Hands-on practice is at the very heart of this year’s Process Mining Camp on 13 and 14 June. Above, you can watch a short video we recorded to tell you more about the workshops on the second day of camp.
To help you advance your process mining skills, you will get to work on real-life data sets. You will be exposed to the same challenges that you typically also encounter in your own process mining projects, supported by our expert guidance. You will participate in three workshops that fit together perfectly, with each of them focusing on different skills that you need to be successful.
There is a certain magic in watching an experienced process miner approach a new data set. While they apply standard practices like identifying incomplete cases, they also follow their intuition and explore layers of the process in an iteration of discovery, questions, and analysis cycles.
Sure, it takes domain knowledge to identify the standard process and its deviations. But it is also a question of experience to know what to look out for, which questions to ask, and how to break up the “spaghetti processes” — even if you are not familiar with the process at all.
In this workshop, you are going to practice on a real-life data set. Together, we will discover and analyze this data set in multiple phases. We show you standard practices and discuss the results in each phase before going further. There will be time to apply the same approach to multiple data sets, and you can even bring your own data, if you like!
It is important to accept that your process mining data will not be perfect when you start analyzing it. After all, the vast majority of IT systems were not created with process mining in mind. Recognizing these limitations should not discourage you. Instead, embrace it as an opportunity for getting creative! Learn to navigate the available data and its possibilities.
In this workshop, you are going beyond the fundamentals of process mining, typically centered around case IDs, timestamps, and activity logs. More than just talking about these concepts, you are going to experience them together to gain a better understanding of the associated challenges and explore potential remedies.
To achieve this, you will immerse yourself in a practical case. In multiple steps, you will identify and address issues like faulty and missing data. You will explore techniques for combining event logs from different systems. And you will be stretching the boundaries of the data beyond their original design. We’ll also be discussing what the logs of the future might look like, and what steps you can take today to achieve that vision.
How do you translate process mining insights into changes in your organization? How do you make sure that the improvements stick? And how do you develop your process mining projects into a routine and general practice? The challenges for process mining are not only about technical skills. You also need to take strategic and cultural factors into account.
There is no simple recipe for what makes process mining successful. But there are a lot of different lessons that can be derived from both successes and from setbacks. By now, we have all been talking about these challenges and our experiences for two days — in the discussion groups, over dinner and drinks, in the breaks, during the workshops. In this last workshop, we take a step back and collect what we have learned.
Together, we are going to make this really practical. We will list what works, what doesn’t work and in which situation — and we put it into perspective. You will leave camp with new approaches and patterns that you can apply right away in your future process mining projects.
They discover process flows for the bus lines in Montevideo using open data from the city. They then export the XML process maps from Disco to display the discovered processes in the spatial city map. Andrea and Daniel share their scripts and will give you all the information that you need to reproduce their steps.
How could you do a similar analysis for your own city? Join us tomorrow, Wednesday, 20 March, at 15:00 CET to find out! (Check your timezone here). As always, no registration is required. Simply point your browser to fluxicon.com/cafe when it is time. You can watch the café and join the discussion while we are on the air, right there on the café website.
This is a guest article by Andrea Delgado, Daniel Calegari, and Nicolás Carignani from the Computer Science Institute, School of Engineering, Universidad de la República, Uruguay. They have used open data to discover the process flows from bus lines in Montevideo. They then exported the XML process maps from Disco to display the discovered processes in the spatial city map. In this article, they explain their approach and give you all their scripts and the information that you need to reproduce the approach for your own city.
If you have a guest article or process mining case study that you would like to share, please get in touch with us via anne@fluxicon.com.
Urban mobility allows us to access housing, jobs, and urban services, and its planning, control, and analysis are of utmost importance to city governments. Transport modeling and planning must address several challenges, such as traffic congestion, public transport crowding, pedestrian difficulties, and atmospheric pollution. Smart cities use technology to improve urban services, e.g., Intelligent Transportation Systems that incorporate technologies generating real-time data that can be processed to extract valuable information.
In 2010, the Municipality of Montevideo, Uruguay, defined a Mobility Plan, which included the creation of the Metropolitan Transportation System (Sistema de Transporte Metropolitano, STM), serving a population of 1.4 million. The STM defines several city public transportation elements, adding an ITS with on-board GPS unit control systems on each bus and smart cards for citizens, as illustrated in Figure 1. The Mobility Management Center manages and controls traffic and transportation in the city using the real-time data provided by the STM.
Fig. 1: STM system elements: smart cards for citizens, buses with GPS, and smart card readers that register data for each trip.
We address a set of questions defined by the Municipality of Montevideo in the context of a joint research project concerning their transportation system (STM) data from buses and smart card trips by applying process mining techniques. For this, we use open data provided by the STM within the governmental open data catalog1. We provided another view on public transportation data to business experts to help them make decisions on the city’s urban mobility, considering different perspectives, including the behavior of bus lines according to the planned routes [1].
People working in the urban mobility domain are used to analyze data in traditional formats (tables, graphics, etc.) and locate geospatial data in the city map. In our first attempt, we analyzed the reference process model corresponding to the bus routes and the data from the actual trips made by passengers within the buses using a traditional process mining approach. However, we realized that the results could be deployed over Montevideo´s city map to improve visualization and understanding of the outcomes.
In what follows, we present an extract of the behavior of bus lines analysis presented in [1], focusing on deploying the bus lines process models provided by Disco over Montevideo´s city map using the open-source geospatial software QGis2.
Open Data from the STM system
Below, we present some definitions of the Metropolitan Transport System (STM) that are needed to understand the data we used for the analysis:
A line is a public name by which a set of routes of a transportation company is known, e.g., 2, 103, 148, 306, 405, 526, D11.
Sub-lines are each one of the routes that a line has (difference in the streets traveled), with a direction.
A variant is each instance of the route of a sub-line, with a specific origin, destination, and direction (maximal, partial, circular)
Every variant (line, sub-line, direction, origin, destination) has a set of frequencies that defines a departure time on a given day (working days, Saturdays, Sundays, and holidays).
Stops in the route of each variant are known, as well as the stop of origin and destination, all identified by a unique code.
The theoretical schedule by which a bus travels through each stop is also known for each frequency. Apart from the bus data, the information on passengers’ STM card payments is also known. There are different types of passengers, e.g., ordinary users, retirees, and students. Every time a payment is recorded, there is a registry with the kind of passenger, the stop at which it boards, the variant and frequency to which the bus belongs, and the time of departure, among other information. Below, we present the primary datasets we used for the reference process models of the bus line routes and the process model of actual passengers’ trips we show in the map of Montevideo, extracted from [1].
