
This is the 3rd article in our series on typical process mining data preparation tasks. You can find an overview of all articles in the series here.
In the previous articles, we have shown how loops can be split up into individual cases or unfolded activities. Another typical category of data transformations is that multiple data sets need to be combined into one data set.
For example, you might receive a separate report for all the status changes every month. These files then need to be combined into one file to analyze the full timeframe for this process. Another example would be a situation, where different process steps are recorded in different IT systems. After extracting the data from the individual systems, the files need to be combined to analyze the full end-to-end process.
When you combine multiple data sets into one event log, you need to look at the structure of these data sets to understand how exactly they can be combined. For example, the per-month data snippets need to be concatenated in a vertical manner (copied below each other in the same file).
The same is true if you want to combine different process steps across multiple systems. The assumption is that the activities in the different systems have a common case ID if they refer to the same case in the process. If different IDs are used in different systems, you first need to create a common case ID. Note also that if the timestamp patterns are recorded differently in the different systems, then you need to put them into separate columns when preparing the data.
In this article, we show you three approaches that you can take to combine data from multiple files below each other into a single data set for your process mining analysis.
We use the example of four months of data that has been collected in four individual files: November.csv, December.csv, January.csv, and February.csv. It is possible to import one file at a time into Disco and analyze each month separately. For example, after importing the November.csv file you would be able to see that the dataset covers the timeframe from 1 November 2016 until 30 November 2016 (see screenshot below - Click on the image to see a larger version of it).

However, we may want to answer questions about a larger timeframe. For example, we might want to look for cases that start in one month and are completed in the next month. For this, we need to combine these files into a single data set.
Note that the format of all four files in this example is identical: They all contain the same headings (a Case ID, Activity, and Completed Timestamp column) in the same order.
1. Combining the data in Excel
If your data is not that big, copying and pasting the data in Excel may be the easiest option.
The first step is to just open the November.csv file in Excel and scroll to the last row (208851) or use a shortcut1 and select the first empty cell (see screenshot below).

You can now simply add data from the December.csv file by choosing File -> Import and select the December.csv file. Note that you need to import from the 2nd row forward, otherwise the heading will be included again. We can see that 201135 rows are added to the Excel sheet (see below).
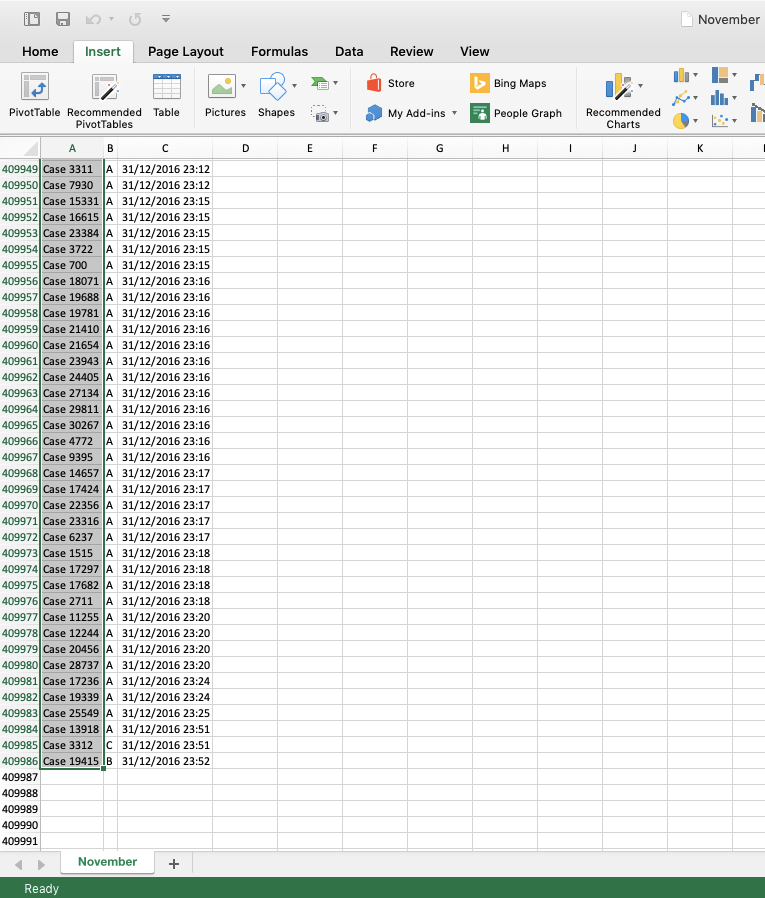
We can now save the data set as a CSV file and give it a new name, for example, November_and_December_Excel.csv. After importing the data into Disco we can check in the statistics that the dataset now covers two months of data (see below).
