
This is the ninth article in our series on data quality problems for process mining. You can find an overview of all articles in the series here.
Earlier in this series, we have talked about how missing data can be a problem. We looked at missing events, missing attribute values, and missing case IDs. But what do you do if you have missing activities, or missing timestamps for some activities?
There are two scenarios for missing timestamps.
1. Missing activities
Some activities in your process may not be recorded in the data. For example, there may be manual activities (like a phone call) that people perform at their desk. These activities occur in the process but are not visible in the data.
Of course, the process map that you discover using process mining will not show you these manual activities. What you will see is a path from the activity that happened before the manual activity to the activity that happened after the manual activity.
For example, in the process map below you see the sandbox example in Disco. There is a path from activity Create Request for Quotation to Analyze Request for Quotation. However, it could be that there was actually another activity that took place between these two process steps, which is not visible in the data.

How to fix:
There is not much you can do here. What is important is to be aware that these activities take place although you cannot see them in the data. Process mining mining cannot be performed without proper domain knowledge about the process you are analyzing. Make sure you talk to the people working in the process to understand what is happening.
You can then take this domain knowledge into account when you interpret your results. For example, in the process above you would know that not all the 21.7 days are actually idle time in the process. Instead, you know that other activities are taking place in between, but you can’t see them in the data. It’s like a blind spot in your process. Typically, with the proper interpretation you are just fine and can complete your analysis based on the data that you have.
However, sometimes the blind spot becomes a problem. For example, you might find that your biggest bottlenecks are in this blind spot and you really need to understand more about what happens there. In this situation, you may choose to go back and collect some manual data about this part of the process either through observation or by asking the employees to document their manual activities for a few weeks. Make sure to record the case ID along with the activities and the timestamps in this endeavor. Afterwards, you can combine the manually collected data with the IT data to analyze the full process, but now with visibility on the blind spot.
2. Missing timestamps for some activities
In a second scenario you actually have information about which activities were performed, but for some of the activities you simply don’t have a timestamp.
For example, in the data snippet from an invoice handling process (see screenshot below - click on image to see a larger version) we can see that in some of the cases an activity Settle dispute with supplier was performed. In contrast to all the other activities, this activity has no timestamp associated. It simply might not have been recorded by the system, or the information about this activity comes from a different system.
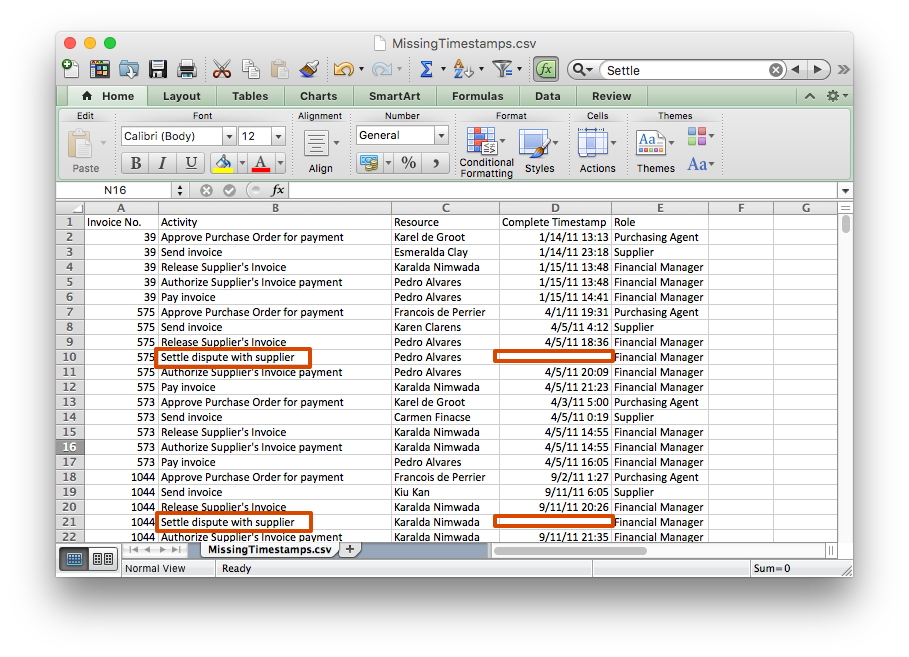
The problem with a data set where some events have a timestamp and others don’t is that the process mining tool cannot infer the sequence of the activities. Normally, the events are ordered based on the timestamps during the import of the data. So, what can you do?