[UBS] Urban bus schedules, by stop3. It contains the bus schedules for urban transportation. These are estimated theoretical schedules in which a bus line will pass through a particular stop along its route. These data are obtained by estimating each stop’s passing times according to the transport units’ average speed, predefined schedule, and distance between stops.
type of day: 1 - working days (Monday to Friday), 2- Saturdays, 3 - Sundays and holidays.
cod variant: identifies the variant of the line.
frequency: identifies the frequency for the variant for the type of day, i.e., the specific hours.
cod loc stop: shows the code of each stop
ordinal: shows the number of stops within the bus line route, i.e., first (1), second (2), etc.
hour: shows the estimated hour for the bus to arrive at the stop
day before: indicates if the frequency started the day before (for late-night lines)
The UBS file contains data from more than 100 bus lines with more than 800 variants and 1000 corresponding frequencies. Four companies provide the service and cover the metropolitan area with more than 4700 stops.
[TSB] Trips made on STM buses4. It contains all the trips made on the urban collective transport lines in Montevideo by each operating company, line, variant, day and time, tickets sold at all stops in the system, by type of user, payment method, and sections of each trip. The information comes from all the records processed by the STM trip validation machines.
id trip: identifies the trip within the system; in combined tickets, the id trip is repeated in all
buses the user rides while the ticket is valid.
line code: shows the code of the bus line
cod variant: identifies the variant of the line
frequency: identifies the frequency for the variant
with card: shows if the STM card was used in the payment of the trip
date event: timestamp of date and hour of the trip
origin stop code: shows the code of the stop at which the user got on the bus
The TSB file we used to analyze the STM trips corresponds to May 2022, which contains 25 million records, including all trips from the STM system registered within the 136 bus lines of Montevideo. For experimentation, we selected different bus lines from these to maximize the city coverage [1].
[BLOD]5 Bus lines, origin, and destination. It contains geographic information that, among other data, includes the lines’ description, origin, and destination. This dataset contains the shapefile6 that provides geospatial data for the bus line destinations for each bus line, sub-line, and variant.
[CTSC]7 Buses: stops and checkpoints. It contains geographic information on stops and control points. This dataset contains the shapefile with geospatial data for the stops defined within the city, referenced in the bus lines routes.
Process mining applied to urban mobility
From the perspective of the behavior of bus lines according to the planned routes, we analyzed the data to answer some of the business experts’ questions, in particular, the ones related to bus lines and their use by passengers:
What is the route of a bus line?
How is the mobility of people within the STM?
Regarding the reference model of the bus lines (question 1), we can obtain it from the UBS file that contains the theoretical schedules. We select variants for each line, setting the variant and frequency codes and day as {case ID}, the stop code as {activity ID}, the hour of the stop as {timestamp}, and the rest of the data fields as {attributes} of the activity. Since variants have different directions corresponding to the sub-line, we obtain two sequential sections in each direction. The reference model must contain the same stops in the same order as the ones defined by the variant in the STM system, which is accessible from the website for a scheduled consultation.
Regarding users’ data on authentic trips of the bus lines (question 2), we can discover a travel model for a bus line from the TSB file. We filter by line and selected the variant, frequency, and day of the trip as {case ID}, the stop code as {activity ID}, the hour of each trip of each stop as {timestamp}, and the rest of the data fields as {attributes} of the activity. The number of events at each stop is the number of passengers boarding. Thus, loops represent multiple passenger boardings at the same stop. Unlike the reference model, the process is not linear since, in some frequencies, there are stops in which nobody boards. We can filter data by days (business days, Saturdays, Sundays, and holidays), day hours, seasons, type of user, company, etc.
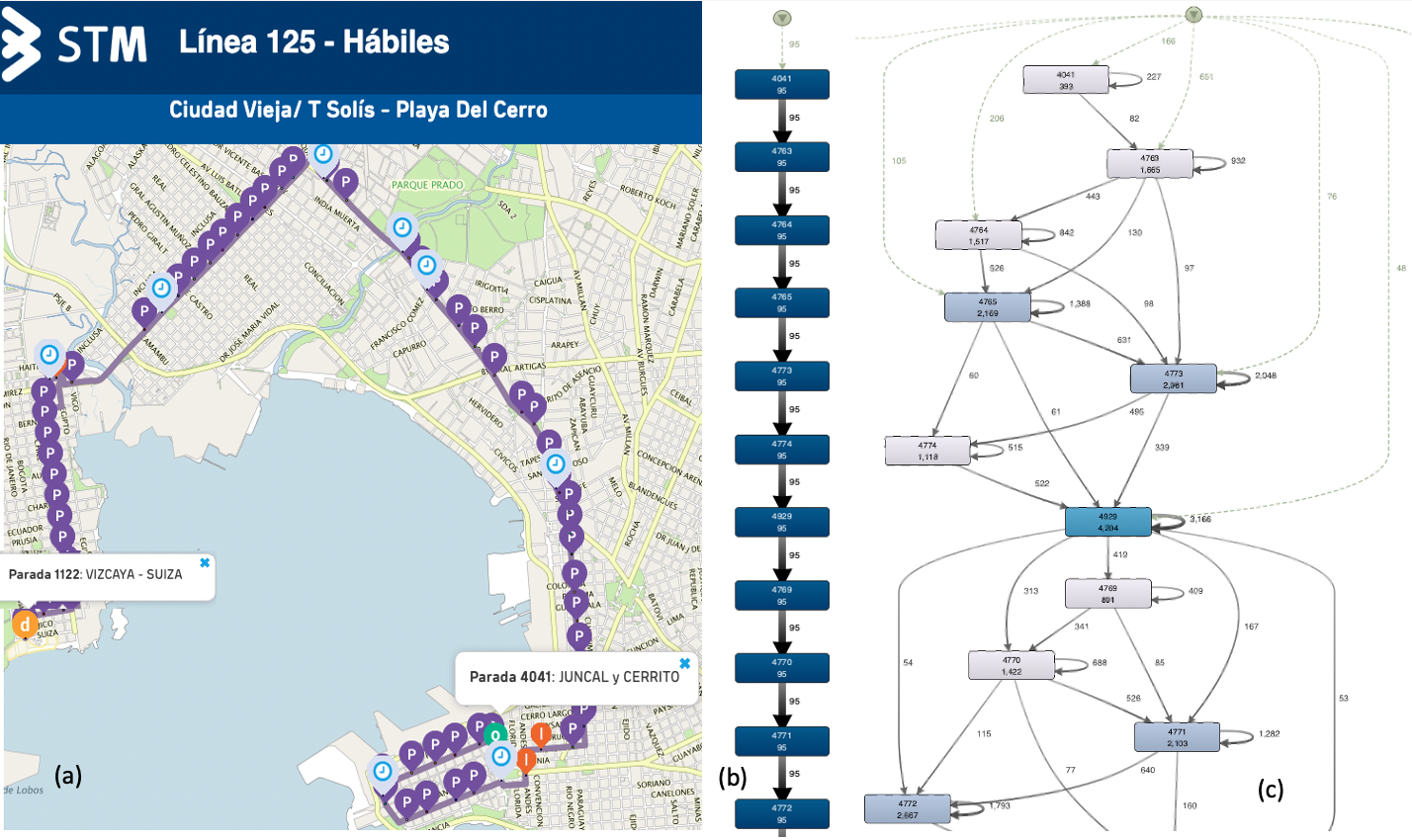
Figure 2 (extracted from [1]) depicts examples of these two process models discovered in Disco for bus line 125, variant 667, which is the maximal variant in one direction. This bus line goes in one direction from the old city to the West, ending in Cerro Beach and returning in the other direction.