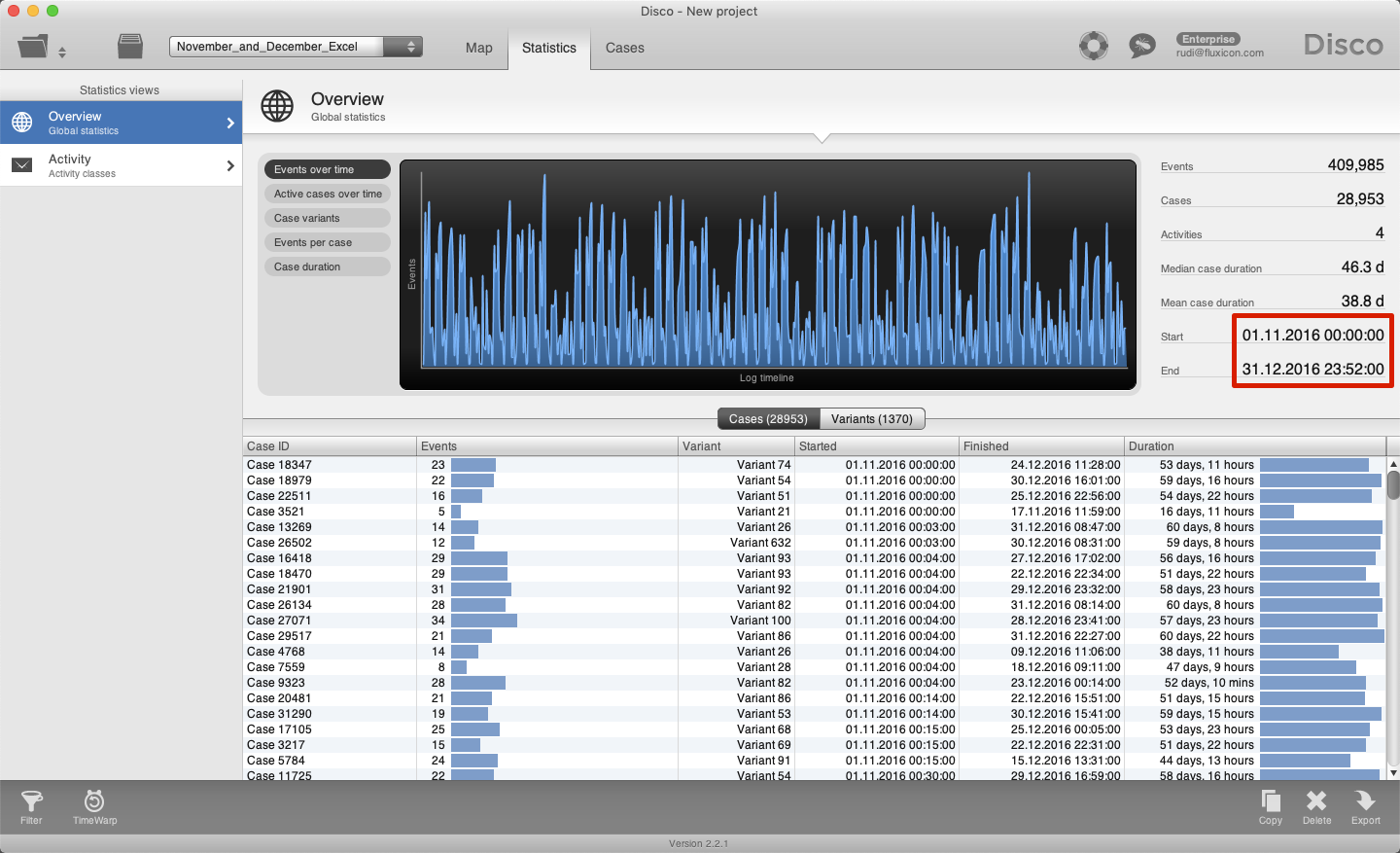
Using Excel is easy, but you need to be aware that current versions of Excel are limited up to 1,048,576 rows and older versions are even restricted to handle only 65,663 rows. In this example, we are able to combine all four files without exceeding the Excel limit. However, the more you approach the data volume limits it could be that Excel becomes very slow.
