
Finding the right perspective of the process is one of the challenges you can face when applying process mining. In most cases we already have an idea what we would expect of the process, but in some cases its not so easy to find the right perspective to be able to get valuable insights.
At Process Mining Camp in June 2019, Hadi Sotudeh, a PDEng student at Jheronimus Academy of Data Science (JADS), shared his experiences to apply process mining to the World Cup 2018 dataset. He now wrote down his analysis in this article and is also interested in any thoughts or feedback you may have. You can reach him on Linkedin or via email.
If you have a guest article or process mining case study that you would like to share as well, please contact us via anne@fluxicon.com.
The data set
What has football to do with process mining? Nothing at all, but I noticed that the Statsbomb dataset (see Figure 1) fulfilled the requirements to at least try1. I was especially interested in how a football team possesses the ball on the pitch. Being able to answer this question, I would be able to give coaching staff great insights into interesting patterns of play to develop counter strategies.

Figure 1: An example fragment of the Statsbomb data set
First, we need to introduce the ball possession process:
Ball possession process is a sequence of on-ball actions taken by one team from the beginning of possession until the end of it (losing or scoring).
For example, in the video above the ball possession starts from the defenders and after several actions on the ball, such as passes and dribbles, the forward player loses to score. This ball possession sequence has happened in the match between Iran and Portugal in the World Cup 2018. This sequence with its most important attributes after preprocessing the data set is shown in Table 1 (click on the image to see a larger version).
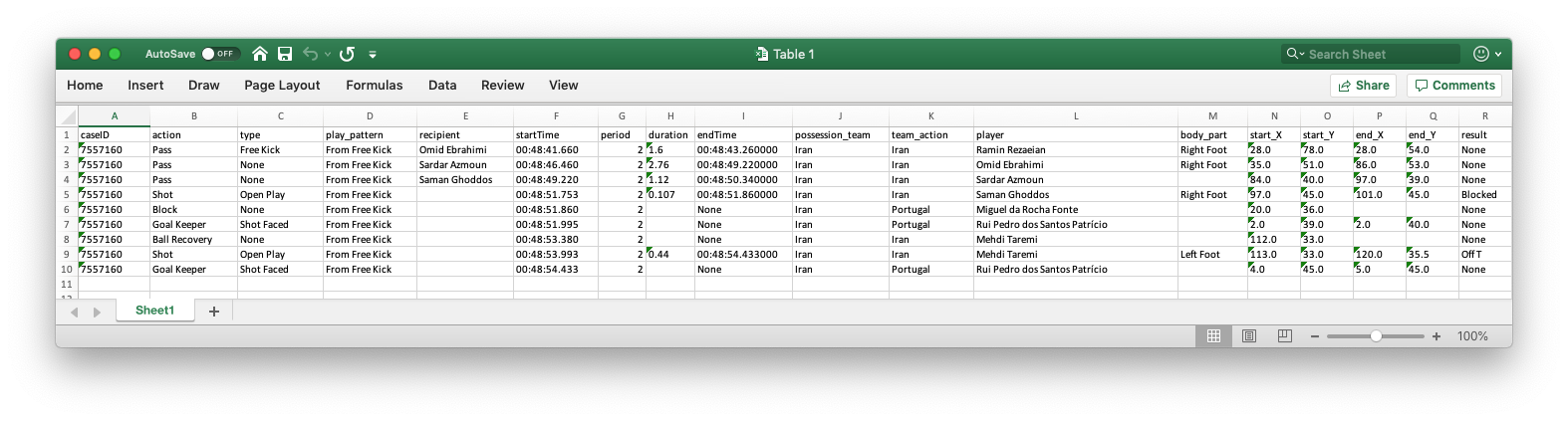
Table 1: The recorded ball possession sequence in the data set
As shown in the table above, this ball possession sequence has attributes such as:
- case ID: all actions in a ball possession sequence have the same case Id
- action: name of the on-ball action such as pass and pressure
- type: type of ball action such as Free Kick, Open Play, Shot Faced
- play pattern: each sequence has one play pattern such as “Free Kick” and “From Corner”
- recipient: the receiving player
- start Time and end Time: start and end time of the action
- period: which half of the match
- duration: duration of the action
- possession team: the team in ball possession
- team action: the action-taking team
- player: the action-taking player
- body part: the body part of the action-taking player
- start_X and start_Y: the start location of the action on the pitch with respect to a reference
- end_X and end_Y: the end location of the action on the pitch with respect to a reference
- result: the outcome of the action
The preprocessed process mining datasets of the World Cup 2018 can be downloaded here per match and aggregated per team.
We chose Belgium (see Figure 2) to analyze their ball possession process because they had seven matches and this, of course, will provide a richer dataset.
Mapping the ball possession process

