![]()
This is the 4th article in our series on typical process mining data preparation tasks. You can find an overview of all articles in the series here.
When you check whether your data set is suitable for process mining, you look for changing activity names and for changing timestamps to make sure that you have activity and timestamp history information. However, when looking for the case ID, you will be searching for multiple rows with the same case ID, because the case ID serves as the linking pin for all the events that were performed for the same process instance.
If you have different case IDs in each row, then this could mean that what you thought was your case ID is just an event ID, or that you don’t actually have multiple events per case in your data set. But more often than not your data set is simply structured in columns rather than in rows: This means that the activity information is spread out over different columns for each case (in just one row per case).
The good news is that you can use such a data set for process mining. All you have to do is to transform it a little bit!
The screenshot below (click on the image to see a larger version of it) shows a data set from a hospital. Patients who are undergoing surgery in the Emergency Room (ER) are first admitted before the surgery (column C), ordered from the department before surgery (column D), enter the ER (column E), leave the ER (column F), and are submitted again to a department after the surgery (column G).
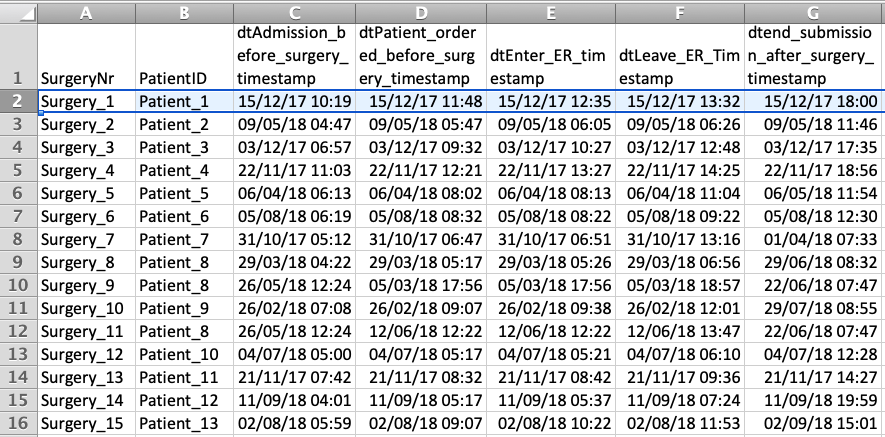
The data in this format is not suitable to be used for process mining yet, because the activity name is contained in the heading of the columns C, D, E, F and G, and the timestamps are in the cells of these columns. Nevertheless, the ingredients are there and all we need to do is to transpose the activity columns into rows.
For this example, the case Surgery_1 for Patient_1 needs to be structured into the following format (see below).

In this article we show you step by step how you can transpose your column-structured activity data into rows. We will first demonstrate how you can do this manually in Excel but then also show how you can scale this transformation outside of Excel for large data sets.
Furthermore, there are choices that need to be made with respect to the timestamps and about how additional data attributes should be represented in the new data set. We will discuss these choices and their consequences for your analysis.
Option 1: Columns to rows with one timestamp per activity
In most situations, you will want to create an event log with one activity per timestamp column (similar to the example above).
To do this in Excel, you can first create a new tab (or a new file) and add a column header for the caseID, timestamp and activity fields. In the hospital process above, both the SurgeryNr and the PatientID field can be used as a caseID, so we have included them both.
Then, we copy and paste the cells of both the SurgeryNr and PatientID fields from our source data into the corresponding case ID columns of the new data set (see below).

Now it is time to add the first activity. So, we first copy the timestamps for the first activity from the dtAdmission_before_surgery_timestamp column into the Timestamp column. We could then use the ‘dtAdmission_before_surgery_timestamp’ column header as the activity name as before but, while we are at it, we have the chance to give a nicer, more readable, name for this activity. Let’s call it ‘Admission’, because this is the admission step of the surgery process. We simply copy and paste this activity name into the Activity column for each cell (see below).

