Detect and Fix Data Quality Problems¶
Data for process mining can come from many different places. One of the big advantages of process mining is that it is not specific to some kind of system. Any workflow or ticketing system, ERPs, data warehouses, click-streams, legacy systems, and even data that was collected manually in Excel, can be analyzed as long as a Case ID, an Activity name, and a Timestamp column can be identified (see Data Requirements).
But most of that data was not originally collected for process mining purposes. And especially data that has been manually entered can always contain errors. How do you make sure that errors in the data will not jeopardize your analysis results?
Data quality is an important topic for any data analysis technique: If you base your analysis results on data, then you have to make sure that the data is sound and correct. Otherwise, your results will be wrong! If you show your analysis results to a business user and they turn out to be incorrect due to some data problems, then you can lose their trust into process mining forever.
While most of the general data quality challenges apply, there are some data quality challenges that are specific to process mining [Suriadi] [Bose]. Many of these challenges revolve around problems with timestamps. In fact, you could say that timestamps are the Achilles heel of data quality in process mining. But timestamps are not the only problem.
In this chapter, we will show you the data quality problems that you will most commonly encounter in practice and how to address them. We will also give you a checklist that can guide you through the data validation process.
What you will learn:
- Why a dedicated data validation step is crucial for your process mining project.
- What the most common data quality problems are and how you can fix them.
Data Quality Checklist¶
Use the following checklist as a guide to assess the quality of your data. Even if you think your data is correct, you can run through the checklist to make sure you are right. You can also download this PDF version to print it out and check off each point.
| Nr. | Question | Description |
|---|---|---|
| 1 | No errors during import? | The very first check is to make sure that there are no error messages when you import your data set. Error messages can have different root causes, such as Formatting Errors or Missing Timestamps. In some situations, you may want to deliberately induce errors to clean a data quality problem that would otherwise go unnoticed (see Missing Complete Timestamps For Ongoing Activities). |
| 2 | No gaps in the timeline? | Verify that there are no unnaturally empty spots along the log timeline in your ‘Events over time’ chart (see Gaps in the timeline). This would indicate that you are missing a bunch of data. |
| 3 | Expected amount of data? | Then, check whether the number of events and the number of cases that were imported correspond to the amount of data that you expected (see Unexpected amount of data). |
| 4 | Expected distribution of attribute values? No unexpected empty values? | After checking the volume of the data, take a look at the attributes and their attribute statistics. See if the distribution seems right and if there are unexpected empty values (see Missing Attribute Values). Furthermore, inspect some example cases and verify that the attribute values are correct in their temporal context (see Missing Attribute History). |
| 5 | No cases with unexpected number of steps? | If case IDs are overloaded or missing, events that belong to different cases may be grouped into one case. You need to clean such cases from your data set (see Missing Case IDs). |
| 6 | Expected timeframe? No unexpected long throughput times? | You have requested the data set for a certain timeframe. Check the earliest and the latest timestamp to see if you have any Zero Timestamps (e.g., 1900, 1970 and 2999). |
| 7 | No unexpected ordering of sample cases? No unexpected flows in the process map? | Wrong timestamps mess with the ordering relationships of your process and there can be many different reasons for why they are wrong. Read all of the following examples to know what you should look out for: Missing Activities, Missing Timestamps For Activity Repetitions, Wrong Timestamp Pattern Configuration, Same Timestamp Activities, Different Timestamp Granularities, Unwanted Parallelism, Wrong Timestamp Column Configuration, Recorded Timestamps Do Not Reflect Actual Time of Activities, and Different Clocks. |
| 8 | Data validation session with domain expert done? | You will do all the checks 1-7 on this list for yourself at first. However, before you move to the analysis phase, it is really important that you also check the data quality with a domain expert (see Data Validation Session). |
| 9 | Documented all quality issues and data questions? | Throughout the data validation process, write down all the problems, limitations, and questions that emerge as soon as you encounter them. You can download this worksheet as a starting point. |
| 10 | If you had to exclude data due to data quality problems, is the remaining data set still representative? | Keep track which of your original process questions may be affected by the data quality issues that you found. Can certain questions not be answered, because the data is not good enough? Furthermore, be mindful of the amount of data that you remove during the data cleaning steps: After you have fixed all your data quality problems, compare the remaining amount of cases with the initial data set and decide whether this data basis is sufficient for your analysis. |
Can you answer “Yes” to all of the points above? Then you can move to the next phase of preparing your analysis: Deal With Incomplete Cases.
Data Validation Session¶
A common and unfortunate process mining scenario goes like this: You present a process problem that you have found in your process mining analysis to a group of process managers. They look at your process map and point out that this can’t be true. You dig into the data and find out that, actually, a data quality problem was the cause for the process pattern that you discovered.
The problem with this scenario is that, even if you then go and fix the data quality problem, the trust that you have lost on the business side can often not be won back. They won’t trust your future results either, because “the data is all wrong”. That’s a pity, because there could have been great opportunities in analyzing and improving this process!
To avoid this, we recommend to plan a dedicated data validation session with a process or domain expert before you start the actual analysis phase in your project. To manage expectations, communicate that the purpose of the session is explicitly not yet to analyze the process, but to ensure that the data quality is good before you proceed with the analysis itself.
You can ask both a domain expert and a data expert to participate in the session, but especially the input of the domain expert is needed here, because you want to spot problems in the data from the perspective of the process owner for whom you are performing the analysis (you can book a separate meeting with a data expert to walk through your data questions later). Ideally, your domain expert has access to the operational system during the session, so that you can look up individual cases together if needed.
To organize the data validation session with the domain expert, you can do the following:
- Start by explaining briefly what process mining is. Show up to a maximum of 5 slides and consider giving a very short demo with a clean and simple example. Unless they have recently participated in a presentation about process mining, you should assume that they either do not know what process mining is at all or only have a vague idea.
- Then, restate the purpose of the session and explain that you want to validate the data with them and collect potential issues and questions on the way.
- Consider asking them to draw a very simple process map (just boxes and arrows) of the process from their perspective with up to a maximum of 7 steps at a flip-chart or whiteboard. This will be useful as a reference point, when you are trying to understand the meaning of certain process steps later on in the meeting.
- Show them the data in raw format (for example, in Excel) and explain where you got the data and how it was extracted. Point out the Case ID, Activity, and Timestamp columns that you are using.
- Then, import the data in front of their eyes and go over the summary information (showing the timeframe of the data, the attributes, etc.). Afterwards, look at the process map and inspect the top variants with them. Look at some example cases and ask them: “Does this make sense to you?”. Write down any issues that they mention.
- If you find strange patterns in the process behavior, filter the data to get to some example cases for further context. Simplify the process map if needed (see Simplify Complex Process Maps) and interactively look into the issues that you find together. Try to find answers to questions right in the session if possible and otherwise write them up as an action point.
- If you can, look up a few cases in the operational system together (many systems allow you to search by case number, or customer number, to inspect the history of an individual case) and compare them with the case sequences that you find in Disco to see whether they match up as expected.
- Of course, you may have already run into questions yourself while going through the data quality checklist (see Data Quality Checklist) before this data validation session. You can go through them with the domain expert to see whether they have some explanations for the problems that you have observed.
You may find that the domain expert brings up questions about the process that are relevant for the analysis itself. This is great and you should write them down, but do not get side-tracked by the analysis and steer the session back to your data quality questions to make sure you achieve the goal of this meeting: To validate the data quality and uncover any issues with the data that might need to be cleaned up.
After the validation session, follow-up on all of the discovered data problems and investigate them. Document the actions that you have taken, or intend to take, to fix them.
The only excuse not to do a data validation session with a domain expert is if you yourself are a domain expert for the process that you are analyzing.
Formatting Errors¶
A first check is to pay attention to any errors that you get during the import step. In many situations, errors stem from improperly formatted CSV files, because writing good CSV files is harder than you might think [TBurette].
For example, the delimiting character (“,” “;” “I” etc.) cannot be used in the content of a field without proper escaping. If you look at the example snippet below then you can see that the “,” delimiter has been used to separate the columns. However, in the last row the activity name itself contains a comma:
Case ID, Activity
case1, Register claim
case1, Check
case1, File report, notify customer
Proper CSV requires that the “File report, notify customer” activity is enclosed in quotes to indicate that the “,” is part of the activity name:
Case ID, Activity
case1, Register claim
case1, Check
case1, "File report, notify customer"
Another problem might be that your file has less columns in some rows compared to others (see an example in Figure 1).