In this Figure, we can see: a) the bus line in the map taken from the STM schedules site8, b) an excerpt of the reference model (i.e., bus stops included in the line), and c) an excerpt of the STM trips within its frequencies.
Fig. 2: Bus line 125 route from [1] with stops for the 667 variant: a) in the STM website bus schedule, b) excerpt of the reference model, and c) excerpt of the STM trips within its frequencies
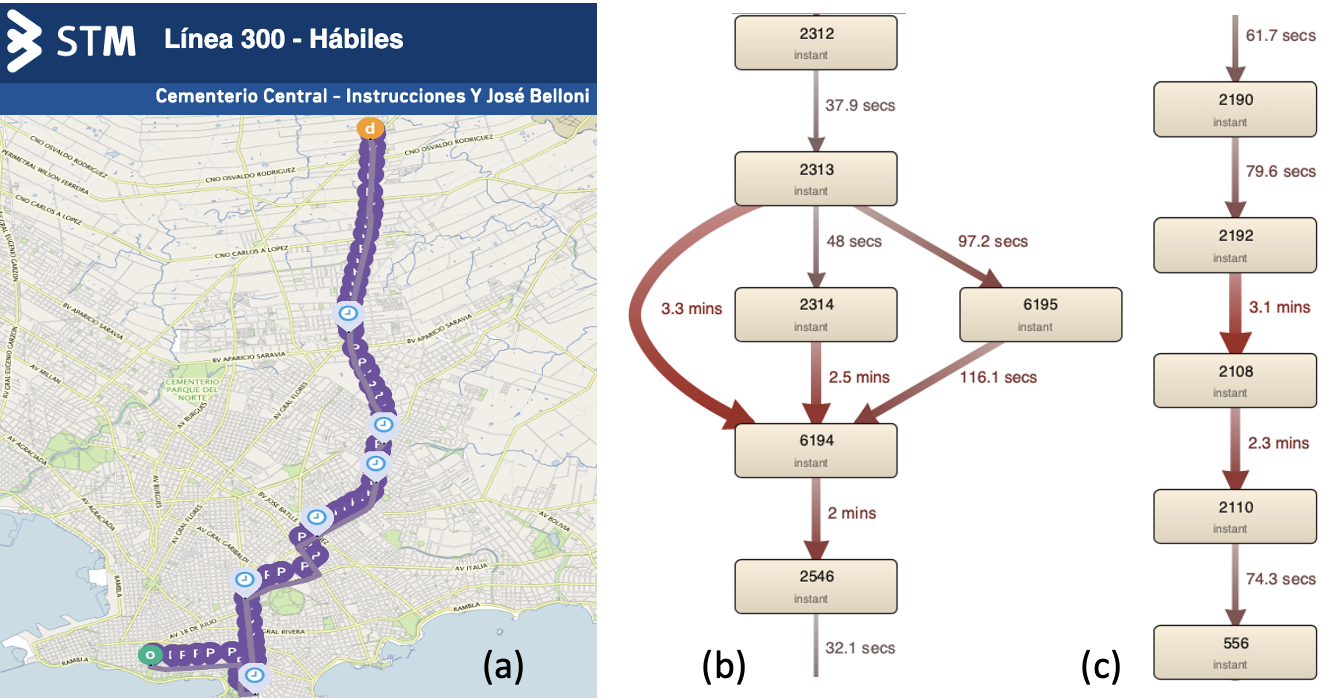
From users’ data on actual trips of the bus lines (question 2), it could be possible to analyze load metrics after filtering and discovering the model. For example, it is possible to answer: At which stops do people not get on? At which stops do more people get on? At what times does the bus have more and fewer passengers? What happens to those lines in a particular area? Moreover, it is possible to answer performance questions such as: What is the total duration of the frequencies (on average, maximum, minimum)? Are there frequencies with delays? As an example, we present in Figure 3 the performance model for bus line 300 (one of its variants), which goes from the bottom of the city near the city center to the city’s north periphery, showing the delays in the transitions between stops of the bus line route, calculated with the actual trips data.
Fig. 3: Bus line 300 route with stops for one of its variants: a) in the STM website bus schedule, b) and c) excerpt of performance models with delays in the transitions from the STM trips data.
Exporting from Disco and visualizing the models over Montevideo´s city map
As mentioned before, people working in the urban mobility domain are used to seeing locations on the city map, analyzing data, and considering geospatial data. Although the process models provided valuable information, they should be compared manually to the bus line route provided over the STM site’s city map to identify where some behaviors arise. To improve visualization for business experts, we developed a prototype to deploy process models over Montevideo’s city map.
Disco allows the export of XML files of the resulting process models, both the process map and the performance view. As we selected the bus line stops as activities of the process, which have a corresponding geospatial location over Montevideo city, we can locate each stop in the map and, correspondingly, the Disco process model we exported. Also, the dataset containing the data for each bus line route destination is used to locate the reference bus line route over the map. These data correspond to BLOD and CTSC files with shapefiles geospatial data of the bus line routes and stops in Montevideo.
