
In edition 5 of our series on typical process mining data preparation tasks we showed how you can remove repetitions from your data to create more meaningful variants. We presented a solution that identifies the repetitions in Python. Rens van den Bos from the TU Delft contacted us with another solution that does the same in Excel. Since Excel is going to be an easier data transformation tool for many of you than Python, we want to share his solution with you here as well. Thanks, Rens!
The example that we used to illustrate this transformation is the 2016 BPI Challenge process (see image at the top). The data set consists of the steps that people follow to apply for unemployment benefits. Each step is a click on the website of the unemployment benefit agency.
What you can see in this process map is that there are a lot of self loops (highlighted by the red rectangles in the image). These repetitions come from multiple clicks on the same web page. They can also come from a refresh, an automated redirection, or an internal post back to the same page. So, they are more of a technical nature than an actual repetition of the same process step.
As a result, these repetitions are not meaningful for analyzing the actual customer experience for this process. What is worse, these repetitions also create many more variants than there actually are from a high level process perspective.
So, here is how you can remove these repetitions in Excel rather than in Python as in our original article.
Step 1: Sort the data in Excel
In order to determine if an activity is a repeating activity, the data set needs to be sorted based on the caseID and the timestamp first. In Excel you can perform a ‘custom sort’ and select the columns and the order in which they need to be sorted. Here, we first sort the data based on the caseID and then sort the events in the order of their completion time (see screenshot below).

Step 2: Add column using Excel formula
Then, we determine for each event whether it is a repetition. A repetition occurs when an activity is preceded by the same activity within that case. As in our previous approach, repetitions are not immediately deleted but just marked by a new data attribute that allows us to filter out repetitions in the process mining tool. This way, we preserve the original data.
To detect whether an event in a row is a repeating activity, one needs to look at the previous row and determine if the caseID and activity are the same. This can be translated into an Excel formula as shown in the screenshot below.
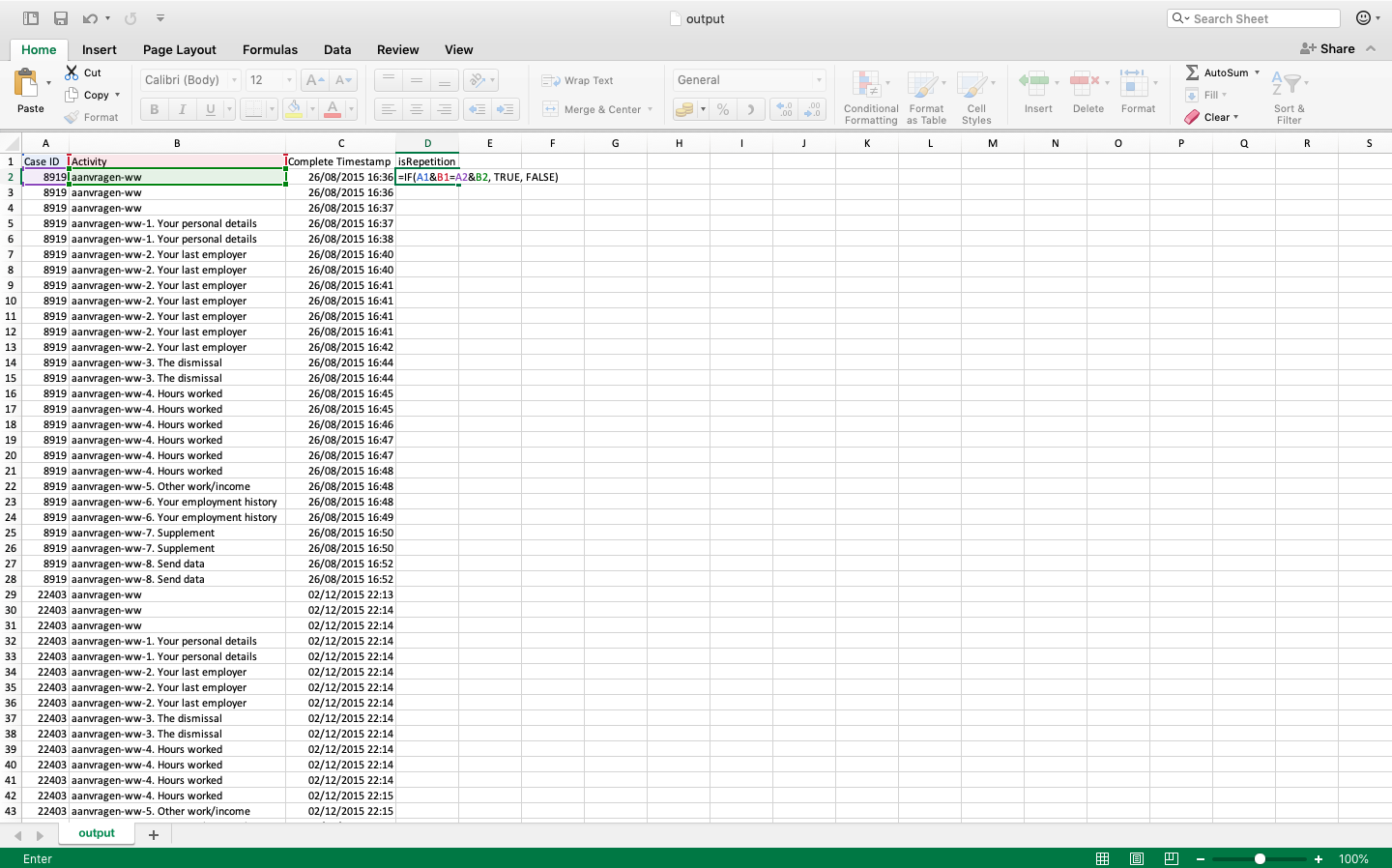
Once you apply this formula to the first event in the data set, you will see the value FALSE because the first event is not a repetition yet.