Figure 1: Missing cell notifications show up when some lines have fewer columns than others.
Other typical problems are invalid characters, quotes that open but do not close, and there are many more.
If Disco encounters a formatting problem, it gives you the following error message with the sad triangle and also tries to indicate in which line the problem occurs (see Figure 2).

Figure 2: Disco tries to tell you in which line the formatting error was encountered.
In most cases, Disco will still import your data and you can take a first look at it, but make sure to go back and investigate the problem before you continue with any serious analysis.
We recommend to open the file in a text editor and look around the indicated line number (a bit before and afterwards, too) to see whether you can identify the root cause.
Note
How to fix:
Occasionally, the formatting problems have no impact on your data (for example, an extra comma at the end of some of the lines in your file). Or the number of lines impacted are so few that you choose to ignore it. But in most cases you do need to fix it.
Sometimes, it is enough to use “Find and Replace” in Excel to replace a delimiting character from the content of your cells and export a new, cleaned CSV that you then import.
However, in most cases it will be the easiest to point out the problem that you found to the person who extracted the data for you and ask them to give you a new file that avoids the problem.
Missing Events¶
Even if your data imported without any errors, there may still be problems with the data. For example, one typical problem is missing data. One type of missing data that you might encounter is missing events.
You can identify missing events in two ways.
Gaps in the timeline¶
Check the timeline in the ‘Events over time’ chart (see Overview Statistics) to verify that there are no unusual gaps in the amount of events that occur over your log timeframe.

Figure 3: Gaps in the timeline typically indicate that something is wrong.
Figure 3 shows an example, where we had concatenated three separate files into one file before importing it in Disco. Clearly, something went wrong and apparently the whole data from the second file is missing.
Note
How to fix:
If you made a mistake in the data pre-processing step, you can go back and make sure you include all the data there.
If you have received the data from someone else, you need to go back to that person and ask them to fix it.
If you have no way of obtaining new data, it is best to focus on an uninterrupted part of the data set (in the example above, that would be just the first or just the third part of the data). You can do that using the Timeframe Filter in Disco.
Unexpected amount of data¶
You should have an idea about (roughly) how many rows or cases of data you are importing. Take a look at the Overview Statistics to see whether they match up with what you expect.
For example, Figure 4 shows a screenshot of the overview statistics from the BPI Challenge 2013 data set [BPI13]. Can you see anything that might be wrong with it?
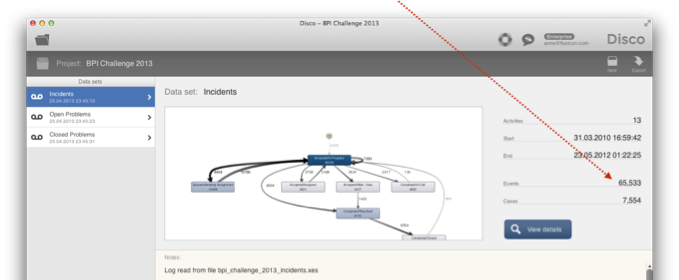
Figure 4: Check whether the number of events and cases matches your expectations for the data set.
In fact, the total number of events is suspiciously close to the old Excel limit of 65,000 rows. And this is what happened: In one of the data preparation steps, the data (which had several hundred thousand rows) was opened with an old Excel version and saved again.
Of course, this is a bit more subtle than an obvious gap in the timeline but missing data can have all kinds of reasons. For some systems or databases, a large data extract is aborted half-way without anyone noticing. That’s why it is a very good idea to have a sense of how much data you are expecting before you start with the import (ask the person that gives you the data how they structured their query).
Note
How to fix:
If you miss data, you must find out whether you lost it in a data pre-processing step or in the data extraction phase.
If you have received the data from someone else, you need to go back to that person and ask them to fix it.
If you have no way of obtaining new data, try to get a good overview about which part of the data you got. Is it random? Was the data sorted and you got the first X rows? How does this impact your analysis possibilities? Some of the BPI Challenge submissions [BPI13W] noticed that something was strange and analyzed the data pattern to better understand what was missing.
Missing Attribute Values¶
Similarly, you should have an idea of the kind of attributes that you expect in your data. Did you request the data for all call center service requests for the Netherlands, Germany, and France from one month, but the volumes suggest that the data you got is mostly from the Netherlands?
Another example to watch out for are empty values in your attributes. For example, the resource attribute statistics in Figure 5 show that 23% of the steps have no resource attached at all.

Figure 5: Check whether the values of your data attributes are sufficiently filled.
Empty values can also be normal. Talk to a process domain expert and someone who knows the information system to understand the meaning of the missing values in your situation.
Note
How to fix:
If you have unexpected distributions, this could be a hint that you are missing data and you should go back to the pre-processing and extraction steps to find out why.
If you have empty attribute values, often these values are really missing and were never recorded in the first place. Make sure you understand how these missing (or unexpectedly distributed) attribute values impact your analysis possibilities. You may come to the conclusion that you cannot use a particular attribute for your analysis because of these quality problems.
It is not uncommon to discover data quality issues in your original data source during the process mining analysis, because nobody may have looked at that data the way you do. By showing the potential benefits of analyzing the data, you are creating an incentive for improving the data quality (and, therefore, increasing the analysis possibilities) over time.
Missing Attribute History¶
Even if there are no Missing Attribute Values, you might be missing the history information for these attributes. For example, take a look at the data set in Figure 6, where the ‘Resource’ column does not change over the course of the whole case.

Figure 6: If the values of a particular attribute never change over the course of the whole case, you might be missing the history for this attribute in your data.
Instead of the person who performed a particular process step, here the ‘Resource’ field most likely indicates the employee that started the case, who is responsible for it, or the person that last performed a step in the process.
The same can happen with a data field, like the ‘Category’ attribute in Figure 6. You might know that the field can change over time but in your data set you only see the last (the current) value of it.
Note
How to fix:
If you can’t get the historical information on this field, request a data dictionary from the IT administrator to understand the meaning of the field, so that you can interpret it correctly. For example, is the resource that is associated with the case the person who initially created the order? Or is it the last person that worked on the case?
Realize that you cannot perform process flow analyses with this attribute (for example, no social network analysis will be possible based on the resource field in the example above). You can still use these fields in your analysis as a case-level attribute.
Sometimes, the missing history information on attributes can be even trickier to detect. For example, take a look at the data set in Figure 7.
We see that the registration of the step ‘Shipment via forwarding company’ in case C360 was performed by a ‘Service Clerk’ role - See (1) in Figure 7. However, for case C1254 the same step was performed by a ‘Service Manager’ role, which if we know the process might strike us as odd - See (2) in Figure 7.

Figure 7: It seems as if Elvira performed the step ‘Shipment via forwarding company’ for case C1254 with the role of a ‘Service Manager’. In reality, she was a ‘Service Clerk’ back in 2011 but the role attribute that was derived to enrich the order history data set only contains her current role information.
If we look deeper into the problem, then we find out that the ‘Role’ information was actually extracted from a separate database and linked to our order history data later on. However, the ‘Role’ information that we used to enrich the history data set was based on the roles of the employees today.
In 2011, when case C1254 was performed, Elvira Lores still was a ‘Service Clerk’. But by 2013, when case C360 was performed, Elvira had become a ‘Service Manager’ - See (3) in Figure 7. However, we can’t see that Elvira performed the step ‘Shipment via forwarding company’ back then in the role of a ‘Service Clerk’ because we only have her current role information!
Note
How to fix:
There is typically not much that you can do about this in the short term. You can try to request a new data set that contains the historical role information but perhaps that data is not available in your organization.
It is normal that you encounter limitations in your data set and in the first step you typically try to use the data that you have. The most important part is that you are aware of the data limitations, so that you can interpret your analysis results correctly.
Missing Case IDs¶
As a next check, you should look out for cases with a very high number of steps. For example, in Figure 8, the callcenter data from the Disco demo logs was imported with the Customer ID configured as the case ID (see also Focus on Another Case).
What you find is that while a total of 3231 customer cases had up to a maximum of 30 steps, there is this one case (Customer 3) that had a total of 583 steps in total over a timeframe of two months. That cannot be quite right, can it?