2. Combining the data in an ETL tool
Once the data becomes too big for Excel, you need a different approach. If you are not used to working with databases and looking for a simpler way to combine large datasets, then we recommend to use an ETL tool. ETL tools provide a graphical interface to drag and drop workflows to transform your data. It is therefore much more accessible for non-technical users.
In this example we use KNIME, which is open source and freely available at: www.knime.org.
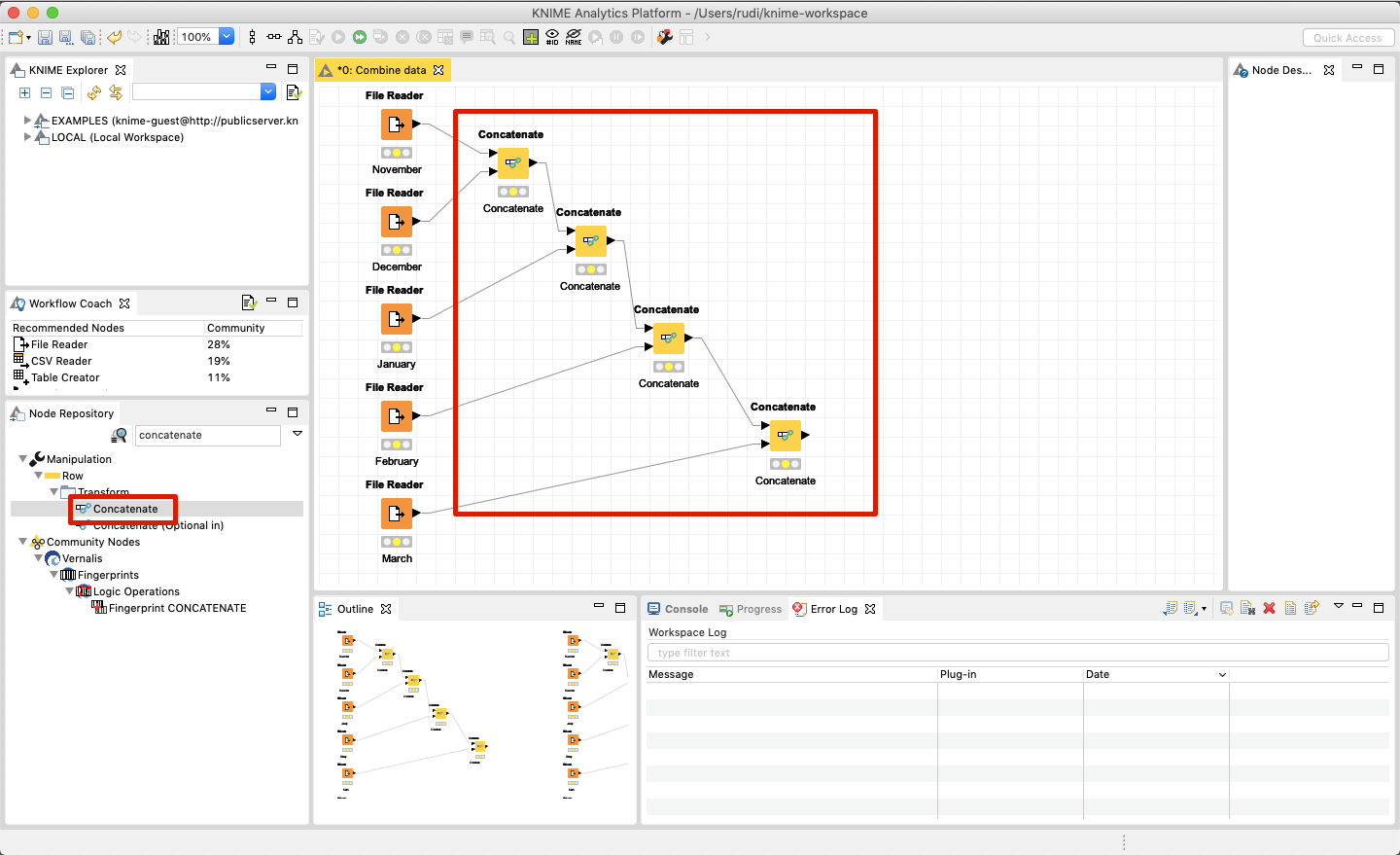
Once you have KNIME installed, you can create a new workflow that starts with importing the individual CSV files. Each file can be imported by dragging a File Reader to the canvas and configured to read the right file (see below).