We repeat this for each of the timestamp columns in our source file. So, for the second activity we again add all the SurgeryNr and PatientID values below the previous rows, thereby doubling the number of rows (see below).

Now, we copy the timestamps from dtPatient_ordered_before_surgery_timestamp column to the Timestamp column and fill in ‘Ordered’ as the simplified activity name for these timestamps in the Activity column (see below).

These steps are repeated for each of the activity columns in the original file. Make sure to add the activities in the expected process sequence to avoid the data quality problem of same timestamp activities (especially if you have just dates and no time in your timestamps).
After adding all five activities, the resulting event log has indeed grown five times in the number of rows compared to the initial, row-based data set. For more activities, it will grow even more. This is the reason that even for moderately sized data sets the Excel limit of 1 million rows can be exceeded quickly and more scalable methods are needed (see more on that at the end of this article).
The fully transposed surgery process data set still fits into Excel and can now be exported as a CSV file using the ‘File -> Save As’ menu in Excel. After importing the CSV file into Disco (using both the SurgeryNr and the PatientID as the combined case ID), we can see the process map shown below.
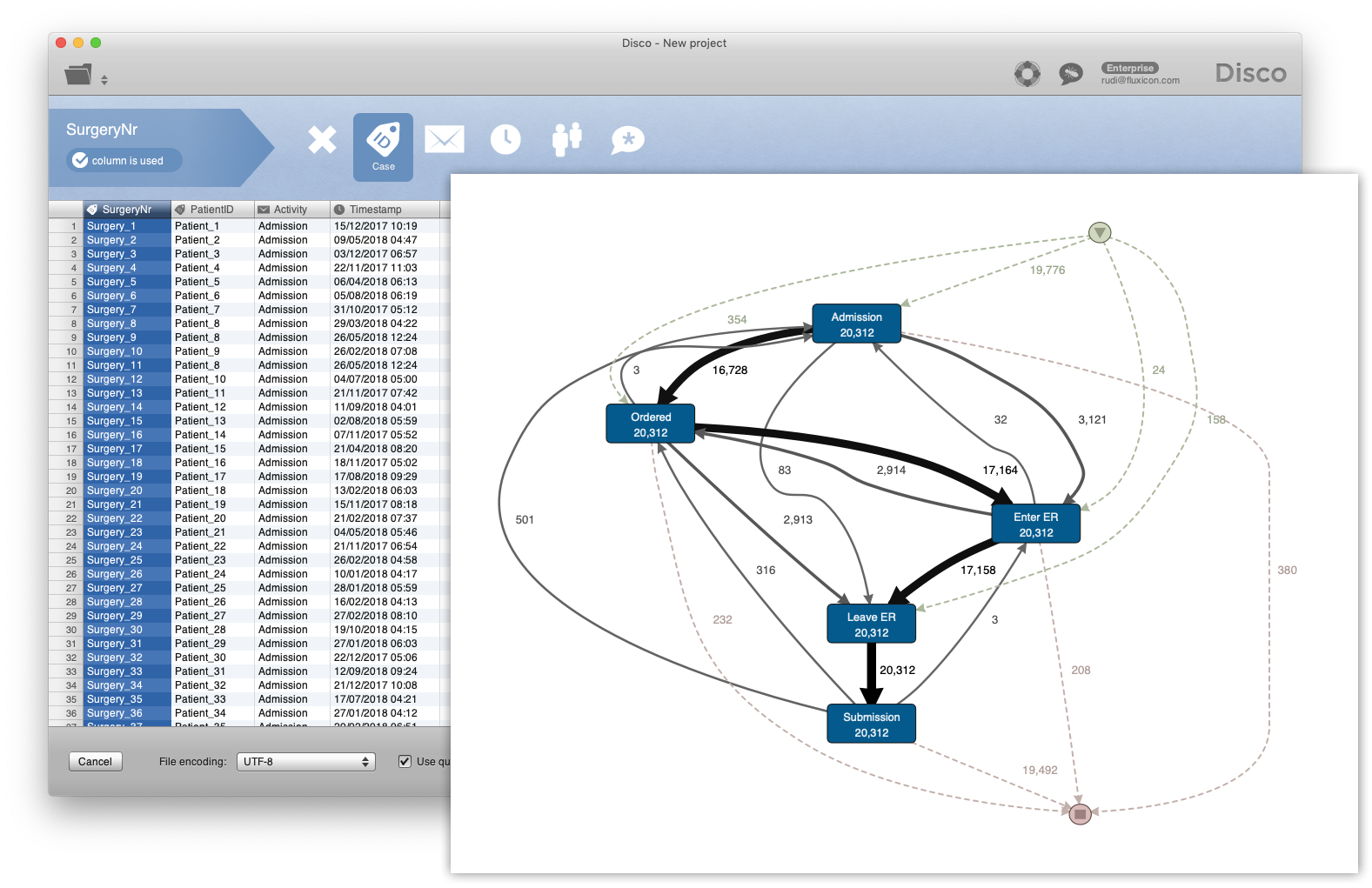
In case you are wondering: The process map has indeed some weird start and end points and some strange connections (see, for example, the path from ‘Admission’ to ‘Leave ER’). Most likely, these are data quality problems due to the manually collected timestamps. Before we analyze the process, we will need to investigate the start and end points as well as validate and clean the data. However, the focus of this article is on the data transformation itself, and the choices in the structuring of the data, before we even get to these two steps.
Option 2: Columns to rows with start and completion timestamp
When we look at the process map from a performance perspective, we can see that the point where the patients enter and leave the ER are represented as independent activities. The duration that the patient is in the ER is shown on the path between the ‘Enter ER’ and ‘Leave ER’ activities (see below).
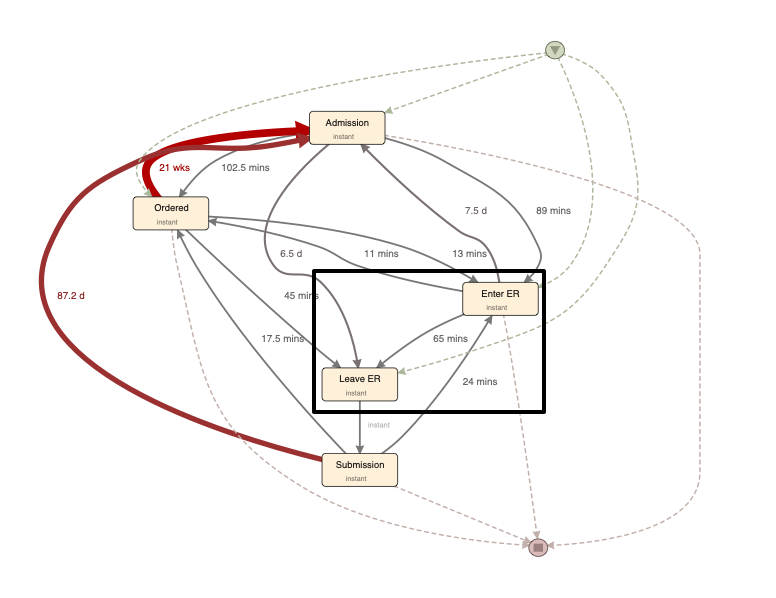
We might prefer to show the process part where the patient is in the ER as one activity (using the entering as the start timestamp and the leaving as the end timestamp for the activity). In this way, the duration of the patient being in the ER will be shown _within the activity _in the process map.