There are essentially three options.
How to fix:
Ignoring the events that have no timestamp. This will allow you to analyze the performance of your process but omit all activities that have no timestamp associated (see example below).
Importing your data without a timestamp configuration. This will import all events based on the order of the activities from the original file. You will see all activities in the process map, but you will not be able to analyze the waiting times in the process (see example below).
You can “borrow” the timestamps of a neighbouring activity and re-use them for the events that do not have any timestamps (for example, the timestamp of their successor activity). This data pre-processing step will allow you to import all events and include all activities in the process map, while preserving the possibility to analyze the performance of your process as well.
Let’s look at how option 1 and 2 look like based on the example above.
First, we can import the data set in the normal way. When the timestamp column is selected, Disco gives you a warning that the timestamp pattern is not matching all rows in the data (see screenshot below). The reason for this mismatch are the empty timestamp fields of the Settle dispute with supplier activity.
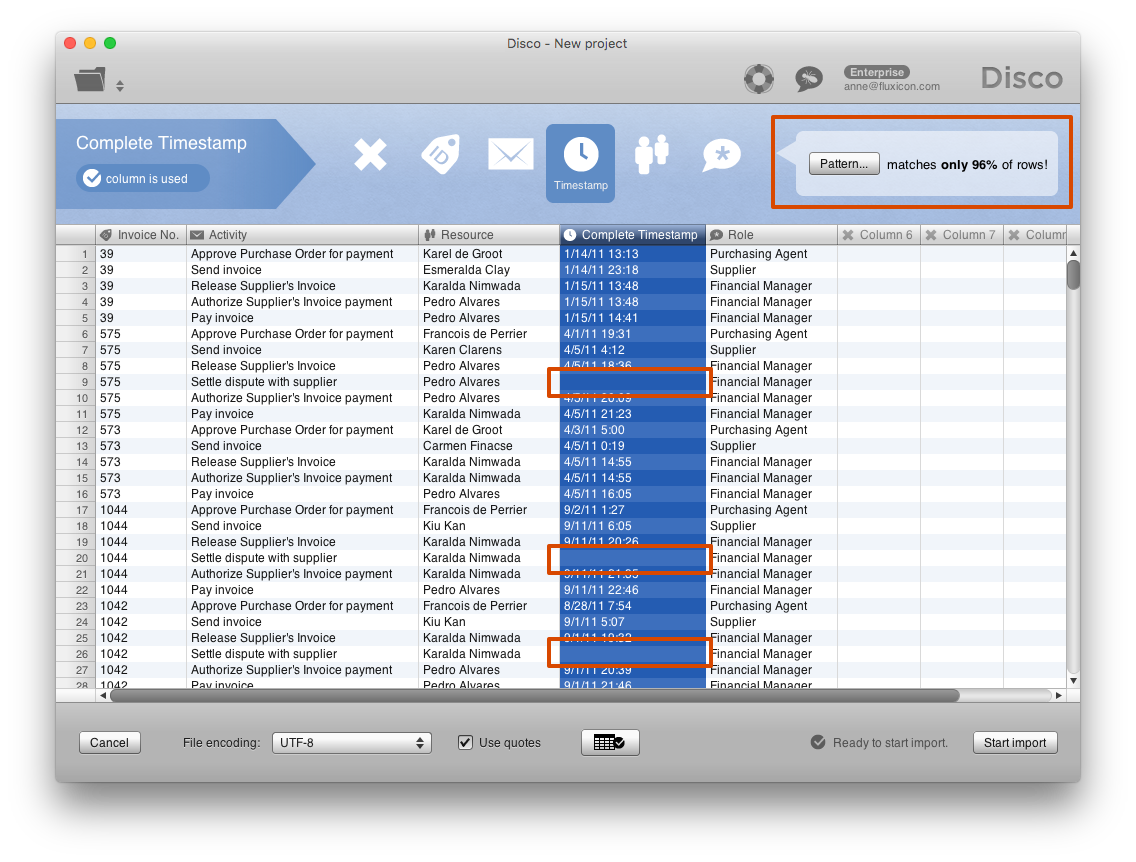
When you go ahead and import the data anyway, Disco will import only the events that have a timestamp (and sort them based on the timestamps to determine the event sequence for each case). As a result, you get a process map without the Settle dispute with supplier activity (see screenshot below). You can now fully analyze your process also from the performance perspective, but you have a blind spot (similarly to the example scenario discussed at the beginning of the article).