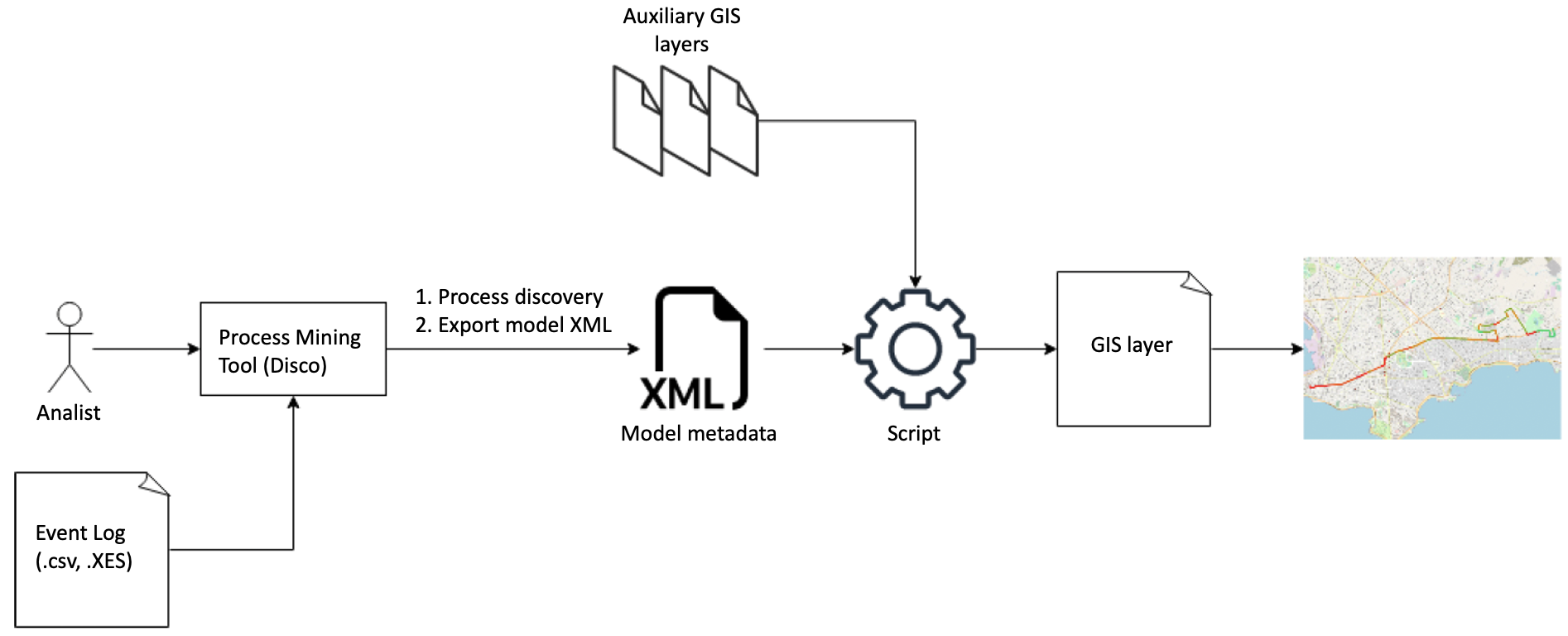
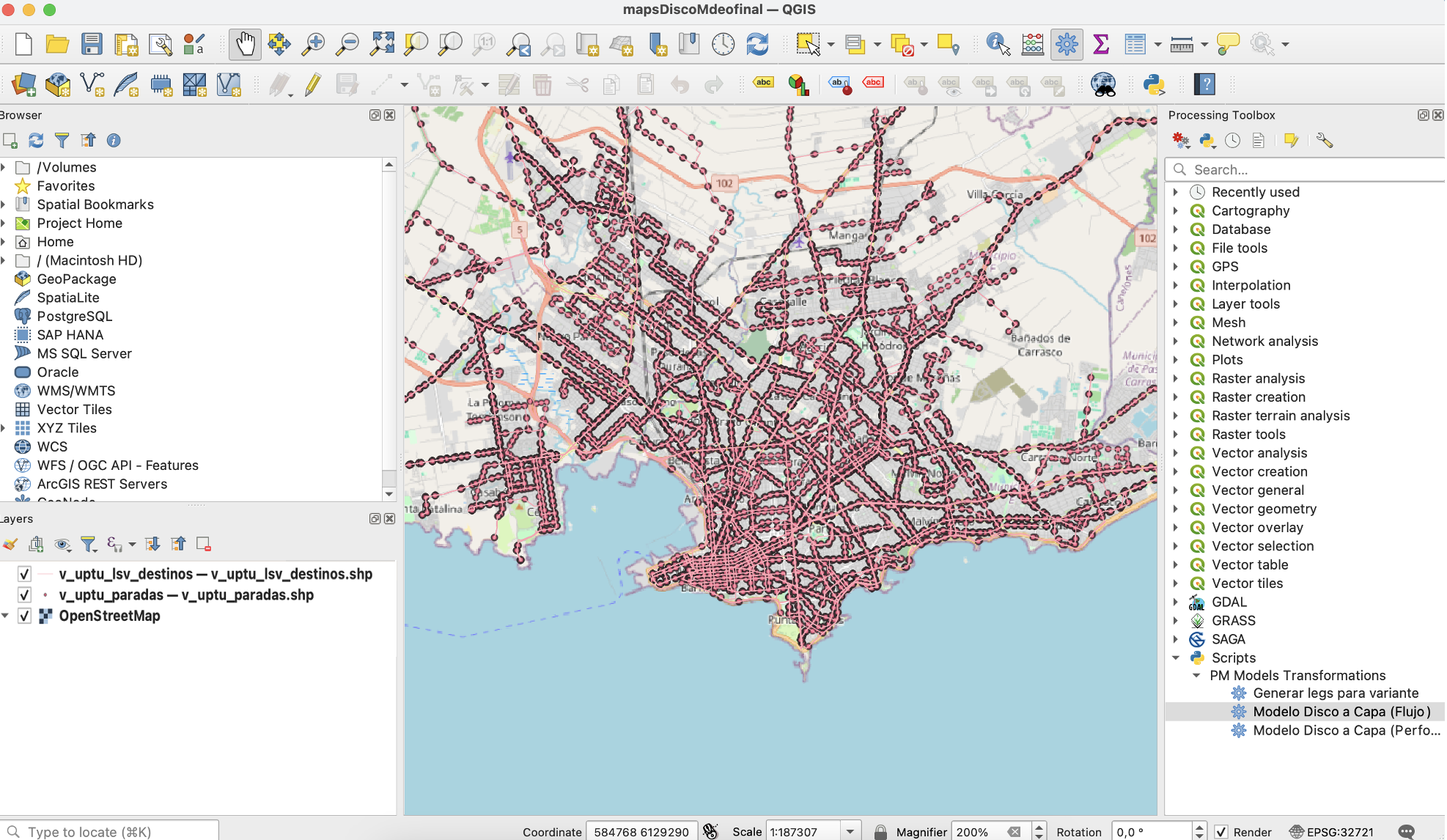
We used the open-source geospatial software QGIS, which supports loading city maps with corresponding coordinates worldwide, creating/adding layers with geospatial data in the shapefiles to be seen over the map, and developing scripts with Python to work with them. In Figure 4, we present the process flow for deploying the process models exported from Disco over the city map loaded in QGis with the help of the scripts we developed.
Fig. 4: Process for deploying process models exported from Disco over the city map in QGis.