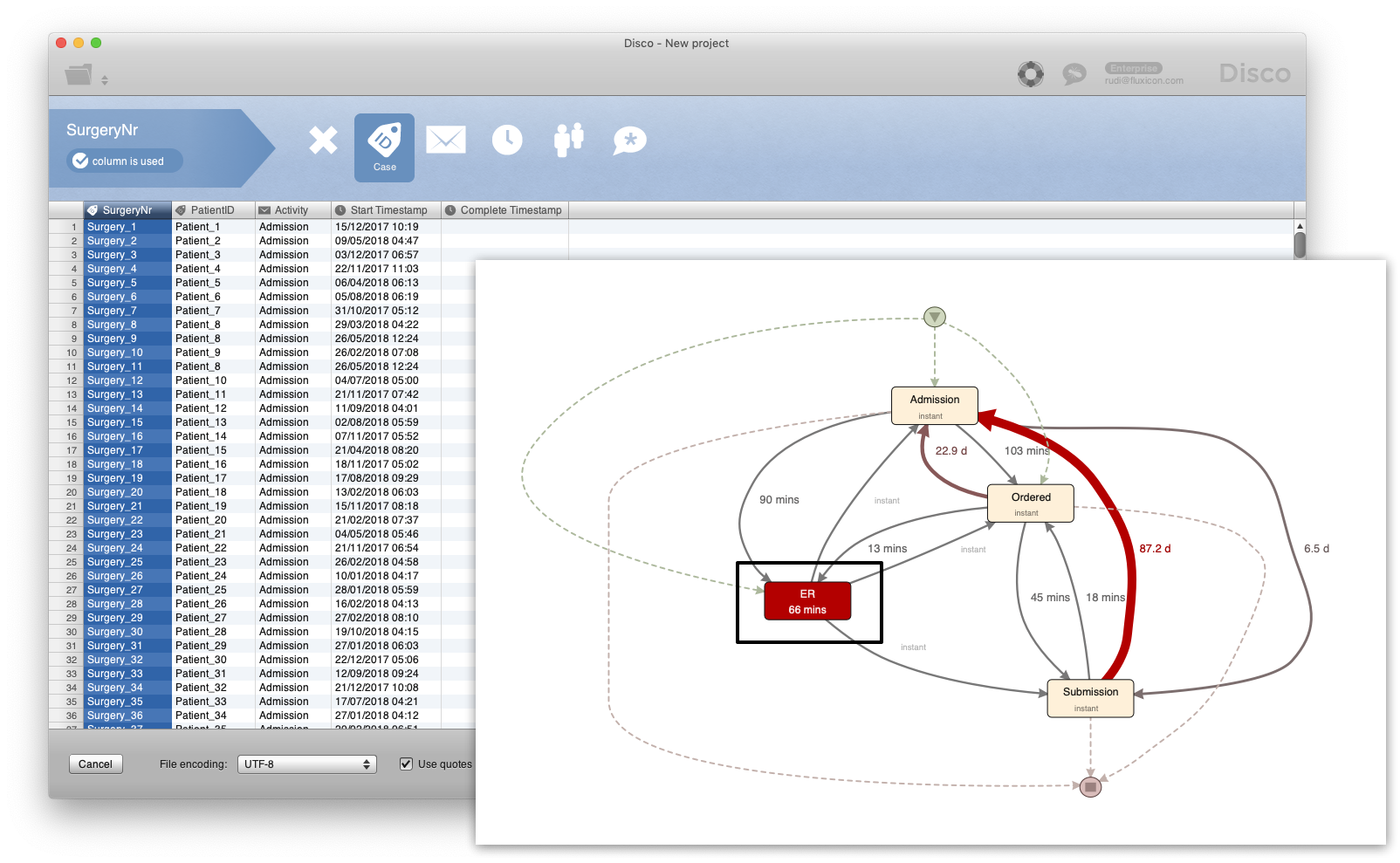
To achieve this, you can follow the same approach as before but copy and paste the ‘Enter ER’ and ‘Leave ER’ timestamps into a start and complete timestamp column for the same ‘ER’ activity (see below).1

The resulting event log is ready to be imported and results into a process map with a single ‘ER’ activity as show below.
Adding case attributes and event attributes
When transposing your data, you typically want to include all additional attributes (columns that were not yet converted into a caseID, activity or timestamp column) to be able to answer certain questions using the filters in Disco or to take different perspectives on your data. When you include an attribute, you need to decide whether you include it as a case attribute or as an event attribute.