Figure 8: Check whether there are cases with an impossible number of steps.
To investigate this further, you can right-click the case ID in the table and select the “Show case details” option (see Figure 9).

Figure 9: Right-click on the case that you find suspiciously to investigate it further.
This will bring up The Cases View with that particular case shown (see Figure 10). It turns out that there were a lot of short inbound calls coming in rapid intervals.
The consultation with a domain expert confirms that this is not a real customer, but some kind of default or “dummy” customer ID that is assigned by the callcenter agent if no customer was created or associated with a case. In fact, the Siebel CRM system required the agent to always enter a customer ID. So, in situations where this is not possible (for example, because the customer hung up before the agent could capture their contact information) the agents were entering the dummy customer ID.

Figure 10: You can then look at the example case to understand whether this is a real case or just a missing case ID quality issue.
Although in this data set there is technically a case ID associated (before anonymizing the customer IDs the number even had exactly the same alpha numeric format and was indistinguishable from all the regular customer IDs), this dummy case ID is really an example of missing data. The real cases (the actual customers that called) are not captured.
This will have an impact on your analysis. For example, analyzing the average number of steps per customer with this dummy customer in it will give you wrong results. You will encounter similar problems if the case ID field is empty for some of your events (they will all be grouped into one case with the ID “empty”).
Note
How to fix:
You can simply remove the cases with such a large number of steps in Disco (see Figure 11). Make sure you keep track of how many events you are removing from the data and how representative your remaining dataset still is after doing that.
To remove the “Customer 3” case from the callcenter data above, you can right-click the case in the overview statistics and select the Filter for case ‘Customer 3’ option. [1]

Figure 11: Right-click on the case that you want to remove.
In the pre-configured Attribute Filter, you can then invert the selection (see the little Yin Yang button in the upper right corner) to exclude Customer 3. To create a new reference point for your cleaned data, you can tick the ‘Apply filters permanently’ option after pressing the ‘Copy and filter’ button as shown in Figure 12.

Figure 12: De-select the case ID that you want to remove from your data set.
The result will be a new log with the very long case removed and the filter permanently applied (see Figure 13).

Figure 13: You have now cleaned your data set from the case that has grouped the missing case IDs.
Missing Activities¶
Some activities in your process may not be recorded in the data. For example, there may be manual activities (like a phone call) that people perform at their desk. These activities occur in the process but are not visible in the data.
Of course, the process map that you discover using process mining will not show you these manual activities. What you will see is a path from the activity that happened before the manual activity to the activity that happened after the manual activity.
For example, in the process map in Figure 14 there is a path from activity ‘Create Request for Quotation’ to ‘Analyze Request for Quotation’ that, on average, takes 21.7 days. However, it could be that there was actually another activity that took place between these two process steps, which is not visible in the data.

Figure 14: Manual activities need to be taken into account in the interpretation of your process map.
Note
How to fix:
There is not much you can do here. What is important is to be aware that these activities take place although you cannot see them in the data. Process mining mining cannot be performed without proper domain knowledge about the process you are analyzing. Make sure you talk to the people working in the process to understand what is happening.
You can then take this domain knowledge into account when you interpret your results. For example, in the process above you would know that not all the 21.7 days are actually idle time in the process. Instead, you know that other activities are taking place in between, but you can’t see them in the data. It’s like a blind spot in your process. Typically, with the proper interpretation you are just fine and can complete your analysis based on the data that you have.
However, sometimes the blind spot becomes a problem. For example, you might find that your biggest bottlenecks are in this blind spot and you really need to understand more about what happens there. In this situation, you may choose to go back and collect some manual data about this part of the process either through observation or by asking the employees to document their manual activities for a few weeks. Make sure to record the case ID along with the activities and the timestamps in this endeavor. Afterwards, you can combine the manually collected data with the IT data to analyze the full process, but now with full visibility on the blind spot.
Missing Timestamps¶
In some situations, you may have information about whether or not an activity has occurred but you simply don’t have a timestamp.
For example, take a look at the data snippet from an invoice handling process in Figure 15. We can see that in some of the cases an activity ‘Settle dispute with supplier’ was performed. In contrast to all the other activities, this activity has no timestamp associated. It simply might not have been recorded by the system, or the information about this activity comes from a different system.

Figure 15: The activity ‘Settle dispute with supplier’ has no timestamp.
The problem with a data set where some events have a timestamp and others don’t is that the process mining tool cannot infer the sequence of the activities, because, normally, the events are ordered based on the timestamps during the import of the data. So, what can you do?
There are essentially three options.
Note
How to fix:
- Ignore the events that have no timestamp. This will allow you to analyze the performance of your process but omit all activities that have no timestamp associated (see example below).
- Import your data without a timestamp configuration. This will import all events based on the order of the activities from the original file. You will see all activities in the process map, but you will not be able to analyze the waiting times in the process (see example below).
- You can “borrow” the timestamps of a neighbouring activity and re-use them for the events that do not have any timestamps (for example, the timestamp of their predecessor or successor activity). This data pre-processing step will allow you to import all events and include all activities in the process map. At the same time, it preserves the possibility to analyze the performance of your process as well. Be very careful about this and only do it if you can be sufficiently sure that you have enough information about the process to artificially add these timestamps.
If you want to use your data without further pre-processing, here is what option No. 1 and No. 2 look like based on the example above.
Ignore the events that have no timestamp¶
First, we can import the data set in the normal way. When the timestamp column is selected, Disco gives you a warning that the timestamp pattern is not matching all rows in the data (see Figure 16). The reason for this mismatch are the empty timestamp fields of the ‘Settle dispute with supplier’ activity.

Figure 16: Disco warns you that some of the values cannot be recognized as a timestamp.
When you go ahead and import the data anyway, Disco will import only the events that have a timestamp (and sort them based on the timestamps to determine the event sequence for each case). You will see an error message as shown in Figure 17 that lets you know that not all of the events could be imported because their timestamps could not be recognized.

Figure 17: An error message lets you know that some of the events could not be imported because their timestamp could not be recognized.
After importing the data, you get a process map without the Settle dispute with supplier activity (see Figure 18). You can now fully analyze your process also from the performance perspective, because you have included the timestamp information during import, but you have a blind spot (similarly to the example scenario discussed in Missing Activities).

Figure 18: The activities that have no timestamp will not be shown in the process map, but you can analyze your process from a performance perspective.
Import your data without a timestamp configuration¶
Now let’s say that we do want to include the ‘Settle dispute with supplier’ activity in our process map. For example, we would like to visualize how many cases have a dispute in the first place.
To do this, we import the data again but make sure that no column is configured as a Timestamp column in the import screen. For example, we can change the configuration of the ‘Complete Timestamp’ column to an Attribute (see Figure 19) or we can exclude it completely.
In the lower right corner, you will see a warning that no timestamp column has been defined, but you can still import the data. Disco will now use the order of the events in the original file to determine the activity sequences for each case. You should only use this approach if the activities are already sorted correctly in your data set.

Figure 19: Even though Disco shows you a warning that no Timestamp column has been configured, you can import your data without a timestamp and the sequence of the events in the original file will be used to sort the activities in each case.
As a result, the ‘Settle dispute with supplier’ activity is now displayed in the process map (see Figure 20). We can see that 80 out of 412 cases went through a dispute in the process.