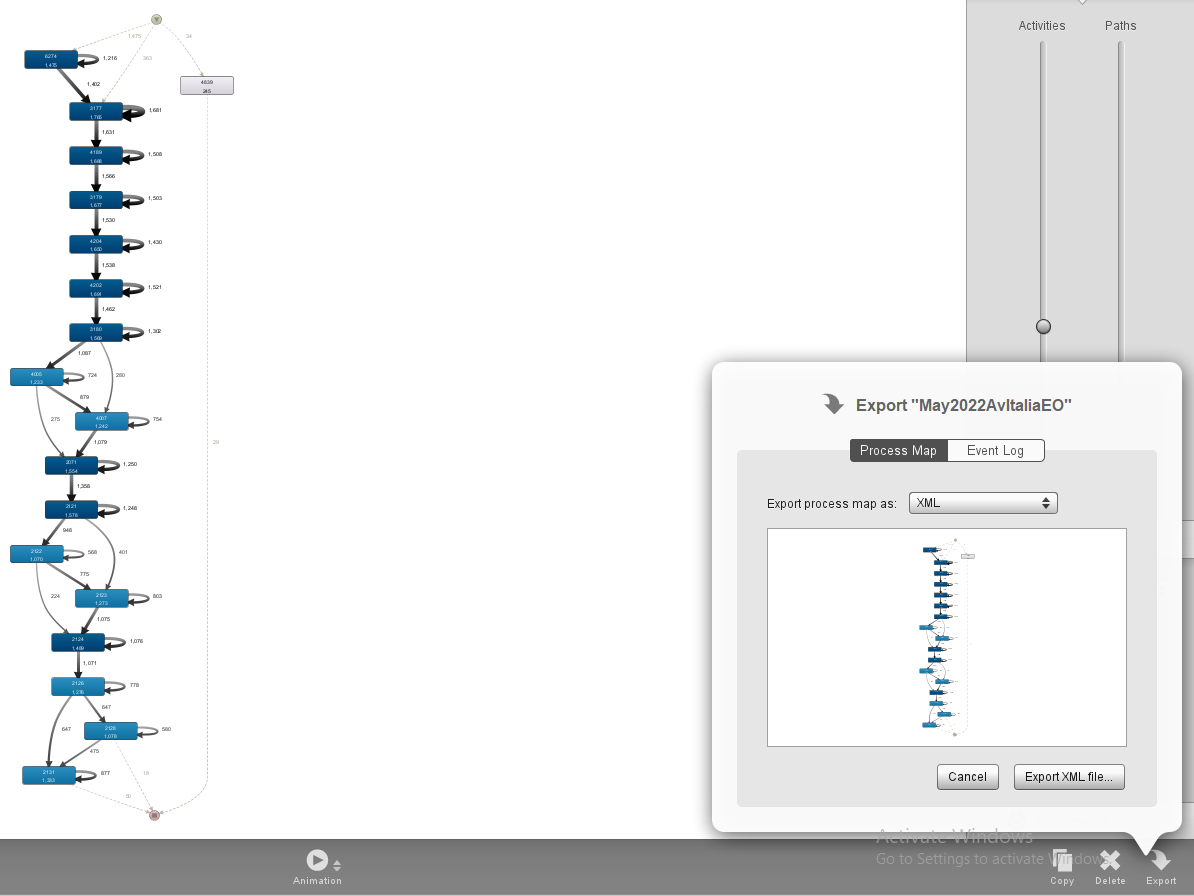
The first step is to load the event log into Disco, in our case, the data corresponding to the passengers’ actual trips over a bus line, to discover the corresponding process model of the bus line route, which can be filtered by variant as shown above. Then, the resulting process model can be exported in XML format, which will be one of the inputs to QGis to show over the city map. We want to show both the process map with the flow of the actual trips over the bus line and the performance map with the delays of the buses on the actual trips, as depicted in Figures 2 and 3. In Fig. 5 a screenshot of the export model XML we used in Disco is shown.
Fig. 5: Disco export model in XML format
In QGis, we first load the shapefile data of the stops and the origin and destination of buses over the city map as vector layers and then the city map layer as the XYZ layer. These layers should be in the same coordinate format and time zone to match locations. We load the Python scripts we developed in the project options. Figure 6 shows a QGis screenshot with the three layers in the bottom left panel and the Python scripts in the right panel.
Fig. 6: QGis software with Montevideo city map layer (XYZ), bus stops over the city (from CTSC shapefile), and bus lines origin and destination over stops (from BLOD shapefile)
The Python scripts we developed transform the Disco process models into a QGis layer that can be deployed over the city map, using as reference the stops and the bus line origin and destination geospatial data we first loaded over the city map. The QGis scripts are as follows:
layer_from_disco_model_flow.py: transforms a Disco process model flow (XML) into a QGIS layer, which allows visualization over the map.
legs_for_variant.py: divides a bus line into sections (consecutive stops), which is then used as input for the performance process model calculations.
layer_from_disco_model_performance.py: transforms a Disco performance process model (XML) into a QGIS layer using the legs_for_variant output layer as input.
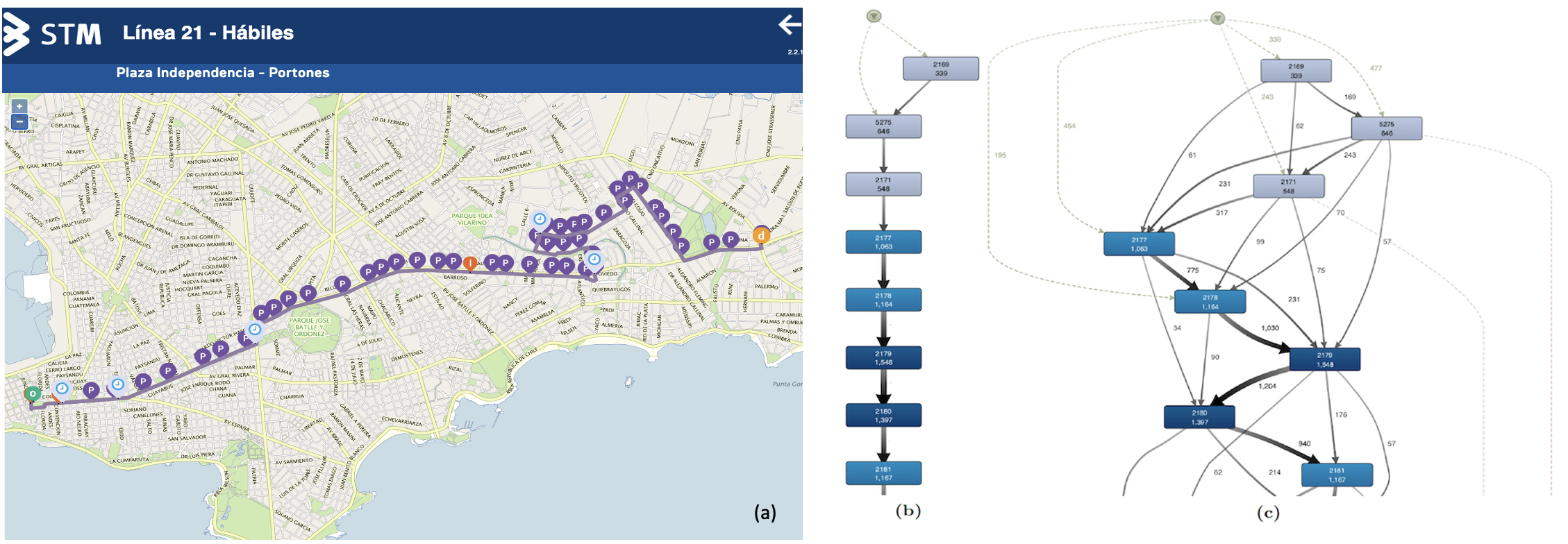
To illustrate the process in QGis and its results, we use the bus line 21 route that we show in Figure 7 for the 7488 variant: a) the bus line in the map taken from the STM schedules site, and b) an excerpt of the STM trips within its frequencies, which is the one we import in QGis. This bus line goes in one direction from Independence Square (the entrance of the old city) to the east, parallel to the coast, and ends in the Portones Shopping Center in the Punta Gorda neighborhood. It has extensions of the route to the old city (left) and to the entrance of the Canelones Department (right).