A case attribute is constant (not changing) for the whole case. In the surgery process, the diagnosis treatment code is established even before the admission of the surgery and will not change in the course of the process. For example, for Surgery_1 the ‘Treatmentcode’ attribute value is ‘Code_20’ (see below). In our process mining analysis, we can then later filter for patients with a particular treatment code.

In contrast, an event attribute can change in the course of the process and is related to a particular event. For example, the department from which the patient was admitted and ordered can be different from the department to which they were submitted after the surgery. Furthermore, the ER room that was used for the actual surgery is linked only to the ER activity (see an example for Surgery_16 below).

When structuring your attributes, we recommend that, if in doubt, you can best place them into separate columns. This way, you retain the maximum flexibility for your analysis. For example, while the ‘Admission Department’ attribute value and the ‘Submission Department’ attribute value 2 can be both placed in the same ‘Department’ event attribute column, the ‘Room’ event attribute should be kept as a separate column.
We can then analyze different perspectives of the patient logistics. For example, in the following screenshot we have configured the ‘Treatmentcode’ column as an attribute and included both the ‘Department’ and the ‘Room’ attributes as part of the activity name during the import step (see below).
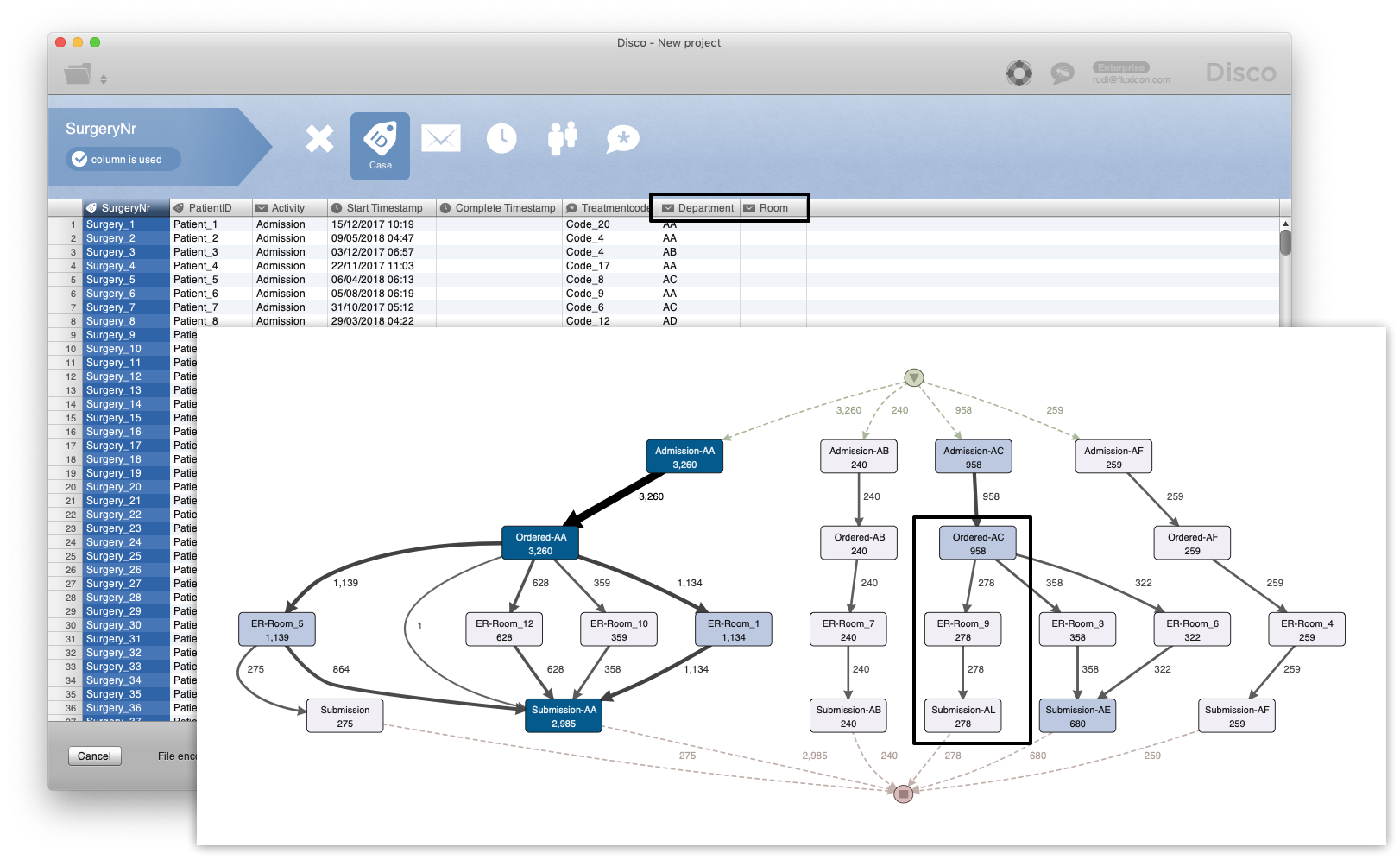
This way, after filtering for the top 15 treatment codes, we can see the flow of Surgery_16 above (from AC department via room 9 to AL department) back in the process map. But we could have also chosen to just unfold the room, or to just unfold the department, or none of them, to take a different view on the process.