Figure 2: Belgium in the World Cup 2018
To map the ball possession process, we need to think about how to assign the three process mining parameters case-id, activity and timestamp. The ball possession sequence number was already chosen as our case-id. Then, the on-ball action was initially taken as the activity, and the start time of the action was chosen as the timestamp. After importing the dataset into Disco, all the activities and the most important paths are shown in the discovered process map (see Figure 3 - Click to enlarge).
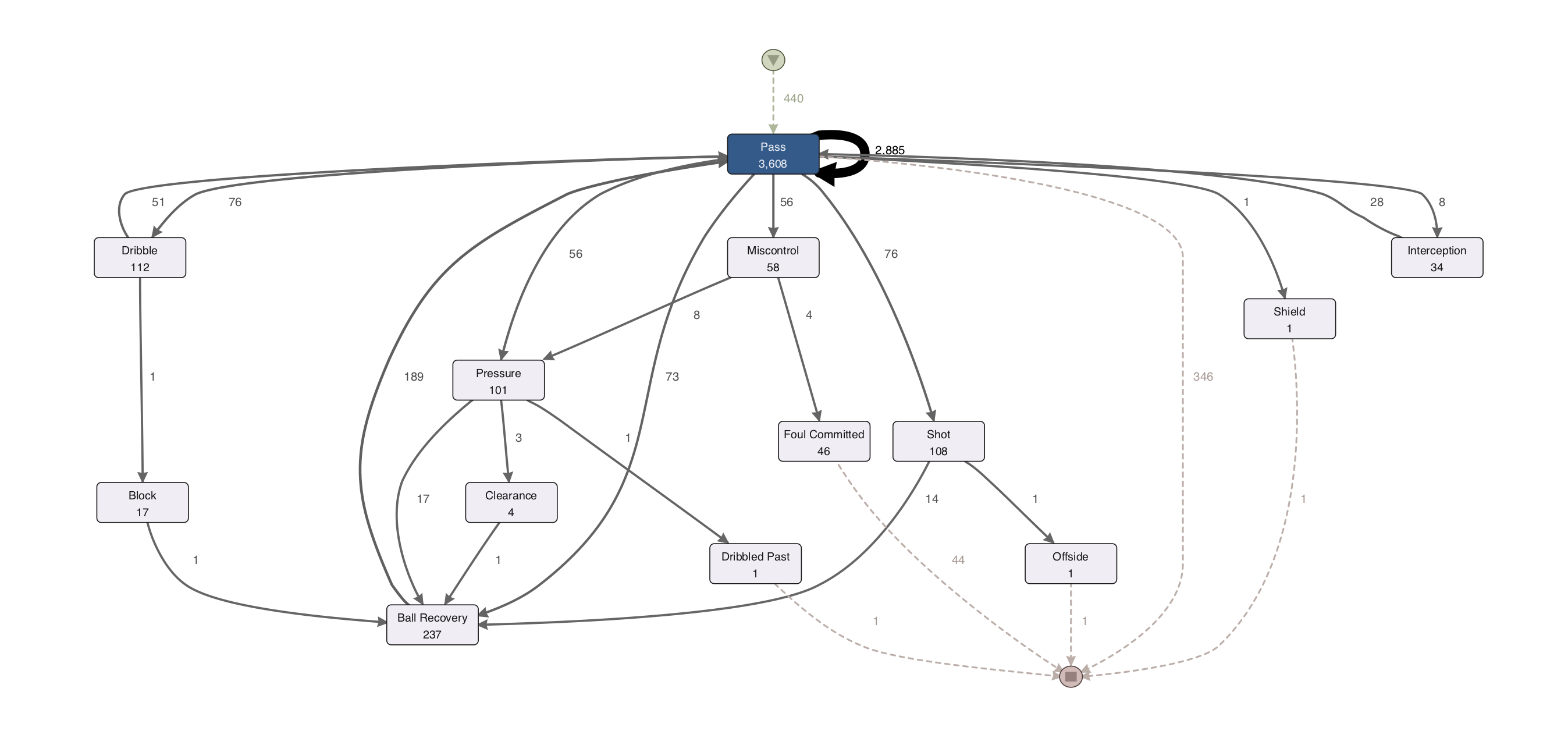
Figure 3: All activities in the ball possession process with the most important paths
Figure 4 is showing the ball possession process for 594 cases with 295 variants. The first variant includes 48 cases (only one pass), the second variant includes 38 cases (2 passes), and the third variant includes (3 passes).