Figure 20: The activity without timestamps is now shown in the process map.
We can further analyze the process map along with the variants, the number of steps in the process, etc. However, because we have not imported any timestamps, we will not be able to analyze the performance of the process, for example, the case durations or the waiting times in the process map.
To analyze the process performance and to keep the activities without timestamps in the process map at the same time, you will have to add timestamps for the events that currently don’t have one in your data preparation (see option No. 3 above in the ‘How to fix’ section).
Missing Timestamps For Activity Repetitions¶
This is a common data quality problem that we are sure most of you will encounter at some point in time in the future.
Take a look at the data snippet in Figure 21. In this data set, you can see three cases (Case ID 1, Case ID 2, and Case ID 3). If you compare this data set with a typical process mining data set (see Data Requirements), you can see the following differences:
- There is just one row per case (see case 1 highlighted). Normally, you would have multiple rows — One row for each event in the case.
- The activities are in columns (here, activity A, B, C, D and E), with the dates or timestamps recorded in the cell content.

Figure 21: If a data set is formatted in one row per case, you should be alerted that you probably lack information on activity repetitions.
When you encounter such a data set, you will have to re-format it into the process mining format in the following way (see Figure 22): [2]
- Add a rows for each activity (again, case 1 is highlighted).
- Create an activity and a timestamp column to capture the name and the time for each activity.

Figure 22: You will need to reformat this data set transpose the columns into rows, but that’s not the only problem.
However, the important thing to realize here is that this is not purely a formatting problem. The column-based format is not suitable to capture event data about your process, because it inherently loses information about activity repetitions.
For example, imagine that after performing process step D the employee realizes that some information is missing. They need to go back to step C to capture the missing information and will only then continue with the proces step E. The problem with the column-based format as shown in the first data snippet is that there is no place where these two timestamps regarding activity C can be captured. So, what happens in most situations is that the first timestamp of activity C is simply overwritten and only the latest timestamp of activity C is stored.
You might wonder why people store process data in this column-based format in the first place. Typically, you find this kind of data in places, where process data has been aggregated. For example, in a data warehouse, BI system, or an Excel report. It’s tempting, because in this format it seems easy to measure process KPIs. For example, do you want to know how long it takes between process step B and E? Simply add a formula in Excel to calculate the difference between the two timestamps. [3]
People often implicitly assume that the process goes through the activities A-E in an orderly fashion. But processes are really complex and messy in reality. As long as the process isn’t fully automated, there is going to be some rework. And by pressing your data in such a column-based format you lose information about the real process.
So what can you do if you encounter your data in such a column-based format?
Note
How to fix:
First of all, you should use the data that you have and transform it into a row-based format like shown above. However, in the analysis you need to be aware about the limitation of the data and know that you can encounter some distortions in the process because of it (see an example below).
If the process is important enough, you might want to go back in the next iteration and find out where the original data that was aggregated in the BI tool or Excel report comes from. For example, it might come from an underlying workflow system. You can then get the full history data from the original system to fully analyze the process with all its repetitions.
To understand what kind of distortions you can encounter, let’s take a look at the data set in Figure 23, which shows the steps that actually happened in the real process before the data was aggregated into columns. You can see that:
- Only case 2 followed the expected path A-E.
- In case 1 and in case 3 rework occurred that is simply lost in the column-based, and then the transformed, data set (see blue mark-up).

Figure 23: The bigger problem is that you most likely lost information on any repetitions (or loops) that might have occurred for the activities in the process.
Now, when you first import the data set that was transformed from the column-based format to the row-based format into Disco, you get the simplified process map (refer to Simplify Complex Process Maps to learn more about how to simplify complex processes) shown in Figure 24.

Figure 24: This leads to distortions in the process map. Here is the process map from the transposed data set. It appears as if, at least once, activity B was directly followed by activity D…
The problem is that if a domain expert would look at this process map, they might see some strange and perhaps even impossible process flows due to the distortions from the lost activity repetition timestamps. For example, in the process map above it looks like there was a direct path from activity B to activity D at least once.
However, in reality this never happened. You can see the discovered process map from the real data set (where all the activity repetitions are captured) in Figure 25. There was never a direct succession of the process steps B and D, because in reality activity C happened in between.

Figure 25: … while in reality this never happened.
So, use the data that you have but be aware that such distortions can happen and what is causing them. If you go through another iteration for this process analysis, then try to get the underlying data that includes the history of the activity repetitions to get the full picture.
Missing Complete Timestamps For Ongoing Activities¶
If you have ‘start’ and ‘complete’ timestamps in your data set (see also Including Multiple Timestamp Columns), then you can sometimes encounter situations, where the ‘complete’ timestamp is missing for those activities that are currently still running.
For example, take a look at the data snippet below (see Figure 26). Two process steps were performed for case ID 1938. The second activity that was recorded for this case is ‘Analyze Purchase Requisition’. It has a ‘start’ timestamp but the ‘complete’ timestamp is empty, because the activity has not yet completed (it is ongoing).

Figure 26: Sometimes, the ‘complete’ timestamp is missing because the activity has not finished yet.
In principle, this is not a big problem. After importing the data set, you can simply analyze the process map and the variants, etc., as you would usually do. When you look at a concrete case, then the activity duration for the activities that have not completed yet is shown as “instant” (see the history for case ID 1938 in Figure 27).

Figure 27: An activity that has only timestamp has a duration of zero.
However, where this does become a problem is when you analyze the activity duration statistics (see Figure 27). The “instant” activity durations influence the mean and the median duration of the activity. So, you want to remove those activities that are still ongoing from the calculation of the activity duration statistics.

Figure 28: The problem is that the activity duration statistics are distorted.
Note
How to fix:
- Import your data set again and only configure the complete timestamp as a ‘Timestamp’ column (keep the start timestamp column as an attribute via the ‘Other’ configuration). This will remove all events, where the complete timestamp is missing.
- Export your data set as a CSV file and import it again into Disco, now with both the start and the complete timestamp columns configured as ‘Timestamp’ column.
Your activity duration statistics will now only be based on those activities that actually have both a start and a complete timestamp.
Zero Timestamps (e.g., 1900, 1970 and 2999)¶
Another data problem that you will most certainly encounter at some point in time are so-called “zero timestamps”. Zero timestamps are default timestamps that were assigned by the IT system by mistake or for a different reason. Often, zero timestamps were initially set as an empty value by the programmer of the information system. They can either be a typo from manually entered data or they might indicate that the real timestamp has not yet been provided (for example, because an expected process step has not happened yet).
These Zero timestamps typically take the form of 1 January 1900, the Unix epoch timestamp 1 January 1970, or some future timestamp (like 2100 or 2999). If you don’t take care of zero timestamps, you can easily get case durations of more than 100 years!
To find out whether you have Zero timestamps in your data, you can best go to the Overview Statistics and take a look at the earliest and the latest timestamps in the data set. For example, in the screenshot in Figure 29 we can see that there is at least one 1900 timestamp in the imported data.

Figure 29: Check the earliest and the latest timestamp in the Overview Statistics to see if you have any zero timestamps.
Faulty timestamps do not only influence the case durations. They also impact the variants and the process maps themselves, because the order of the activities is derived based on the timestamps.
For example, take a look at the following data set with just one zero timestamp. There is one case with a 1970 timestamp (see Figure 30). As a result, the ‘Create case’ activity is positioned before the ‘Import forms’ activity.

Figure 30: Faulty timestamps influence the case sequences and variants.
If we look at the process map (see Figure 31), then you see that in all other 456 cases the process flows the other way. Clearly, the reverse sequence is caused by the 1970 timestamp.

Figure 31: This wrong order will show up in the process map flows…
And if we look at the average waiting times in the process map, then this one faulty timestamp creates further problems and shows a huge delay of 43 years (see Figure 32).