Beware of missing repetitions!
So, when you receive your data in a column-shaped format, you should take the data and transform it as described above. But, as we have discussed in this previous article about missing repetitions for activities, seeing the activities in columns rather than in rows should immediately bring up a warning flag in your mind: Most likely you will not be able to see loops in this process.
The reason is that there is no place to put a second timestamp for the same activity, so typically the first timestamp is overwritten and only the last one will be kept. For example, in case 1 in the following data set the first occurrence of activity C is lost, because only the timestamp of the second occurrence of C is stored in the ‘Activity C’ column (see below).
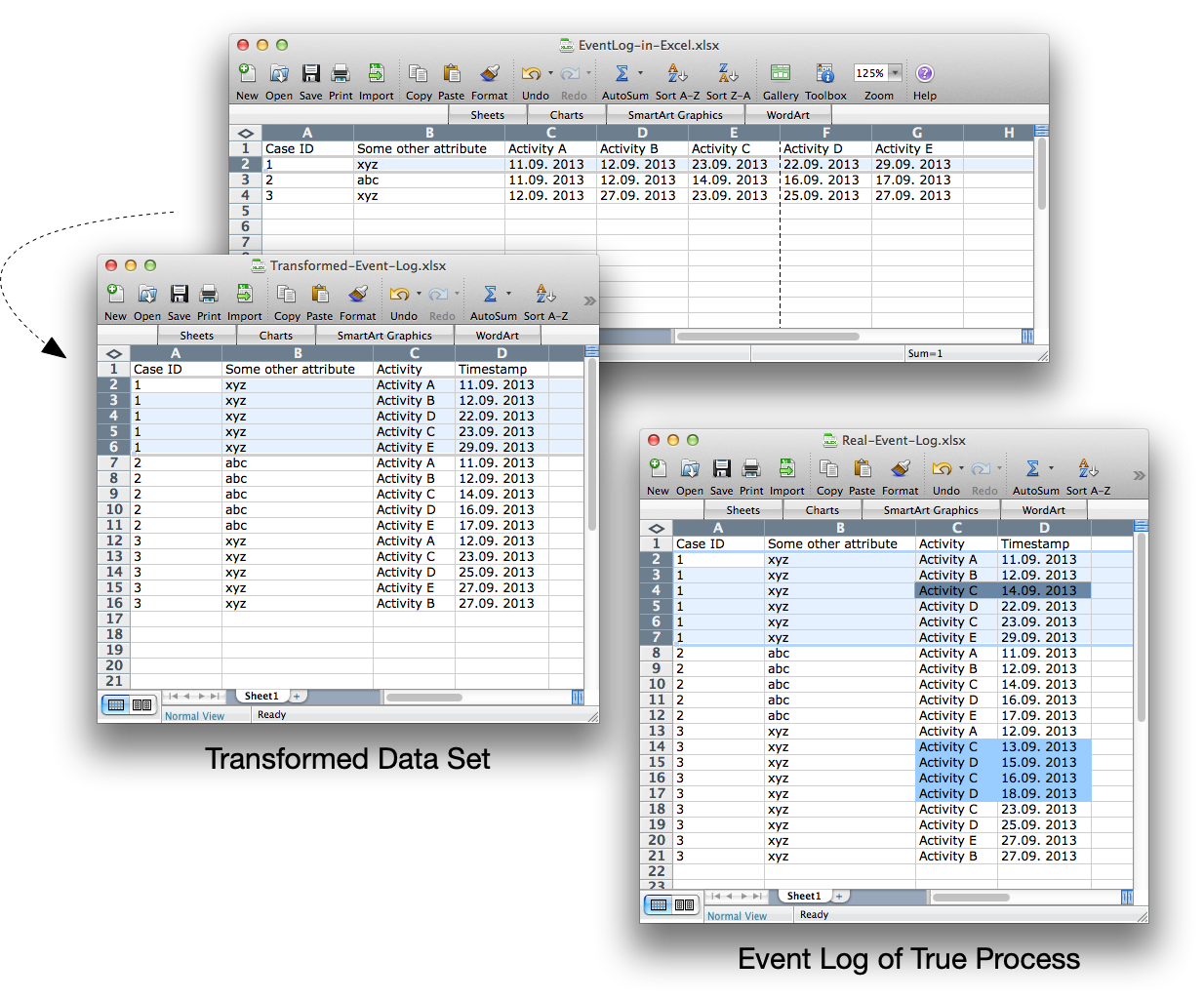
As a result, it looks as if activity B was followed directly by activity D at least once, while in reality this never happened (see below).

There is typically nothing you can do about this data quality problem at that point (you would need to go deeper to recover the activity repetition timestamps from the original data source).
What is important now is that you are aware of the issue and keep it in mind during the analysis to interpret the discovered process maps correctly. By knowing that distortions like the B -> D flow above can be due to the missing loops in your data, you know that you are not seeing the complete picture of the process.
Transpose large data sets in an ETL tool
Finally, transposing your data in Excel can be a good option if you have to do it just once and the data set is not that big. However, as with any manual data transformation, you run the risk of accidentally making a mistake such as copying and pasting the wrong column. Furthermore, especially if you want to repeat this analysis more often, or if your data set gets too big for Excel in the process, an ETL tool can save you a lot of time.