Fig. 7: Bus line 21 route with stops for the 7488 variant: a) in the STM website Bus schedule, b) excerpt of the reference model, and c) excerpt of the STM trips within its frequencies
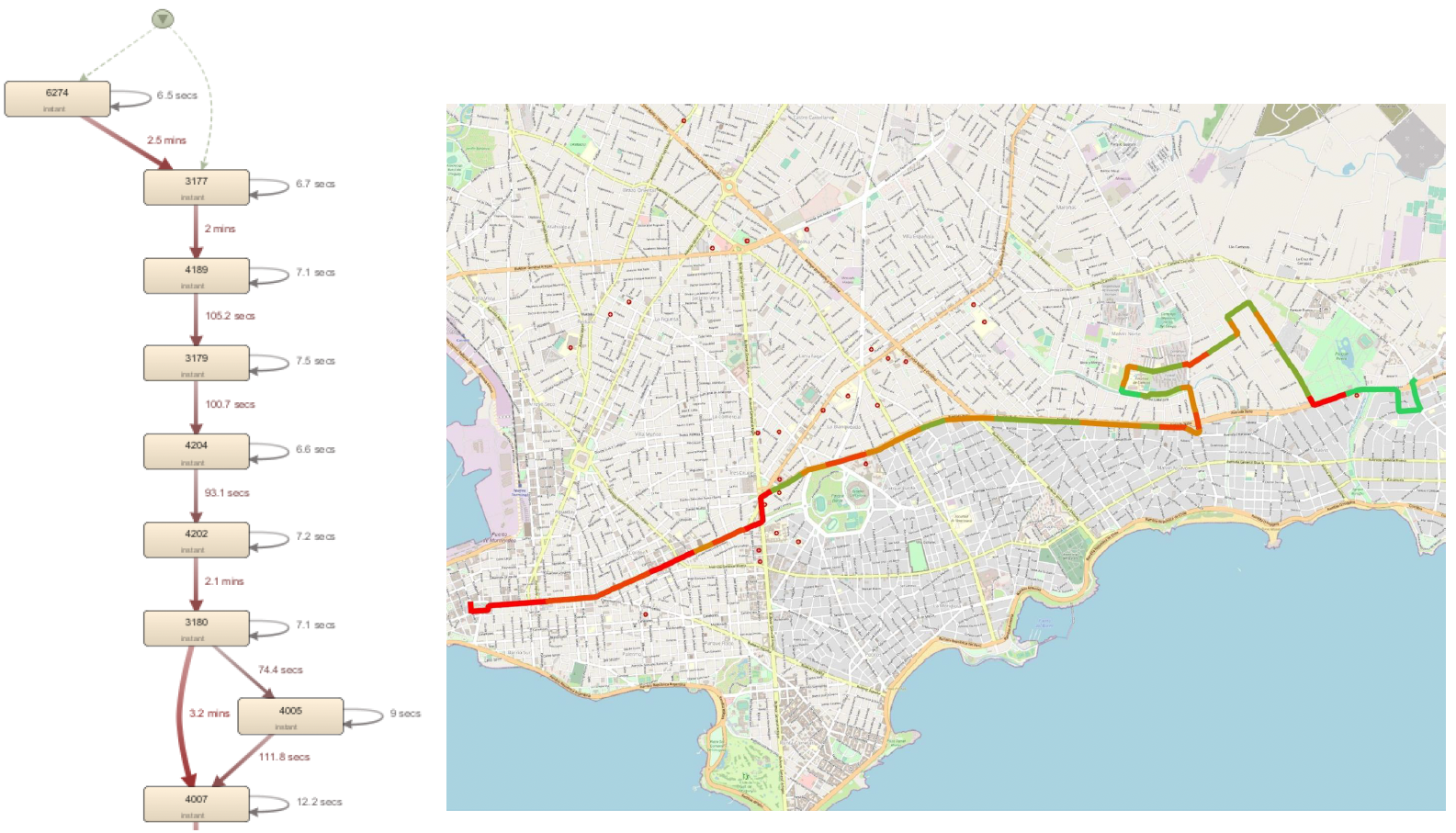
The process model exported from Disco corresponding to Figure 7 c), and transformed into a QGis layer can be seen over the Montevideo city map shown in Figure 8, with zoom over the first sections (left). It can be seen that differently to the ones presented in Figure 7, a) and b), it has arcs that traverse over non-consecutive stops, which reflects, as we mentioned, the actual trips over the bus line route, where in some frequencies, no passengers are getting into the bus in some stops.