Figure 32: … and in the performance metrics in the process map.
To protect yourself against zero timestamps, you should know what timeframe you are expecting for your data set and then verify that the earliest and latest timestamp confirm the expected time period. Be aware that if you do not address a problem like the 1900 timestamp in Figure 29, then you may end up with case durations of more than 100 years!
Note
How to fix:
You can remove Zero timestamps using the Timeframe filter in Disco (see instructions below).
You may also want to communicate your findings back to the system administrator to find out how these Zero timestamps can be avoided in the future.
To understand the impact of the Zero timestamps, you first need to investigate in more detail what is going on.
First: Investigate¶
You want to find out whether just a few cases are affected by the Zero timestamps, or whether this is a wide-spread problem. For example, if Zero timestamps are recorded in the system for all activities that have not happened yet, you will see them in all open cases.
To investigate the cases that have Zero timestamps, add a Timeframe Filter and use the ‘Intersecting timeframe’ mode while focusing on the problematic time period. This will keep all those cases that contain at least one Zero timestamp. Then use the ‘Copy and filter’ button to create a new data set focusing on the Zero timestamp cases (see Figure 33).

Figure 33: First, investigate how many cases are impacted by the zero timestamps (and why).
As a result, you will see just the cases that have Zero timestamps in them. You can see how many there are. Furthermore, you can inspect a few example cases to see whether the problem is always in the same place or whether multiple activities are affected. In our example, just two cases contain Zero timestamps (see Figure 34).

Figure 34: In this data set, only two cases are impacted.
Now, let’s move on to fix the Zero timestamp problem in the data set.
Then: Remove cases or Zero timestamps only¶
Depending on whether Zero timestamps are a wide-spread problem or not you can take two different actions:
- If only a few cases are affected, you can best remove these cases altogether. This way, they will not disturb your analysis. At the same time you will not be left with partial cases that miss some activities because of data quality issues.
- If many cases are affected, like in the situation that Zero timestamps were recorded for activities that have not happened yet, you can better remove just the events that have Zero timestamps and keep the rest of the events from these cases for your analysis.
In our example, just two cases are affected and we will remove these cases altogether. To do this, add a Timeframe Filter and choose the ‘Contained in timeframe’ option while focusing your selection on the expected timeframe. This will remove all cases that have any events outside the chosen timeframe (see Figure 35).

Figure 35: To remove all impacted cases, use the ‘Contained in timeframe’ option of the Timeframe Filter.
If you just want to remove the activities that have Zero timestamps, choose the ‘Trim to timeframe’ option instead. This will “cut off” all events outside of the chosen timeframe and keep the rest of these cases in your data (see Figure 36).

Figure 36: To only remove the impacted events, use the ‘Trim to timeframe’ option of the Timeframe Filter.
Note that if your Zero timestamps indicate that certain activities have not happened yet, it would be better to keep the timestamp cells in the source data empty, rather than filling in a 1900 or 1970 timestamp value (see Figure 37).

Figure 37: If your zero timestamps indicate that an activity has not happened yet, it would be better to keep the cell for these activities empty in the future.
Events with empty timestamps will not be imported in Disco, because they cannot be placed in the sequence of activities for the case (see Figure 17). So, if you have some influence on how the data set is created then keeping the timestamp cell empty for activities that have not occurred yet will save you this extra clean-up step in the future.
Wrong Timestamp Pattern Configuration¶
When you import a CSV or Excel file into Disco, the timestamp pattern is normally detected automatically. You don’t have to do anything. If it is not automatically detected, then Disco lets you specify how the timestamp pattern should be interpreted rather than forcing you to convert your source data into a fixed timestamp format. And you can even work with different timestamp patterns in your data set (see Different Timestamp Patterns?).
However, if you have found that activities show up in the wrong order, or if you find that your process map looks weird and does not really show the expected process, then it is worth verifying that the timestamps are correctly configured during import. [4]
You can do that by going back to the import screen: Either click on the ‘Reload’ button from the project view or import your data again. Then, select the timestamp column and press the ‘Pattern…’ button in the top-right corner (see Figure 38). You will see a few original timestamps as they are in your file (on the left side) and a preview of how Disco interprets them (in green, on the right side).

Figure 38: To make sure that your timestamp pattern was recognized correctly, import your data again and check the timestamp pattern dialog based on some sample timestamps.
Check in the green column whether the timestamps are interpreted correctly. Pay attention to the lower and upper case of the letters in the pattern, because it makes a difference. For example, the lower case ‘m’ stands for minutes while the upper case ‘M’ stands for months.
Note
How to fix:
If you find that the preview does not pick up the timestamps correctly, configure the correct pattern for your timestamp column in the import screen. You can empty the ‘Pattern’ field and start typing the pattern that matches the timestamps in your data set (use the legend on the right, and for more advanced patterns see the Java date pattern reference for the precise notation and further examples). The green preview will be updated while you type, so that you can check whether the timestamps are now interpreted correctly. Then, press the ‘Use Pattern’ button
Same Timestamp Activities¶
Another reason for why timestamps can cause problems is that they are not sufficiently different. For example, if you only have a date (and no time) then it may easily happen that two activities within the same case happen on the same day. As a result you don’t know in which order they actually happened!
Take a look at the simeple example data set in Figure 39. We can see a simple document signing process with four activities and three cases. Case 2 shows the expected sequence for this process: First ‘Created’, then ‘Sent to Customer, then ‘Response Received’, and finally ‘Document Signed’. But the order of the rows in the data set is not correct. For example, the steps ‘Sent to Customer’ and ‘Created’ are in the wrong order for Case 1 and both ‘Sent to Customer’ and ‘Created’ as well as ‘Document Signed’ and ‘Document Received’ are in the wrong order for Case 3.

Figure 39: A simple document signing process with four steps.
Normally, this is not a problem because when you import your data into the process mining tool then the sequence of events is automatically determined based on the timestamps. For example, the wrong sequence of the steps ‘Created’ and ‘Sent to Customer’ for Case 1 is corrected automatically, because the dates show that the two steps have happened in the opposite order (see Figure 40).

Figure 40: When your timestamps are different, unordered events in your data set are not a problem.
However, if two activities happen at the same time (on the same day in this example), then Disco does not know in which order they actually occurred. So, it keeps the order in which they appear in the original file. Because the order of the activities in the example file is random, this creates some additional variation in the process map (and in the variants) that should not be there.
For example, the three cases in the example from Figure 39 from a purely sequential process. However, because the wrongly ordered steps in Case 3 happen on the same day, you can see some additional interleavings in the process map. They reflect the different orderings of the same timestamp activities in the file (see Figure 41).

Figure 41: The problem with same timestamp activities is that they create noise in your process map that does not reflect the true process but comes from this data quality problem. So, you can’t differentiate actual process deviations from pure data problems.
So, if you don’t have sufficiently fine-granular timestamps to determine the order of all activities, or if you have many steps in your process occurring exactly at the same time, it often creates more complexity than is already there. What can you do to distinguish the real process complexity from the one just caused by the same timestamp problem?
Note
How to fix:
You can either leave out events that have the same timestamps by choosing a “representative” event (see strategy 1 below), or you can try pre-sorting the data (see strategies 2-4 below) to reduce the variation that is caused by the same timestamp activities.
Strategy 1: “Representative” (Leaving out events)¶
The reason for ‘Same Timestamp’ activities is not always an insufficient level of granularity in the timestamp pattern. Sometimes, it is simply the fact that many events are logged at the same time.
Imagine, for example, a workflow system in a municipality, where the service employee types in the new address of a citizen who moved to a new apartment. After the street, street number, postal code, city, etc., fields in the screen have been filled, they press ‘Next’ to finalize the registration change and print the receipt.
In the history log of the workflow system, you will most likely see individual records of the changes to each of these fields (for example, a record of the ‘Old value’ and the ‘New value’ of the ‘Street’ attribute). However, all of them may have the same timestamp, which is the time when the employee pressed the ‘Next’ button and the data field changes were all finalized (at once).
In Figure 42, you can see another example of a highly automated process. Many steps happen at the same time.