For example, by building an ETL workflow in the open source tool KNIME you can transpose your data with just a few mouse clicks. To transform the data as we have shown manually in option 1 above, we just need three steps in a simple reader -> unpivot -> writer workflow as shown below.

In the first step (here ‘File Reader’) the data is loaded. The second step (‘Unpivoting’) automatically transposes the timestamps from columns to rows. The last block (‘CSV Writer’) saves the result into a new CSV file. You can download this KNIME workflow file here.
The nice thing about building an ETL workflow like the one shown above is that you can use it on really large data sets. And you can re-run it on fresh data as often as you want.
-
Note that in this case you actually first need to clean the data set of any instances where the ‘Enter ER’ timestamp is later than ‘Leave ER’ timestamp, because similar to the case of missing complete timestamps activities with this data quality problem cannot be detected after importing the data anymore. ↩︎
-
Yes, any event attribute values that should end up in the same attribute column will need to come from separate columns in the column-shaped source data. Otherwise, you will have lost the history of those changing attribute values and most likely only see the last one (e.g., the department, where the patient ended up after the surgery). ↩︎

Rudi Niks
Process Mining and everything else
Rudi has been a process mining pioneer since 2004. As a Process Mining expert and Lean Six Sigma Black Belt, he has over ten years of practical, hands-on experience with applying process mining to improve customers’ processes. At Fluxicon, he is sharing his vast experience to make sure you succeed.