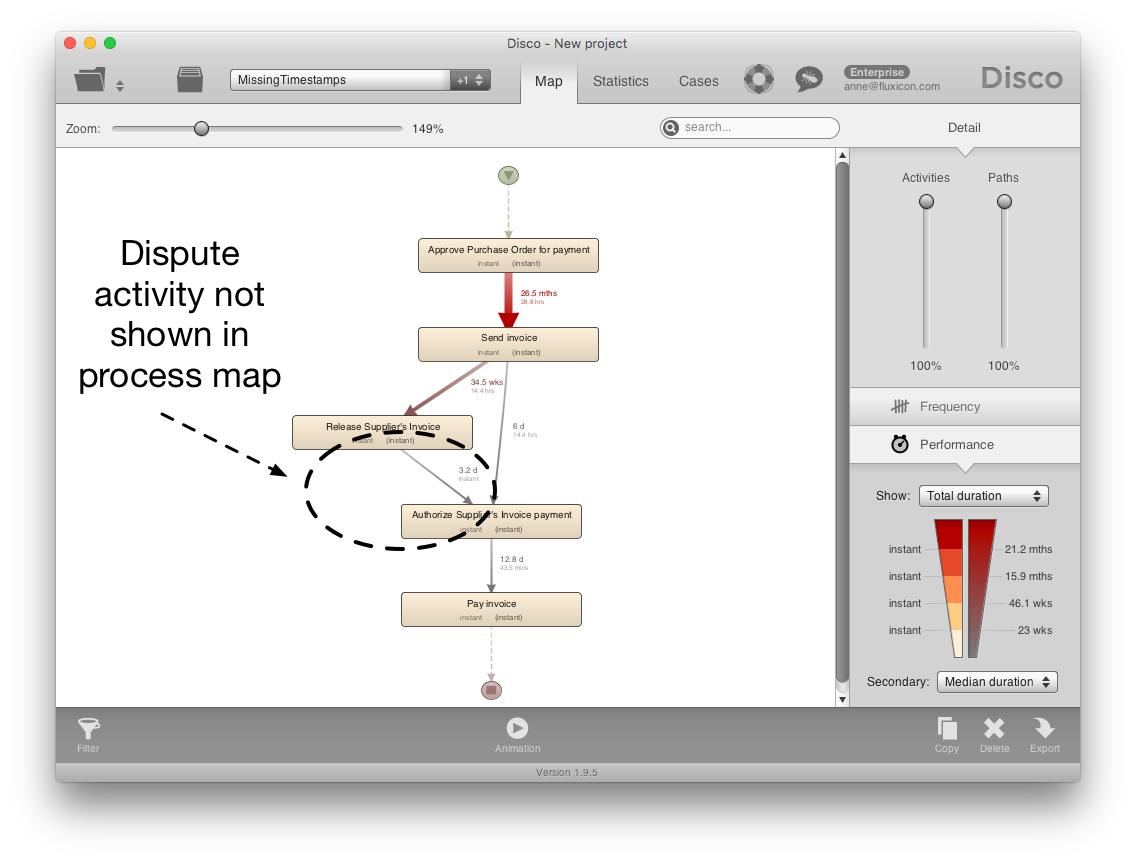
Let’s say we now want to include the Settle dispute with supplier activity in our process map. For example, we would like to visualize how many cases have a dispute in the first place.