Figure 42: If many activities happen at the same time in an automated process, it can be a good strategy to choose a representative event that stands for all of the activities that are “logged at once”.
However, you may not need all of these detailed events and can choose one of them to represent the whole subsequence. For example, in the process shown in Figure 42 the first of the four highlighted events could stand for the sequence of these four. You can deselect the other steps via the ‘Keep selected’ option in the Attribute Filter.
In general, focusing on just a few – the most relevant – milestone activities is one of the most effective methods to trim down the data set to more meaningful variants if you have too many – See also Strategy 9: Focusing on Milestone Activities.
Strategy 2: Sorting based on sequence number¶
Sometimes, you actually have information about in which sequence the activities occurred in some kind of sequence number attribute. This is great, because you can now sort your data set based on the sequence number (see Figure 43) and avoid the whole Same Timestamp Activities problem altogether.

Figure 43: If you know the right order of the events in your data set, simply use this sequence number to sort the rows before importing your file into Disco.
Because Disco uses the sequence from the activities in your original file for the events that have the same timestamp, this pre-sorting step will influences the order in which the variants and the process flows are formed and, therefore, fix the random order of the Same Timestamp Activities.
Strategy 3: Sorting based on activity name¶
Of course you don’t always have a sequence number that you can rely on for sorting the data. So what else can you do?
A quick way that often already helps quite a bit is that you can pre-sort the data simply based on the activity name. The idea here is that at least the activities that have the same timestamp (and are sometinmes in this and sometimes in that order) are now always in the same order, even if the order itself does not make much sense.
This is easy to do: Simply sort the data based on your activity column before importing it. However, sometimes this strategy can also backfire, because you may – accidentally – introduce wrong orders in same timestamp activities that by coincidence were fine before.
For example, consider the outcome of sorting the data based on activity name for the document signing process in Figure 44:

Figure 44: Sorting your data set based on the activity names can help to reduce noise but it can also introduce wrong sequences that are new.
It has helped to reduce the variation in the beginning of the process, but at the same time it has introduced a reverse order for the activities ‘Document Signed’ and ‘Response Received’ for Case 1 (which have the same timestamps but were in the right order by coincidence in the original file).
Strategy 4: Sorting based on ideal sequence¶
To influence the order of the Same Timestamp Activities in the “right” way, you can best analyze those process sequences in your data that are formed by actual differences in the timestamp. You can also talk to a domain expert to help you understand what the ideal sequence of the process would be.
For example, if you look at Case 2 in the document signing process, then you can see that the sequence is fully determined by different timestamps (see Figure 45).

Figure 45: Look at your frequent variants and find cases that reflect the true process by looking for cases where all timestamps are different.
We are now going to use this ideal sequence to influence the sorting of the original data. One simple way to do this in Excel is to pre-face the activity names by a sequence number reflecting their place in the ideal sequence (i.e., ‘1 – Created’, ‘2 – Sent to Customer’, ‘3 – Response Received’, and ‘4 – Document Signed’) by using Find and Replace as shown in Figure 46.

Figure 46: Then sort your activities based on this ideal sequence.
After adding the sequence numbers, you can simply sort the original data by the activity column (see Figure 46).

Figure 47: After importing the sorted data set, you will only see true deviations from the expected process (if they are really reflected by the timestamps in the data) in your process map.
This will bring the activities in the ideal sequence. When you now import the data in Disco, you will only see deviations from the ideal sequence if the timestamps actually reflect that.
Different Timestamp Granularities¶
In the Same Timestamp Activities chapter we have seen how timestamps that do not have enough granularity can cause problems. For example, if multiple activities happen at the same day for the same case then they cannot be brought in the right order, because we don’t know in which order they have been performed. Another timestamp-related problem you might encounter is that your dataset has timestamps of different granularities.
Let’s take a look at the example in Figure 48. The file snippet shows a data set with six different activities. However, only activity ‘Order received’ contains a time (hour and minutes). All the other activities just have a date.

Figure 48: Sometimes, you have a mix of high timestamps granularities (for example, up to millisecond accuracy) and low timestamps granularities (for example, just dates) in your data set.
Note that in this particular example there is no issue with fundamentally different timestamp patterns. However, a typical reason for different timestamp granularities is that these timestamps come from different IT systems. Therefore, they will also often have different timestamp patterns. You can refer to the article How To Deal With Data Sets That Have Different Timestamp Formats to address this problem.
In this chapter, we focus on the problems that the different timestamp granularities can bring. So, why would this be a problem? After all, it is good that we have some more detailed information on at least one step in the process, right? Let’s take a look.
When we import the example data set in Disco, the timestamp pattern is automatically matched and we can pick up the detailed time 20:07 for ‘Order received’ in the first case without a problem (see Figure 49).

Figure 49: Disco tries to match your timestamps with as much accuracy as possible.
The problem only becomes apparent after importing the data. We see strange and unexpected flows in the process map (see Figure 50). For example, how can it be that in the majority of cases (1587 times) the ‘Order confirmed’ step happened before ‘Order received’?

Figure 50: Due to the different timestamp granularities, unexpected process flows emerge in the process map.
That does not seem possible. So, we click on the path and use the short-cut Filter this path… (see Filtering Paths from the Process Map) to keep only those cases that actually followed this particular path in the process as shown in Figure 51.

Figure 51: We investigate this unexpected path to find out what is going on.
We then go to The Cases View to inspect some example cases (see Figure 52). There, we can immediately see what happened: Both activities ‘Order received’ and ‘Order confirmed’ happened on the same day. However, ‘Order received’ has a timestamp that includes the time while ‘Order confirmed’ only includes the date.
For activities that only include the date (like ‘Order confirmed’) the time automatically shows up as “midnight”. Of course, this does not mean that the activity actually happened at midnight. We just don’t know when during the day it was performed.

Figure 52: All cases with the wrong order appear to have the order receipt and confirmation on the same day.
So, clearly ‘Order confirmed’ must have taken place on the same day after ‘Order received’ (so, after 13:10 in the highlighted example case). However, because we do not know the time of ‘Order confirmed’ (a data quality problem on our end) both activities show up in the wrong order.
Note
How to fix:
If you know the right sequence of the activities, it can make sense to ensure they are sorted correctly (Disco will respect the order in the file for same-time activities) and then initially analyze the process flow on the most coarse-grained level. This will help to get less distracted from those wrong orderings and get a first overview about the process flows on that level.
You can do that by leaving out the hours, minutes and seconds from your timestamp configuration during import in Disco (see an example below).
Later on, when you go into the detailed analysis of parts of the process, you can bring up the level of detail back to the more fine-grained timestamps to see how much time was spent between these different steps.
To make sure that ‘Order confirmed’ activities are not sometimes recorded multiple days earlier (which would indicate other problems), we filter out all other activities in the process and look at the Maximum duration between ‘Order confirmed’ and ‘Order received’ in the process map (see Figure 53). The maximum duration of 23.3 hours confirms our assessment that this wrong activity order appears because of the different timestamp granularities of ‘Order received’ and ‘Order confirmed’.

Figure 53: To confirm that the wrong sequence only occurs for activities that happen on the same day, we look at the maximum duration in the process map.
So, what can we do about it? In this particular example, the additional time that we get for ‘Order received’ activities does not help that much and causes more confusion than good. To align the timestamp granularities, we choose to omit the time information even when we have it.
Scaling back the granularity of all timestamps to just the date is easy: You can simply go back to the data import screen, select the Timestamp column, press the Pattern… button to open the timestamp pattern dialog, and then remove the hour and minute component by simply deleting them from the timestamp pattern (see Figure 54). As you can see on the right side in the preview, the timestamp with the time 20:07 is now only picked up as a date (16 December 2015).

Figure 54: To scale back the granularity of all timestamps, simply only match the most coarse-grained timestamp component in the timestamp pattern dialog.
When the data set is imported with this new timestamp pattern configuration, only the dates are picked up and the order of the events in the file is used to determine the order of activities that have the same date within the same case (refer to the chapter on Same Timestamp Activities for strategies about what to do if the order of your activities is not right).
As a result, the unwanted process flows have disappeared and we now see the ‘Order received’ activity show up before the ‘Order confirmed’ activity in a consistent way (see Figure 55).