If you now double click on the bottom right corner of the cell with the formula (see the green little square in the lower right corner in the screenshot above), then the formula is automatically applied to all the rows in your data set.
If everything works, the formula is now applied for every event and, for example, the second event in case 8919 is shown as TRUE because it is a repetition of the previous event (see below).
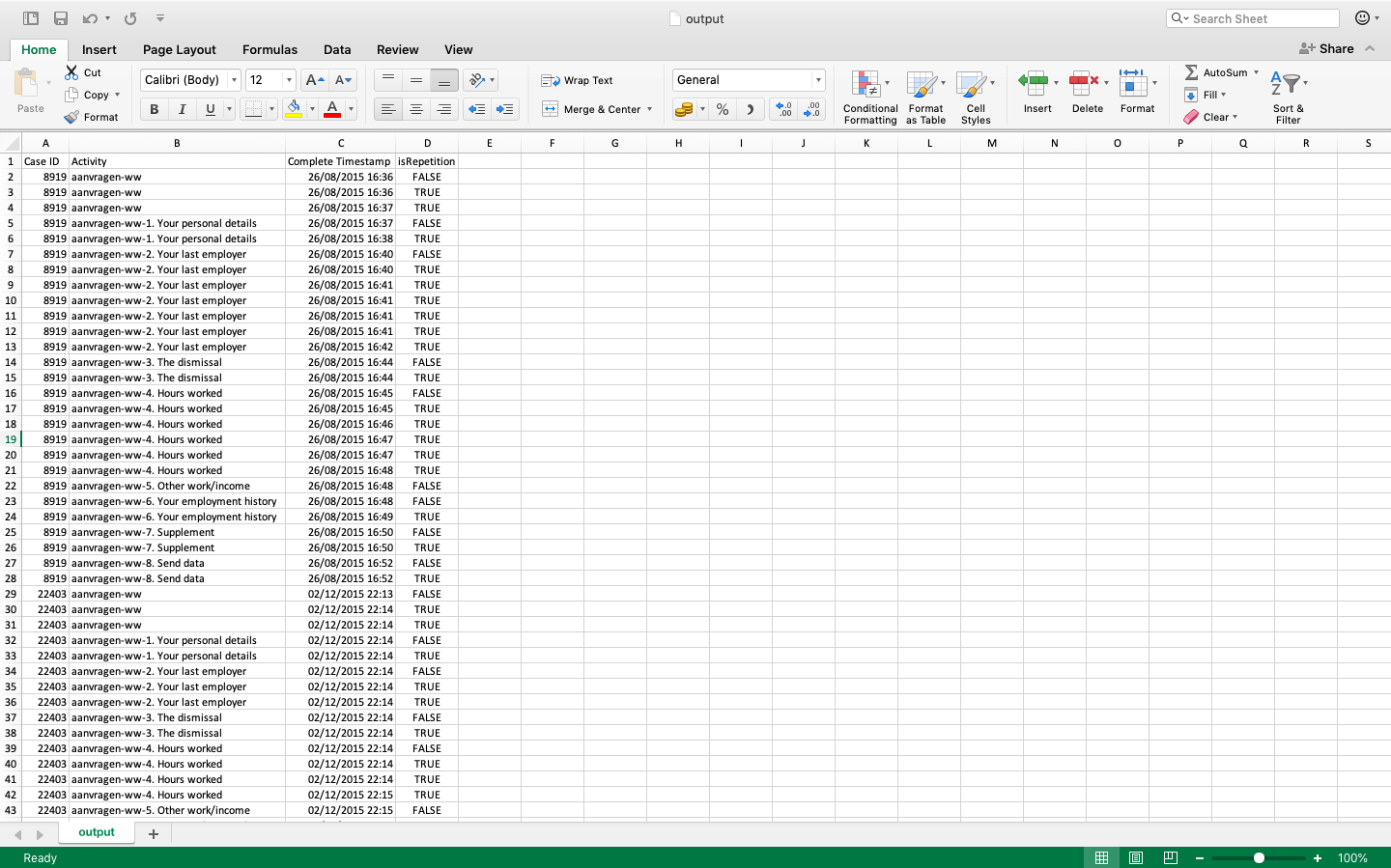
Make sure that you save the resulting file as a CSV file before you import it into Disco, so that the results of the formula will be saved as values that can be read as an attribute value. To do this, use the ‘File -> Save As’ menu function in Excel and choose ‘CSV’ as the File Format in the export step.
To follow the last steps of actually analyzing the data without repetitions, read onwards from Step 3 in the original article here.

Rudi Niks
Process Mining and everything else
Rudi has been a process mining pioneer since 2004. As a Process Mining expert and Lean Six Sigma Black Belt, he has over ten years of practical, hands-on experience with applying process mining to improve customers’ processes. At Fluxicon, he is sharing his vast experience to make sure you succeed.