With a Concatenate two File Readers can be combined into a single dataset (see below).
Finally, the result can be saved as a CSV using a CSV Writer (see below). In the “CSV Writer” block you can configure the location to which the resulting file will be written. Finally, just execute the workflow that will save the combined dataset at the specified location.
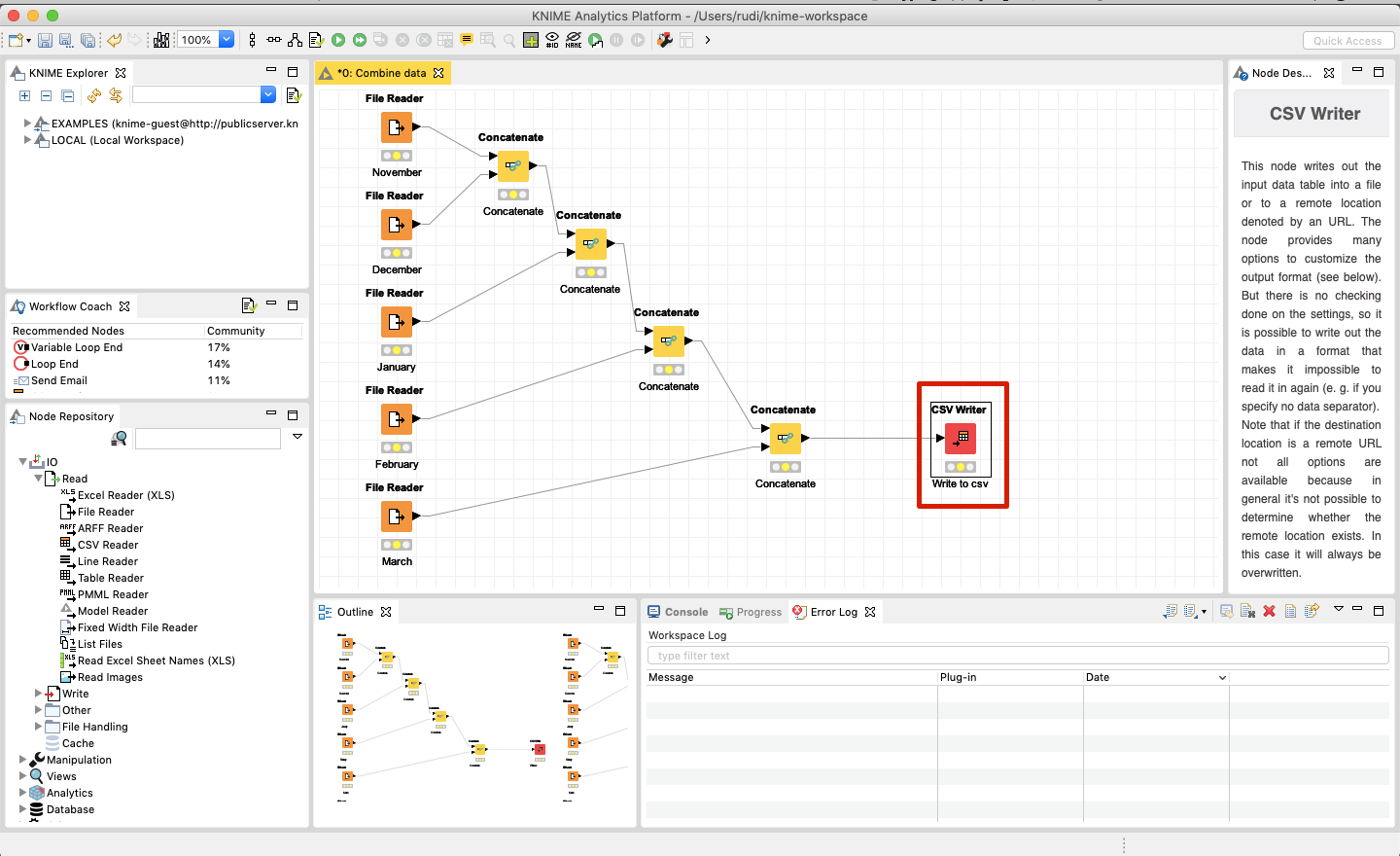
3. Combining the data in an SQL database
Of course you can also do this data preparation in a good old database. This requires some technical skills to set up a database server and being able to write SQL queries.