Figure 4: Top three variants of the ball possession process
The players as activities
We can also have another perspective on the process by taking the players as activities and see the way they interact on the pitch, see Figure 5.

Figure 5: Belgium top 11 players interaction during the ball possession process on the pitch with most frequent interactions
Belgium players interaction on the pitch has 594 cases with 525 variants, see Figure 6.

Figure 6: Top three variants of Belgium players’ interaction during the ball possession process on the pitch
The top first variant includes 10 cases where Kevin De Bruyne was involved in the sequences with only one action. The second and the third variants also have one action but taken by different players, Jan Vertonghen and Thibaut Courtois respectively.
Unfolding loops
If we look back at the first perspective, where we mapped the on-ball action as the activity in the process (see Figure 3 above), we can see that there is a very dominant self-loop on the Pass activity (see Figure 7 below).

Figure 7: Self-loop in ‘Pass’ activity
The collapsing of repetitions into loops is useful in most situations, but now we want to dive deeper into the ‘Pass’ patterns. To do this, we need to “unfold” this loop.
We applied the unfolding technique described in this article. This simply means that we change a sequence from Pass, Pass, Pass (which will be collapsed into a single ‘Pass’ activity with a self-loop) to Pass1, Pass2, Pass3 (which will be shown as a sequence of ‘Pass’ activities after each other).
After adding the repetition number in the python script, we import the data back into Disco by choosing both the on-ball action as well as the newly added sequence number of the repetition as the activity name. The full process map (100% activities and 100% paths) is shown in Figure 8.

Figure 8: Complete unfolded process map
As one would expect from a football game, the process map is very complicated. By only focusing on 50% of the activities and the most important paths, we get a readable process map that we can now further analyze (see Figure 9).

Figure 9: Unfolded process map with 50% of the activities and the most important paths
Distinguishing different types of ball possession
In another exploration, we want to focus on sub processes inside the ball possession process. In a football match, ball possessions can have different types such as from goalkeeper, from corner, from free kick, from throw in, etc. It is obvious that the process should be different in a corner than a start from a goalkeeper.
We concatenate the type of the sequence with the on-ball action as the activity name to make it easier to focus only on interesting subsets of the map based on this added dimension (see Figure 10 - Click on the image to see the full picture).