Figure 55: After scaling back the timestamp granularity, all process flows appear in the right order.
Scaling back the granularity of the timestamp to the most coarse-grained time unit (as described in the example above) is typically the best way to deal with different timestamp granularities if you have just a few steps in the process that are more detailed than the others.
If your data set, however, contains mostly activities with detailed timestamps and then there are just a few that are more coarse-grained (for example, some important milestone activities might have been extracted from a different data source and only have a date), then it can be a better strategy to artificially provide a “fake time” to these coarse-grained timestamp activities to make them show up in the right order.
For example, you can set them at 23:59 if you want them to go last among process steps at the same day. Or you can give a time that reflects the typical or expected time at which this activity would typically occur.
Be careful if you do this and thoroughly check the resulting data set for problems you might have introduced through this change. Furthermore, it is important to keep in mind that you have created this “fake” time when interpreting the durations between activities in your analysis.
Unwanted Parallelism¶
Disco detects parallelism if two activities for the same case overlap in time [Rozinat-09-17]. Usually, this is exactly what you want. If you have a process that contains parallel activities, these activities cannot be displayed in sequence because this is just not what happens.
However, sometimes activities can overlap in time due to data quality problems. For example, if you look at the ‘Case 1’ in Figure 56 then you see that activities B and C overlap by just 1 second. The process mining tool sees that both activities are (partially) going on at the same time and shows them in parallel.

Figure 56: Activities are in parallel if they overlap in time.
If you expect your process to be sequential, parallelism may be due to the way that the data is recorded. For example, for ‘Case 1’ above the Complete Timestamp for activity B might have been supposed to be the same as the Start Timestamp for activity C, but they were written by the logging mechanism one after the other, or the writing of the Complete Timestamp for activity B might have been delayed by the network in a distributed system.
So, if the process that you have discovered is different from what you expected it to be, it is worth investigating whether you are dealing with parallel activities.
One way to see that you are dealing with parallelism is that the frequency numbers in the process map add up to more than 100%. For example, in the process map above activity A has the frequency 1 but the frequencies at the outgoing arcs add up to 2 because both parallel branches are entered in parallel. Another way to see this is by switching to the Graph view in the Cases tab (see Individual Cases), which will not show you any waiting time between activities that overlap in time (if there is 0 time between them the waiting time will be shown as ‘instant’).
Note
How to fix:
- First, investigate individual parallel cases to understand the extent and the nature of the parallelism in your process (see Explore individual parallel cases). For example, it could be that parts of your process are actually happening in parallel while you expected the process to be sequential.
- If you are sure that the parallelism is due to a data quality problem, you can create a sequential view of your process by choosing just one timestamp column during the import step (see Import sequential view of the process).
- To fully resolve unintended overlapping timestamps for activities that should be recorded in sequence, you need to go back to the data source and correct the timestamps before you import the data again into Disco with both timestamps. Ultimately, the logging mechanism needs to be fixed to prevent the problem to re-occur in the future.
Both of the following strategies can also be useful to better understand processes that actually have legitimate parallel parts in them. Parallel processes are often much more complicated to understand and it can help to look at example cases and at sequential views to better understand the (correct but still complicated) parallel process views.
Explore individual parallel cases¶
When you look at an individual case in the process map for a sequential process, the result is quite boring because you will see just a sequence of activities (unless there is a loop in the process). However, in parallel processes each case can have activities that are performed independently of each other. So, the process map for even a single case can become quite complex.
To fully understand this, it helps to look at an individual case in isolation. For example, in a project management process that contains a lot of parallel activities we might choose to look at the fastest case to get an idea of what the process flow has looked like in the best case. To do this, we sort the cases based on the duration and use the short-cut ‘Filter for case …’ via right-click to automatically add a pre-configured Attribute filter for this case. We can then save this view with the name ‘Fastest case’ (see Figure 57).

Figure 57: Filter one single case.
After applying the filter, we can see the process map for just this one case. Although we are looking at a single case, the process map does not just show a sequential flow but a process with parallel activities in several phases (see Figure 58).

Figure 58: The process map of the single case shows where the parallel activities occur.
When we look at the performance view, we can see that out of the 5 activities that are performed in parallel between the ‘Manage Test plans’ and the ‘Install in Test Environment’ milestones the ‘Quality Plan Approval’ and the ‘CSR Plan Approval’ steps take the longest time (see Figure 59).

Figure 59: The performance view shows wich of the parallel activities takes most of the time.
When we animate this single case, we see the parallel flows represented by individual tokens as well. For example, in Figure 60, we can see that on Sunday 20 May the ‘Quality Plan Approval’ and the ‘CSR Plan Approval’ activities were still ongoing (see blue token in activity) while the other three activities had already been finished (see yellow tokens between activities).

Figure 60: The animation shows which activities are running in parallel.
In contrast, when we look at the slowest case in this project management process then we observe that the most time is spent in a later part of the process, namely the ‘Run Tests’ activity (see Figure 61).

Figure 61: The slowest case has the bottleneck in a different part of the process.
To view multiple parallel cases - still isolated from each other - next to each other, you can duplicate the case ID column in the source data and import your data again with the duplicated column configured as part of the activity name (see Comparing Processes). You will then see the process maps for all the individual cases next to each other. Of course, this will be too big for all cases, but you can then again focus on a subset by filtering, e.g, 2 or 3 cases and look at them together.
This will provide you a relative comparison for the performance views. Furthermore, you can use the Synchronized Animation to compare the dynamic flow across the selected cases with a relative start time in the animation.
Import sequential view of the process¶
To completely “turn off” the parallelism in the process map, you can simply import your data set again and configure only one of your timestamps as a ‘Timestamp’ column. If you have only one timestamp configured, Disco always shows you a sequential view of your process. Even if two activities have the same timestamp they are shown in sequence with ‘instant’ time between them.
Looking at a sequential view of your process can be a great way to investigate the process map and the process variants without being distracted by parallel process parts. Furthermore, taking a sequential view can be a quick fix for a data set that has unwanted parallelism due to a data quality problem as shown above.
If we want to take a sequential view on the example Case 1 from Figure 56, we can choose either the ‘Start Timestamp’ or the ‘Complete Timestamp’ as the timestamp during the import step. Keep in mind that the meaning of the waiting times in the process map changes depending on which of the timestamps you choose (see also Different Moments in Time).
For example, if only the ‘Start Timestamp’ column is configured as ‘Timestamp’ during the import step, then the resulting process map shows a sequential view of the process for Case 1. Because there is only one timestamp per activity, the activities themselves have no duration (shown as ‘instant’). The waiting times reflect the times between the start of the previous activity until the start of the following activity (see Figure 62).

Figure 62: “Turn off” the parallel view by importing only one timestamp.
In contrast, when the ‘Complete Timestamp’ column is chosen as the timestamp then the waiting times will be shown as the durations between the completion times of the activities (see Figure 63).

Figure 63: The perspective of the waiting time changes depending on which timestamp you choose.
So, keep this in mind when you interpret the performance information in your sequential process map after importing the data again with a single timestamp. [5]
To sum it up, parallel processes can cause headaches due to their increased complexity quite quickly. Try the two strategies above and don’t forget to also apply the regular simplification strategies to explore what helps best to give you the most understandable view (see Simplify Complex Process Maps). For example, looking at different process phases of the process in isolation (see Strategy 6: Breaking up Process Parts) and taking a step back by focusing on the milestone activities (see Strategy 9: Focusing on Milestone Activities) can be really useful. All these strategies can also be combined with each other.
Wrong Timestamp Column Configuration¶
During the import step, you may have accidentally configured some columns as a timestamp that do not actually have the meaning of a process mining Timestamp field. A data field that looks like a timestamp but is not a real process mining timestamp could be a case-level data attribute, such as the birthday of a customer. It could also be a global timestamp field for the overall process, such as the case case creation date.
The problem with non-timestamp columns being configured as timestamps is that this typically leads to accidental parallelism (see also Unwanted Parallelism). As a result, the process map looks really weird and does not reflect the process that you expect to see. For example, you may see all the activities in the process next to each other horizontally.
In the customer service refund example in Figure 64, the purchase date in the data has the form of a timestamp. However, this is a date that does not change over time and should actually be treated as an attribute. You can see that both the ‘Complete Timestamp’ as well as the ‘Purchase Date’ column have the title clock symbol in the header, which indicates that currently both are configured as a timestamp.