There are many databases available. For this example, I downloaded and installed the open source MySQL Community Server and MySQL workbench from https://dev.mysql.com.
The simplest way to add data is to use the Table Data Import Wizard2 to import the csv files. For each file a table will be created in the database and the data will be inserted into this table see (1) in the screenshot below.
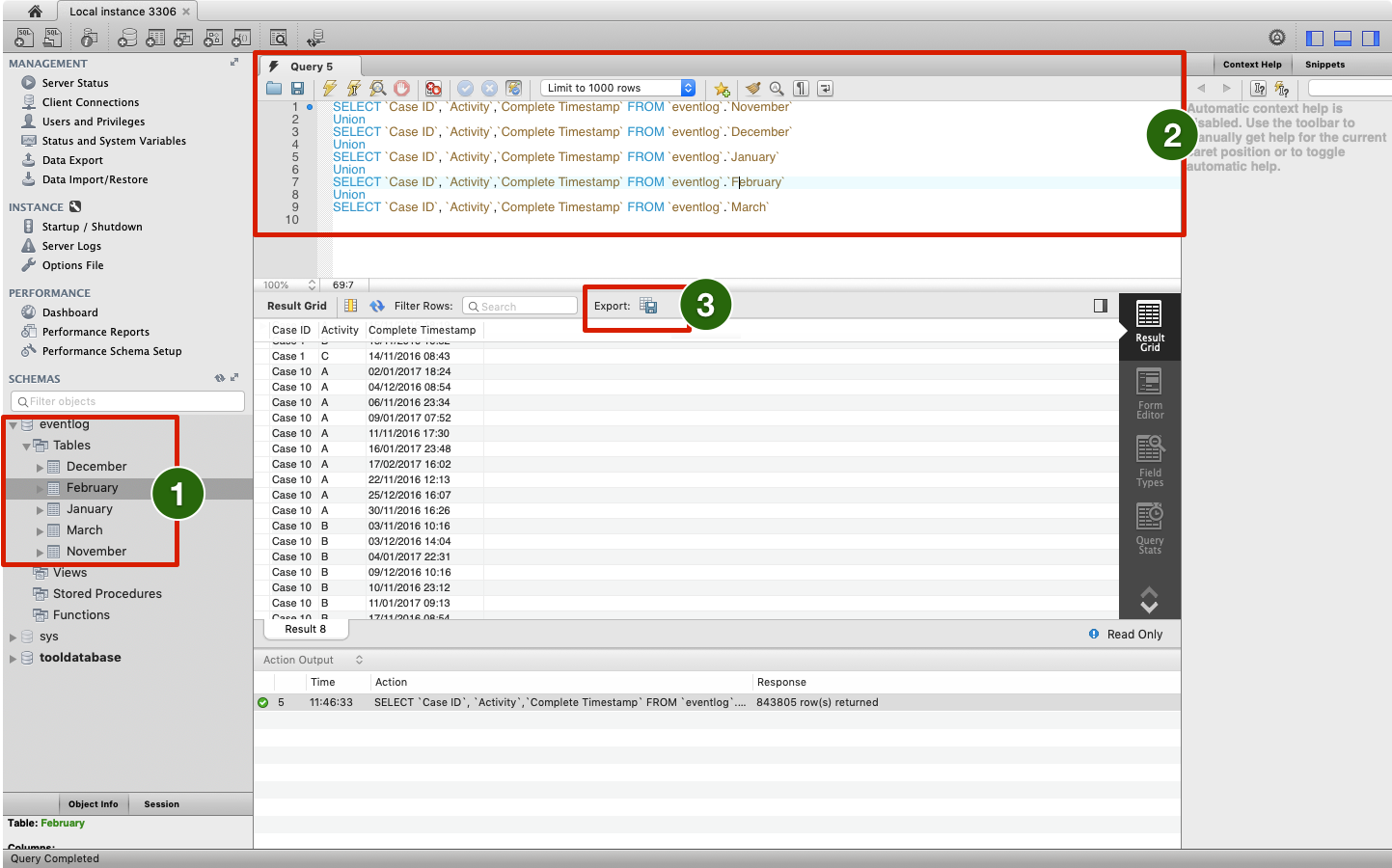
Now you access the data, for example the November data, in the database using the following SQL query:
SELECT `Case ID`, `Activity`,`Complete Timestamp` FROM `eventlog`.`November`Data from multiple tables can be combined using a Union between each select statement of the individual table see (2) in the screenshot above:
`SELECT `Case ID`, `Activity`,`Complete Timestamp` FROM `eventlog`.`November`
Union
SELECT `Case ID`, `Activity`,`Complete Timestamp` FROM `eventlog`.`December`
Union
SELECT `Case ID`, `Activity`,`Complete Timestamp` FROM `eventlog`.`January`
Union
SELECT `Case ID`, `Activity`,`Complete Timestamp` FROM `eventlog`.`February`
Union
SELECT `Case ID`, `Activity`,`Complete Timestamp` FROM `eventlog`.`March`Finally, you can export the data and save is as a CSV file by using the export function see (3) in the screenshot above.
After importing this CSV file into Disco, we can see that now the dataset contains a total of 843,805 events and covers the timeframe from 1 November until 5 March (see below).