Figure 10: Subprocesses of the ball possession process with the type of sequence dimension
The coaching staff can create a filter on cases that are not set-pieces such as corner, and free kicks, to only focus on the parts that they are interested in.
Another application of process mining is that the coaching staff can go to the case explorer and see which undesired sequences have happened on the pitch to identify irregular patterns that need to be prevented (see Figure 11 and 12).
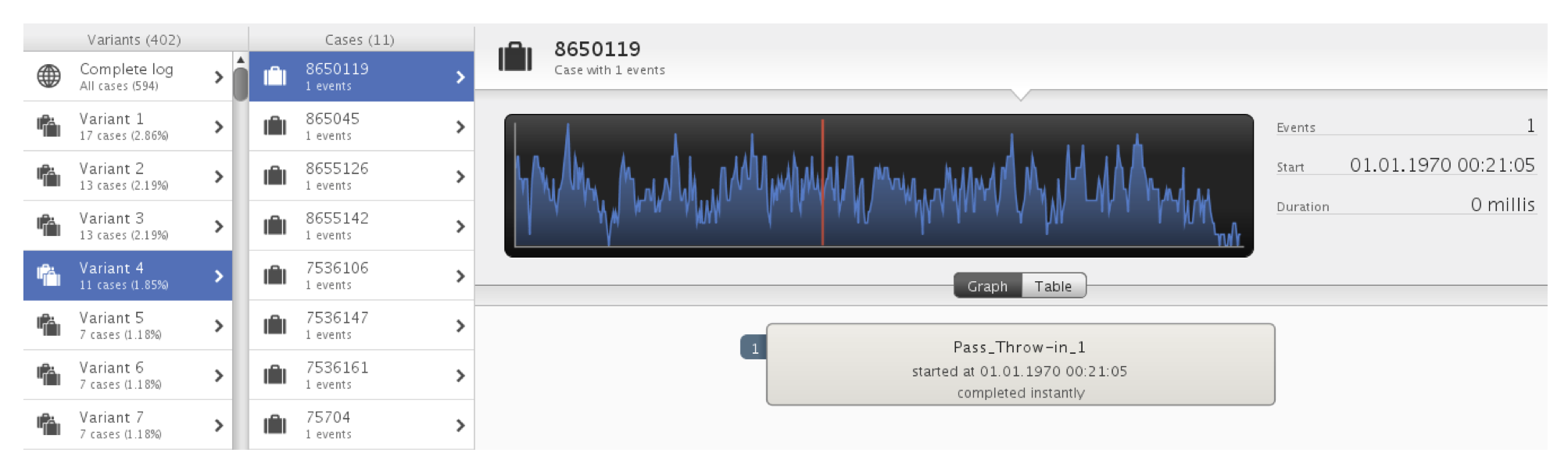
Figure 11: Exploring undesired sequences

Figure 12: Finding players involved in those sequences
By exploring the variants one by one on the left-hand side of Figure 11, we can see that there are 11 sequences that had only one ball-action (Pass_Throw-in-1). Let’s only keep these sequences by filtering them and drill down to see what is the reason.
Figure 12 shows us a picture of different players and how they performed on the selected sequences. For example, Jan Vertonghen was involved in five sequences out of 11 that ended after throwing the ball in. We can select those sequences and drill down to see what has happened (see Figure 13).

Figure 13: An example of a ball throw-in sequence that Vertongen was involved in
By selecting each case, we can see what the other attributes of that sequence are. For example, one of the sequences happened against Panama and belongs to the second period and 73rd minute. Now, we can connect the event-log to the match video and see what has happened on the pitch.
Here, we can now go to the exact time and watch that frame carefully.
As you can see, Vertongen tried to start the throw-in with a long pass, which was not successful and Panama took the ball possession over.
This way, the coaching team does not need to watch the whole match from the beginning to the end. They will be able to only focus on the interesting pieces and save time. This application is also interesting when your team plays against unknown teams and you as one of the coaching team members will not need to watch all of the opponents matches completely.
Conclusion
After transforming the data, we were able to explore the actions of the players but found that there was not one dominant pattern. We took various approaches to take other perspectives to discover patterns. For example, we were able to look at interactions with individual players. Because the football interactions do not follow a typical (standard) process, finding the right level is one of the challenges to get insights. Taking various perspectives can help to learn new things about the opponent pattern of play, or for a team to learn from mistakes.
As always, it is a good idea to look back and see how we came to this point. When we look back at how we defined the process, we realize that, maybe, we can further redefine the process, right?
For example, one of the next steps could be redefining the process as:
Ball possession process is a sequence of zones where the ball moves in and out on the pitch from the beginning of possession until the end of it.
This view requires defining zones on the football pitch. One example of it is shown in Figure 14.

Figure 14: Dividing the pitch into different zones (activities)
Finding out the right way to divide the pitch into meaningful zones, and relevant questions that we can answer using process mining that are also interesting for coaching staff, is what we can do next.
We have shown that process mining can be a powerful tool to explore football data. However, finding the right perspective to answer questions is not always obvious.
Data can be molded into multiple representations, which in turn allow us to take various perspectives of the process. Finding the right perspective is an iterative process that can be best explored by trying different things.
-
This dataset is provided by Statsbomb for research purposes on their GitHub page. ↩︎

Rudi Niks
Process Mining and everything else
Rudi has been a process mining pioneer since 2004. As a Process Mining expert and Lean Six Sigma Black Belt, he has over ten years of practical, hands-on experience with applying process mining to improve customers’ processes. At Fluxicon, he is sharing his vast experience to make sure you succeed.