Figure 64: Make sure that no column is configured as a Timestamp that should just be a regular process attribute.
If columns are wrongly configured as a timestamp, Disco will use them to calculate the duration of the activity. As a consequence, activities can show up in parallel although the are in reality not happening at the same time.
Note
How to fix:
Make sure that only the right columns are configured as a timestamp: For each column, the current configuration is shown in the header. Look through all your columns and make sure only your actual timstamp columns are showing the little clock symbol that indicates the timestamp configuration. Then, press again the ‘Start import’ button.
For example, in the customer service data set, we would simply change the configuration of the ‘Purchase Date’ column to a normal attribute as shown in Figure 65.

Figure 65: If you find a column that appears to be but should not be a timestamp column, you can configure it as an ‘Other’ attribute during import.
Just as a general rule of thumb, no column should be configured as a Timestamp column in the process mining sense if it does not change over the course of a case (see also Timestamp History?).
Recorded Timestamps Do Not Reflect Actual Time of Activities¶
A Dutch insurance company completed the process mining analysis of several of their processes. For some processes, it went well and they could get valuable insights out of it. However, for the bulk of their most important core processes, they realized that the workflow system was not used in the way it was intended to be used.
What happened was that the employees took the dossier for a claim to their desk, worked on it there, and put it in a pile with other claims. At the end of the week, they then went to the IT system and logged in the information — Essentially documenting the work they had done earlier.
This way of working has two problems:
- It shows that the system is not supporting the case worker in what they have to do. Otherwise they would want to use the system to guide them along. Instead, the documentation in the system is an additional, tedious task that is delayed as much as possible.
- Of course, this also means that the timestamps that are recorded in the system do not represent the actual time when the activities in the process really happened. So, doing a process mining analysis based on this data is close to useless.
The company is now working on improving the system to better support their employees, and to — eventually — also be able to restart their process mining initiative again.
You might encounter such problems in different areas. For example, a doctor may be walking around all day, speak with patients, write prescriptions, etc. And then by the end of the day she sits down in her office and writes up the performed tasks for the administrative system. Another example is that the timestamps of a particular process step are manually provided and people make typos when entering them.
So, what can you do if you find that your data has the problem that the recorded time does not reflect the actual time of the activities?
Note
How to fix:
First of all, you need to become aware that your data has this problem. That’s why the data validation step is so important (make sure to also read the chapter about the Data Validation Session).
Once you can make an assessment of the severity of the gap between the recorded timestamps in your data and the actual timestamps of the recorded activities, you need to decide whether (a) the problem is localized or predictable, or (b) all-encompassing and too big to analyze the data in any useful way.
If the problem is only affecting a certain activity or part in your process (localized), you may choose to discard these particular activities for not being reliable enough. Afterwards, you can still analyze the rest of the process.
If the offset is not that big and predictable (like the doctor writing up her activities at the end of the day), you can choose to perform your analysis on a more coarse-grained scale. For example, you will know that it does not make sense to analyze the activities of the doctor in the hospital on the hour- or minute-level (even if the recorded timestamps carry the minutes, technically). But you can still analyze the process on a day-level.
Finally, if the problem is too big and you don’t know when any of the activities actually happened (like in the example of the insurance company), you may have to decide that the data is not good enough to use for your process mining analysis at the moment.
Different Clocks¶
In the previous chapters you have already seen how wrong timestamps can mess up everything in process mining: The process flows, the variants, and time measurements like case durations and waiting times in the process map.
One particularly tricky reason for timestamp errors is that the timestamps in your data set may have been recorded by multiple computers that run on different clocks. For example, at a security services company [Vanherle] operators logged their actions when they arrived on-site, identified the problem, etc. on their hand-held devices. These mobile devices sometimes had different local times from the server as well as from each other.
If you look at the scenario in Figure 66 you can see why that is a problem: Let’s say a new incident is reported at the headquarters at 1:30 PM. Five minutes later, a mobile operator responds to the request and indicates that they will go to the location to fix it. However, because the clock on their mobile device is running 10 minutes late, the recorded timestamp indicates 1:25 PM.
When you then combine all the different timestamps in your data set to perform a process mining analysis, you will actually see the response of the operator show up before the initial incident report. Not only does this create incorrect flows in your process map and variants, but when you try to measure the time between the raising of the incident and the first response it will actually give you a negative time.

Figure 66: If you mix events that were recorded at different places with different clocks, you can get strange effects in the process sequence and an inaccurate picture of the true process.
So, what can you do when you have data that has this problem?
First, investigate the problem to see whether the clock drift is consistent over time and which activities are affected. Then, you have the following options.
Note
How to fix:
- If the clock difference is consistent enough you can correct it in your source data. For example, in the scenario above you could add 10 minutes to the timestamps from the local operator.
- If an overall correction is not possible, you can try to clean your data by removing cases that show up in the wrong order. Note that the Follower Filter in Disco also allows you to remove cases, where more or less than a specified amount of time has passed between two activities. This way, you can separate minor clock drift glitches (typically the differences are just a few seconds) from cases where two activities were indeed recorded with a significant time difference. Make sure that the remaining data set is still representative after the data cleaning step.
- If nothing helps, you might have to go back to your data collection system and set up a clock synchronization mechanism to constantly measure the time differences between the networked devices and get the correct timestamps while recording the data along the way.
| [Suriadi] | Suriadi Suriadi, Robert Andrews, Arthur ter Hofstede and Moe Wynn. Event log imperfection patterns for process mining: Towards a systematic approach to cleaning event logs, 2017, Information Systems, 64, pp. 132-150. URL: http://eprints.qut.edu.au/97670/ |
| [Bose] | Jagadeesh Chandra Bose, Ronny Mans and Wil van der Aalst. Wanna Improve Process Mining Results? It’s High Time We Consider Data Quality Issues Seriously, 2013 IEEE Symposium on Computational Intelligence and Data Mining - ISBN 978-1-4673-5895-8. - p. 127-134. URL: https://www.researchgate.net/publication/261351894_Wanna_improve_process_mining_results |
| [TBurette] | T Burette. So You Want To Write Your Own CSV code?, 2014. URL: http://tburette.github.io/blog/2014/05/25/so-you-want-to-write-your-own-CSV-code/ |
| [BPI13] | Fluxicon, BPI Challenge 2013. URL: http://fluxicon.com/blog/2013/06/bpi-challenge-2013/ |
| [BPI13W] | Fluxicon, Winner of BPI Challenge 2013 Announced. URL: https://fluxicon.com/blog/2013/08/winner-of-bpi-challenge-2013-announced/ |
| [Rozinat-09-17] | Dealing With Parallelism in Your Process Maps. URL: https://fluxicon.com/blog/2017/09/dealing-with-parallelism-in-your-process-maps/ |
| [Vanherle] | Walter Vanherle, Case study: Process Mining to Improve the Intervention Management Process at a Security Services Company, 2014. URL: https://fluxicon.com/blog/2014/03/case-study-process-mining-to-improve-the-intervention-management-process-at-a-security-services-company/ |
Footnotes
| [1] | Alternatively, you could also use a Performance Filter with the ‘Number of events’ metric to remove cases that are overly long. |
| [2] | You can do this in Excel or using an open source ETL tool. For example, in the ETL tool KNIME (https://www.knime.org) you can create a workflow converting the column-based data set to a row-based data set using the three nodes ‘xls reader’ -> ‘unpivot’ -> ‘xls writer’. |
| [3] | Another danger of this approach is that if the two steps are not in the expected order, you will actually end up with a negative duration. |
| [4] | Disco tries to guess the right timestamp pattern based on a sample of your data set. But, for example, if your sample only includes events from one month with a day of the month lower than 12 then it might confuse the day and the month component. |
| [5] | Note that the order of the events in a case - and, therefore, the variants - might change when you change the import perspective from ‘start’ timestamp to ’end’ timestamp (or the other way around) as well. |