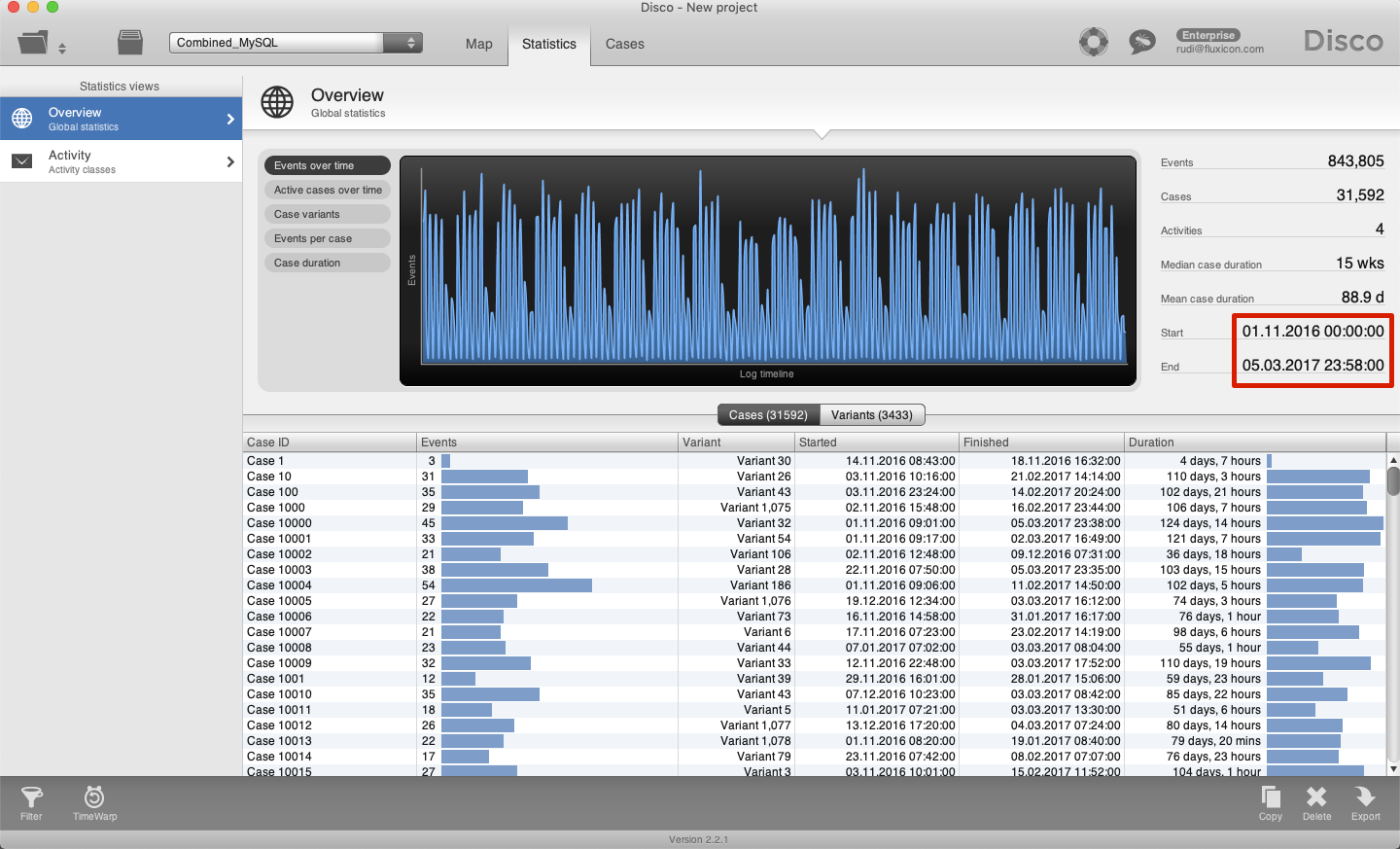
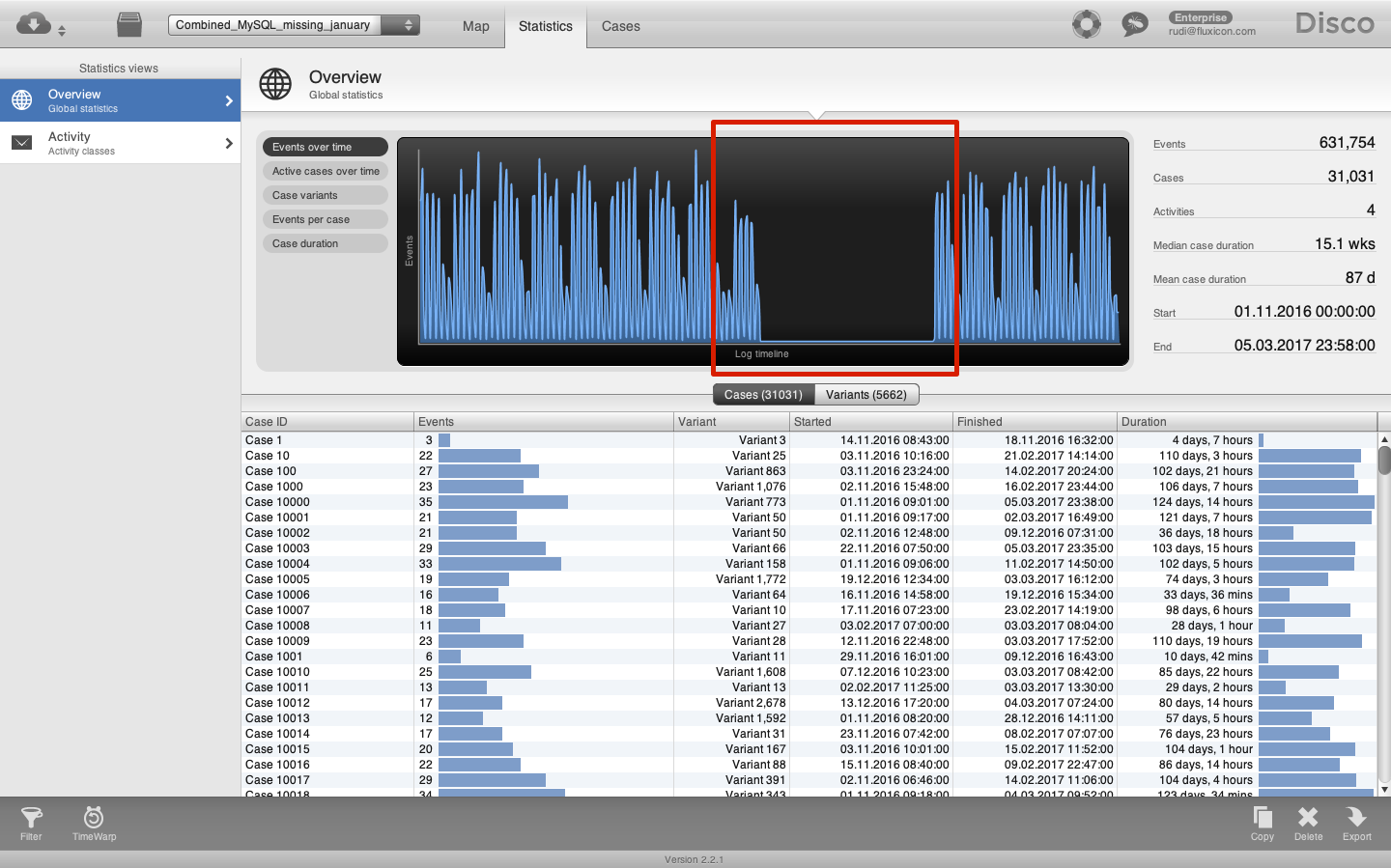
Whichever method you use, make sure to verify not only that the start and the end timestamps of the new data set are as expected, but also check that there are no gaps in the timeline.
A gap in the timeline would most likely indicate that something went wrong in your data preparation. For example, you could have forgotten to include one of the files (see the screenshot below).
-
Shift+End on Windows or Command+Shift+Down on macOS ↩︎
-
Note that the Table Data Import Wizard (see https://dev.mysql.com/doc/workbench/en/wb-admin-export-import-table.html is slow because each row requires an insert statement to be executed. A faster approach would be to import use the INFILE import function. However, this requires to write a data import script. ↩︎

Rudi Niks
Process Mining and everything else
Rudi has been a process mining pioneer since 2004. As a Process Mining expert and Lean Six Sigma Black Belt, he has over ten years of practical, hands-on experience with applying process mining to improve customers’ processes. At Fluxicon, he is sharing his vast experience to make sure you succeed.