To do this, we import the data again but make sure that no column is configured as a Timestamp in the import screen. For example, we can change the configuration of the ‘Complete Timestamp’ column to an Attribute (see screenshot below). As a result, you will see a warning that no timestamp column has been defined, but you can still import the data. Disco will now use the order of the events in the original file to determine the activity sequences for each case. You should only use this option if the activities are already sorted correctly in your data set.

As a result, the Settle dispute with supplier activity is now displayed in the process map (see screenshot below). We can see that 80 out of 412 cases went through a dispute in the process.
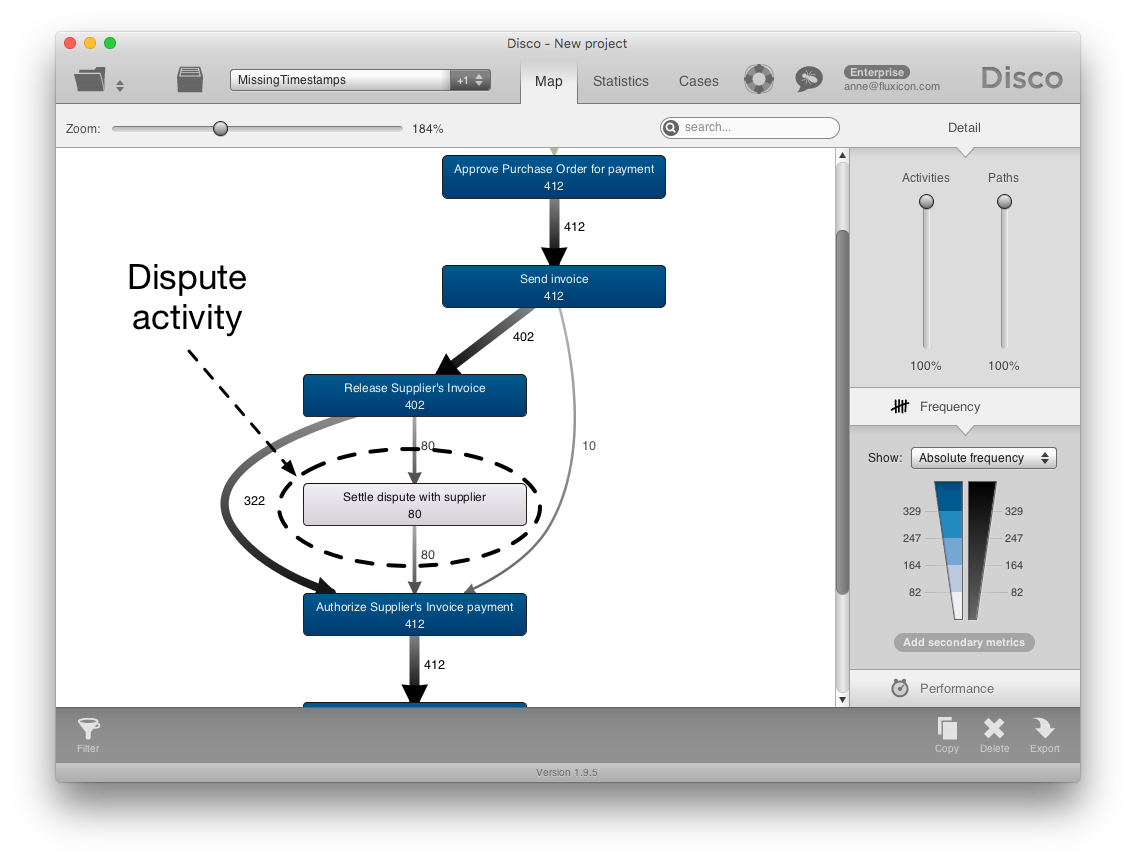
We can further analyze the process map along with the variants, the number of steps in the process, etc. However, because we have not imported any timestamps, we will not be able to analyze the performance of the process, for example, the case durations or the waiting times in the process map.
To analyze the process performance, and to keep the activities without timestamps in the process map at the same time, you will have to add timestamps for the events that currently don’t have one in your data preparation.

Anne Rozinat
Market, customers, and everything else
Anne knows how to mine a process like no other. She has conducted a large number of process mining projects with companies such as Philips Healthcare, Océ, ASML, Philips Consumer Lifestyle, and many others.