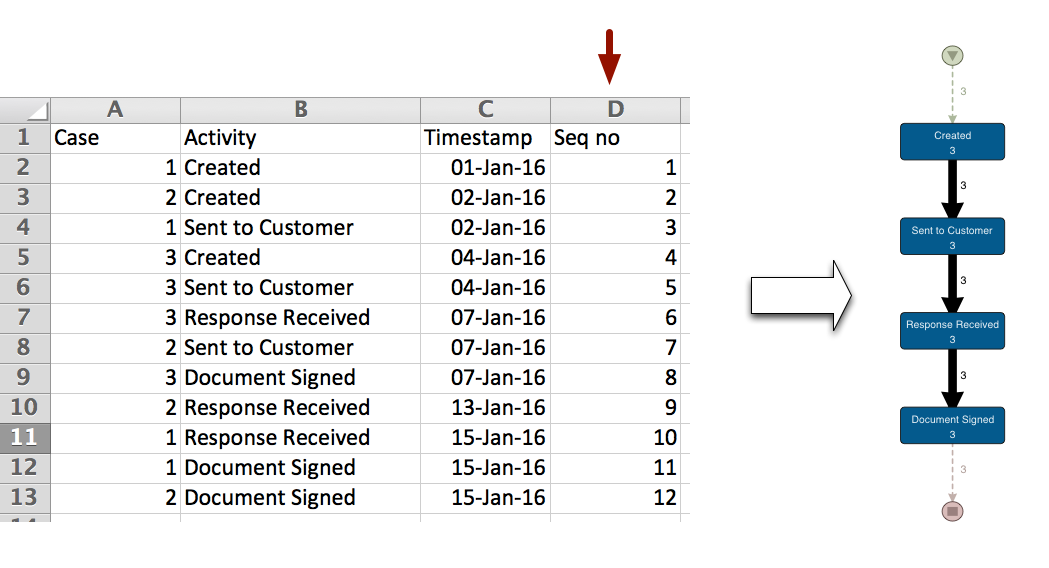
Because Disco uses the sequence from the activities in your original file for the events that have the same timestamp, this pre-sorting step will influences the order in which the variants and the process flows are formed and, therefore, fix the random order of the Same Timestamp Activities.
Strategy 3: Sorting based on activity name
Of course you don’t always have a sequence number that you can rely on for sorting the data. So what else can you do?
Another way that often helps is that you can pre-sort the data simply based on the activity name. The idea is that at least the activities that have the same timestamp (and are sometinmes in this and sometimes in that order) are now always in the same order, even if the order itself does not make much sense.
This is easy to do: Simply sort the data based on your activity column before importing it. However, sometimes this strategy can also backfire, because you may - accidentally - introduce wrong orders in same timestamp activities that by coincidence were fine before.
For example, consider the outcome of sorting the data based on activity name for the document signing process above:

It has helped to reduce the variation in the beginning of the process, but at the same time it has introduced a reverse order for the activities ‘Document Signed’ and ‘Response Received’ for case 3 (which have the same timestamps but were in the right order by coincidence in the original file).
Strategy 4: Sorting based on ideal sequence
To influence the order of the Same Timestamp Activities in the “right” way, you can analyze those process sequences in your data that are formed by actual differences in the timestamp. You can also talk to a domain expert to help you understand what the ideal sequence of the process would be.
For example, if you look at case 2 in the document signing process, then you can see that the sequence is fully determined by different timestamps (see screenshot below).
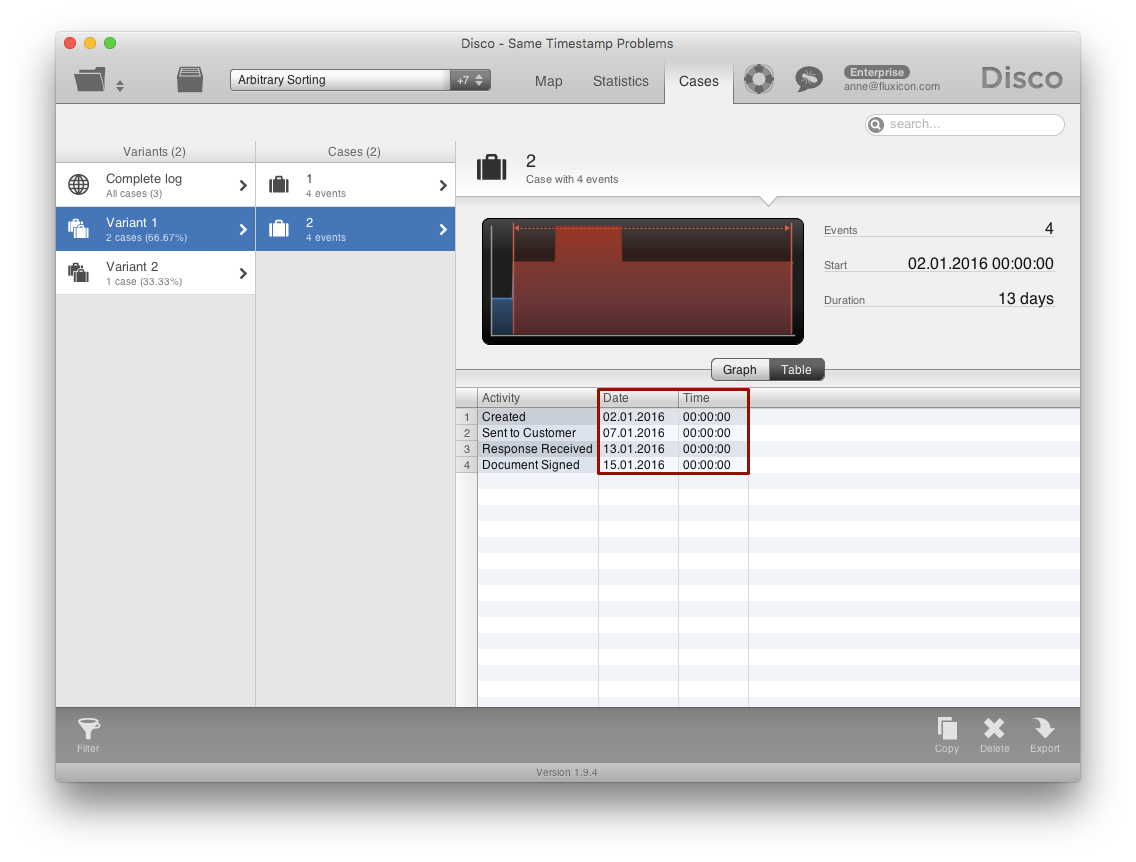
We are now going to use this ideal sequence to influence the sorting of the original data. One simple way to do it is to pre-face the activity names by a sequence number reflecting their place in the ideal sequence (i.e., 1 - Created, 2 - Sent to Customer, 3 - Response Received, and 4 - Document Signed) by using Find and Replace.
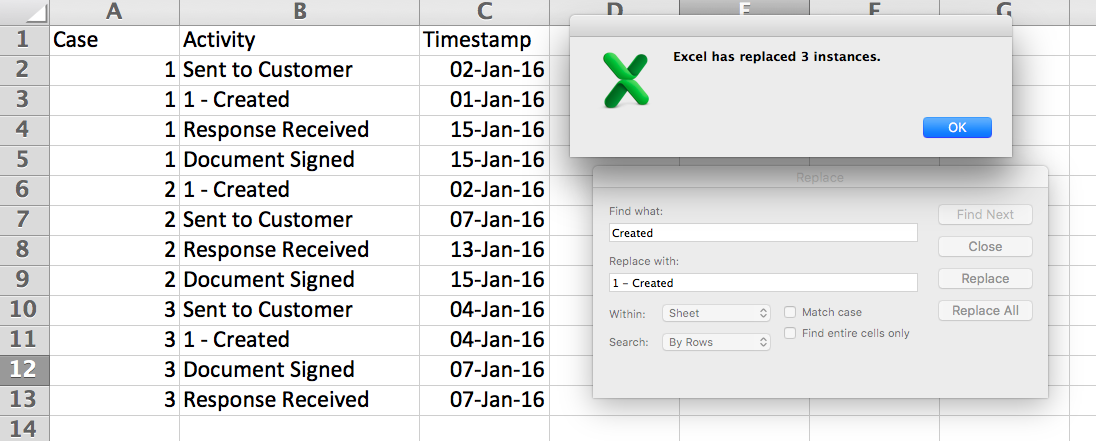
After adding the sequence numbers, you can simply sort the original data by the activity column (see below).

This will bring the activities in the ideal sequence. When you now import the data in Disco, you should only see deviations from the ideal sequence if the timestamps actually reflect that.

Anne Rozinat
Market, customers, and everything else
Anne knows how to mine a process like no other. She has conducted a large number of process mining projects with companies such as Philips Healthcare, Océ, ASML, Philips Consumer Lifestyle, and many others.