Fig. 8: Process model flow view exported from Disco discovered from the STM trips actual data for the 21 bus line route and variant 7488 deployed over Montevideo city map
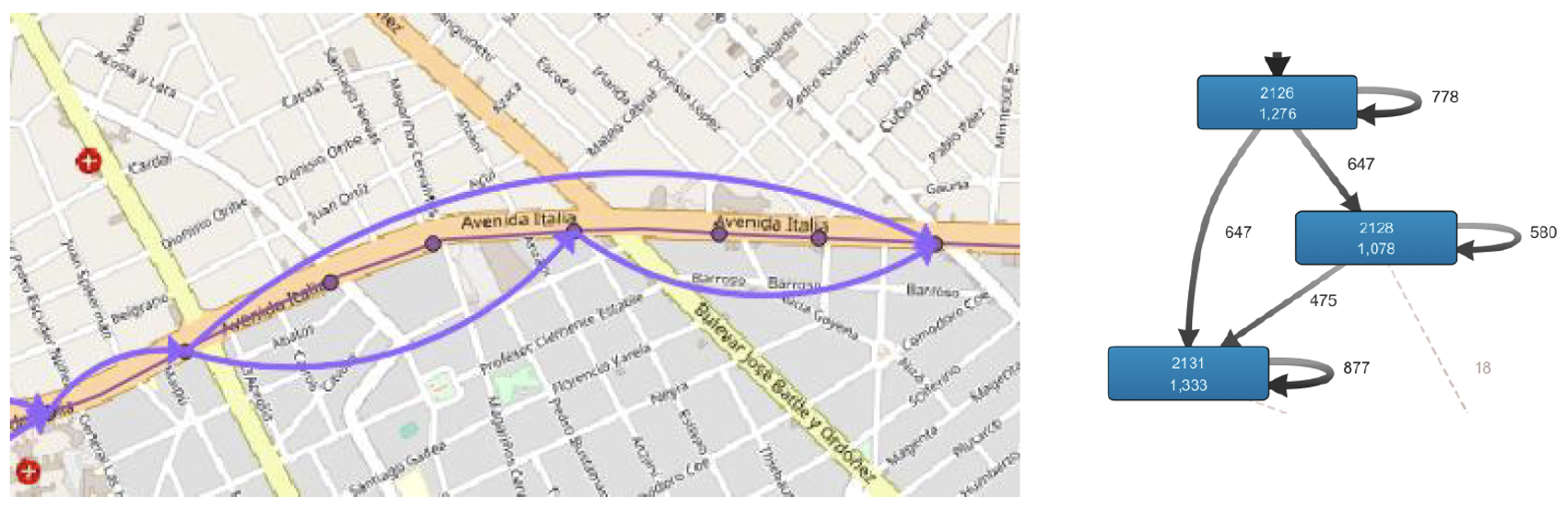
Zooming again on the upper-right corner flow, we can see the details of the process model flow in Disco and the corresponding process model deployed over the city map, as shown in Figure 9: a) the process model in the city map, and b) the process model flow in Disco. It can be seen that stop 2126 goes over the left in the map, stop 2131 goes over the right, and stop 2128 goes in the middle, with the flow to the right. If the two views of the model are compared in Figure 9 a) and b), the difference is noticeable. The map gives a much greater context, allowing one to quickly know the exact location of the activities (stops in this case), the corresponding area, and the neighborhood, allowing one to relate the generated model to information not included.
Fig. 9: Zoom of the process model of the bus line 21 route upper-right corner flow and correspondence with the Disco process map
In this case, we could further investigate why, on several occasions, no passengers are getting on the bus at stop 2128. Some causes could be the following: the stop infrastructure is worse than other nearby stops, there are security issues in the area, and it is mainly used by specific groups of users (e.g., students) within input and output hours of the school.
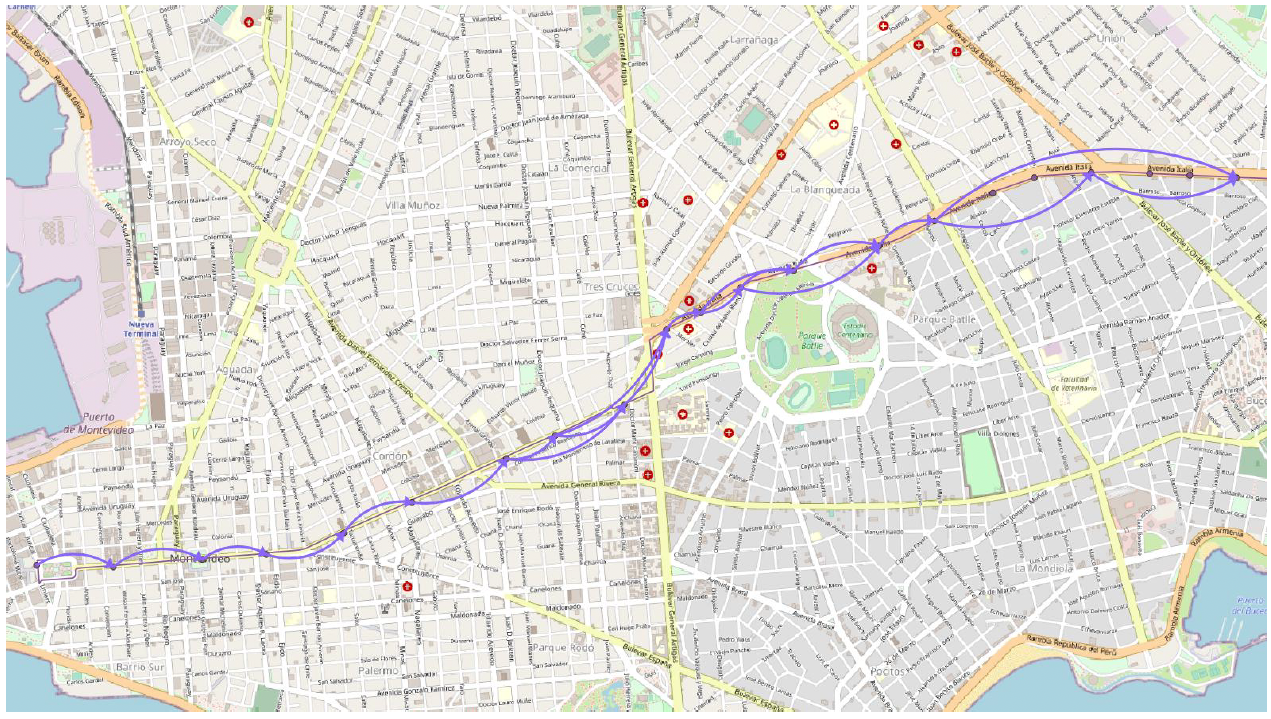
The performance process model exported from Disco corresponding to Figure 7 c), and transformed into a QGis layer can be seen over the Montevideo city map shown in Figure 10: a) the model exported from Disco with delays in transitions between the stops, and b) deployed in the map showing sections delays using the semaphore metaphor: green, yellow and red for more significant delays.
Fig. 10: Performance process model for the bus line 21 route from the bus actual trips data: a) the model exported from Disco with delays in transitions, and b) deployed in the map showing sections delays
Again, as in Figure 8, being able to visualize the specific sections of the bus line that present the worst times over the bus line route in the map, provides a much greater context, allowing to identify the zone at which the sections belong quickly. In this case, it can be seen that the section to the left that goes from the Centenario stadium (round green space marked in the middle below the bus line) to the old city presents the worst delays. This is consistent with that zone being bustling over Avenue Av. Italia, passing through the Three Crosses bus terminal and traversing from start to end the main center avenue Av. 18 de Julio towards the old city entrance (Independence Square).
Conclusions and reproducibility for other cities
We have presented a case study on the application of process mining to analyze urban mobility open data from the STM transport system in Montevideo, Uruguay. We showed how, using Disco, we can discover the reference process model of bus lines using the stops defined for each one and the actual STM trips process model that shows the actual behavior of bus lines regarding passengers’ use within the different frequencies (actual trips) of the buses.
Due to the interest of business people in this specific domain who normally visualize and analyze data over the city map, we developed a prototype that, using the process model export feature of Disco in XML format, allows us to import them into the open-source geospatial software QGis, deploying them over the city map of Montevideo. This provides much greater context to users, as discussed in the previous section.
Regarding reproducibility for other cities, exporting the process models to Disco, importing the layers for the stops and bus lines routes over the city map, and generating the QGis layers for the process models can be applied straightforwardly. For the scripts to work, the process models to be exported from Disco should use as activities the stops of the bus lines, and the files containing the shapefiles with geospatial data of the stops and bus lines routes should be available. The city map layer is loaded as an XYZ layer directly in QGis, available for all cities. The data and format are available from the bus actual trips system of the desired city (i.e., the records of the passengers’ trips) and should probably have to be manipulated to provide the same fields that we used (e.g., bus line, variant, stops to relate to the shapefiles, etc.), or the scripts can be adapted to the data provided by the system under analysis.
The scripts and data are publicly available9 for further experimentation and analysis.
References
[1] Delgado, A., Calegari, D., Process Mining for Improving Urban Mobility in Smart Cities: Challenges and Application with Open Data, 56th Hawaii International Conference on System Sciences (HICSS-56), Maui, Hawaii, USA, Scholarspace, 2023. https://hdl.handle.net/10125/102846
[2] Rodao, B., Carignani, N., Ferreira, S., Minería de Procesos para el análisis de movilidad urbana. Tesis de grado. Universidad de la República (Uruguay). Facultad de Ingeniería, 2023. (In Spanish) https://hdl.handle.net/20.500.12008/42549
This year’s Process Mining Camp will run for two full days — Fire up your calendar and block 13 and 14 June 2024 right away!
Since the beginning, we have always been making changes and improvements to the way we run camp. This year, however, we took a big step back and thought about what we can do so that you can get even more out of camp.
You are a dedicated practitioner who is serious about process mining. You want to improve your craft and skills, and level up in your mastery of process mining. At the same time, you want to have deep, meaningful interactions and connect with the global process mining community. This year’s camp is tailor-made for you, the process mining expert!
More time to connect
When you are all on your own, it is easy to walk in circles. You run the risk of getting stuck or drawing the wrong conclusions. Talking to others can snap you out of an impasse and save you a lot of time that you would have spent figuring everything out by yourself.
Meeting other process miners has always been the main feature at each year’s camp. But having just a few minutes over coffee between talks is not enough to get to know each other.
At this year’s camp, you will have two complete days and an entire evening to connect with your process mining peers. At the end of camp, you will have talked to, and know, everyone!
Workshops take center stage
Process mining looks like magic. However, it is, in fact, a craft that you need to develop in your organization. For this, learning and practice are essential.
Our previous workshops at camp were relatively short, and you had to pick one of them. At this year’s camp, we will have a full day of workshops that cover all the important angles of applying process mining.
You will participate in a program of three hands-on workshops that fit together perfectly. These workshops are designed to supercharge your learning by working on concrete, realistic scenarios that you can normally only get from real-life experience.
Discussion roundtables
We all have different perspectives, and we benefit by considering these different angles. At this year’s camp, you will be part of the discussion and contribute your own experience.
We start by collecting challenges and ideas in small groups of up to eight people. The results of these discussion roundtables are then shared with the whole community. They will set the theme for the rest of camp: Throughout these two days, we will sharpen these challenges and their solutions together.
Boot Camp
We want this year’s camp to be a great experience for you, especially if you already consider yourself an advanced process miner. Of course, we also made sure that, if you are still on your way there, process mining camp will help you fill your gaps.
However, what do you do if you are a process mining greenhorn?
For the first time, we offer an optional boot camp training for those who are just starting out with process mining. In two sessions, one week before camp and at the beginning of the first camp day, you will learn all the basics that you need to follow the discussions and start practicing yourself.
Keeping It 100
We are revamping camp in a major way. At the same time, we also want to hold on to the things that have always made process mining camp so special.
No-nonsense practice talks. Process mining professionals from a variety of industries tell us about their projects in honest practice talks. The camp speakers do not only tell success stories but really show what they did. They will also share what did not work for them and what they have learned. If you have never been to camp, you can watch the videos from previous camps here.
Process mining for professionals. Camp is from practitioners for practitioners. No academic weeds, no sales show, and zero hype. Technology is fascinating, but we are not using technology for technology’s sake. We are all singularly focused on creating value for our organizations. Process mining camp, in its essence, is thoroughly pragmatic.
Our annual family meeting. Over the years, thousands of process mining enthusiasts from more than 34 countries have joined camp. You are going to meet people who apply process mining in their daily practice in completely different contexts. They will help you put your own challenges into perspective. Enjoy the friendly atmosphere, and meet old and new friends from all over the world!
See you at camp!
So, this year’s camp will run for two full days. It will go deeper, and it will be more practical than ever. In addition to the camp talks as you know them, we are adding discussion round tables to inform and guide camp. And we have a complete second day with an integrated program of three workshops, so that you can be sure to advance your process mining skills.
Clearly, we are asking more of you. The price tag is higher simply because it costs more to put this type of camp together. And you are committing two days of your time. But you are going to get so much more out of it!
You will get:
A hands-on process mining practice that you can get only here
New skills and knowledge that you can apply right away
Feedback on your own challenges and data sets
A perspective on where you stand and where to turn to next
Face time with process mining experts
Deep and extended exchange with your peers
Personal connections that will help you way beyond camp
In last week’s Process Mining Café, we talked about Human Resources (HR) processes. Alex Cheremukhin, who used to be the Global HR Transformation Programme Manager at a British multinational, shared his experience.
There is a lot of variability in Human Resources (HR) processes. This is only natural as people are different! And there is different legislation in different countries, different types of benefits, etc.
We show two approaches for dealing with this complexity: (1) One approach starts with the raw data from SAP HR, and we map the data to the process level in a bottom-up way. (2) The second approach is broader and takes a top-down view using the APQC standard process framework, making it possible to look at interactions and flows across different processes. Alex shows this based on a Workday example.
You can now watch the recording here if you missed the live broadcast or want to re-watch the café. A big thanks to Alex and all of you for joining us!
Links
Here are the links that we mentioned during the session:
You are reading Flux Capacitor, the company weblog of Fluxicon. Here, we write mainly about Process
Mining, the things we're up to, and anything really.
We make Disco, the most powerful, user-friendly, and popular process mining
software in the world. You should check it out and download your free demo version
here!
Whether you are a beginner, or an experienced process mining practitioner — you may want to join
one of our popular Process Mining Trainings, given every
few weeks by experienced guides. We hear they're pretty great.
And if you're more the book worm type, go and read your heart out with our brand new Process Mining Book, which has everything to get you started
and much more!