
Ideally, your data is in perfect shape and you can immediately use it for your process mining analysis without any changes. Unfortunately, there are many situations, where this is not the case and you actually need to prepare your data set a little bit to be able to answer your analysis questions.
In this series, we will be looking at typical process mining data transformation tasks. Via step-by-step instructions, we will show you exactly how you can accomplish these data preparation steps for your own data:
- Part 1: Unfold Loops for Cases (this article)
- Part 2: Unfold Loops for Activity Repetitions
- Part 3: Combine Data Sets of the Same Shape
- Part 4: Transpose Data
- Part 5: Remove Repetitions
- Part 6: Relabeling Activities
- Part 7: Domain Specific Transformations
- Part 8: Two Little Tricks
- Part 9: To be continued
Unfold Loops for Cases
If you have a loop in your process then this means that a certain process step is repeated more than once. While, strictly speaking, the term loop refers to what is also called a ‘self-loop’ (a direct repetition), the term is typically more loosely used to refer to cycles in general in the context of process maps.
Loops are often interesting for a process mining analyst, because they help to spot rework and inefficiencies in the process (see our article on how to identify rework in process mining here).
But sometimes, loops can also get in the way of answering your process mining questions. For example, imagine a process, where a tool such as a heavy-duty power drill can be rented for specialized construction work. To trace the movement of the tools, a barcode has been attached to each drill. The barcode provides a unique identifier for each tool and serves as our process mining case ID.
In addition, the following status changes are tracked with a timestamp for each tool: ‘Pickup’ (a tool is picked up by a customer), ‘Return’ (the tool is returned by the customer), ‘Ready for pickup’ (the tool is back in the store and available for a new rental cycle by a new customer), and ‘Intervention’ (the tool needs to be repaired).
The process map below shows the process that is discovered for this data set by Disco (click on the image to see a larger version).1
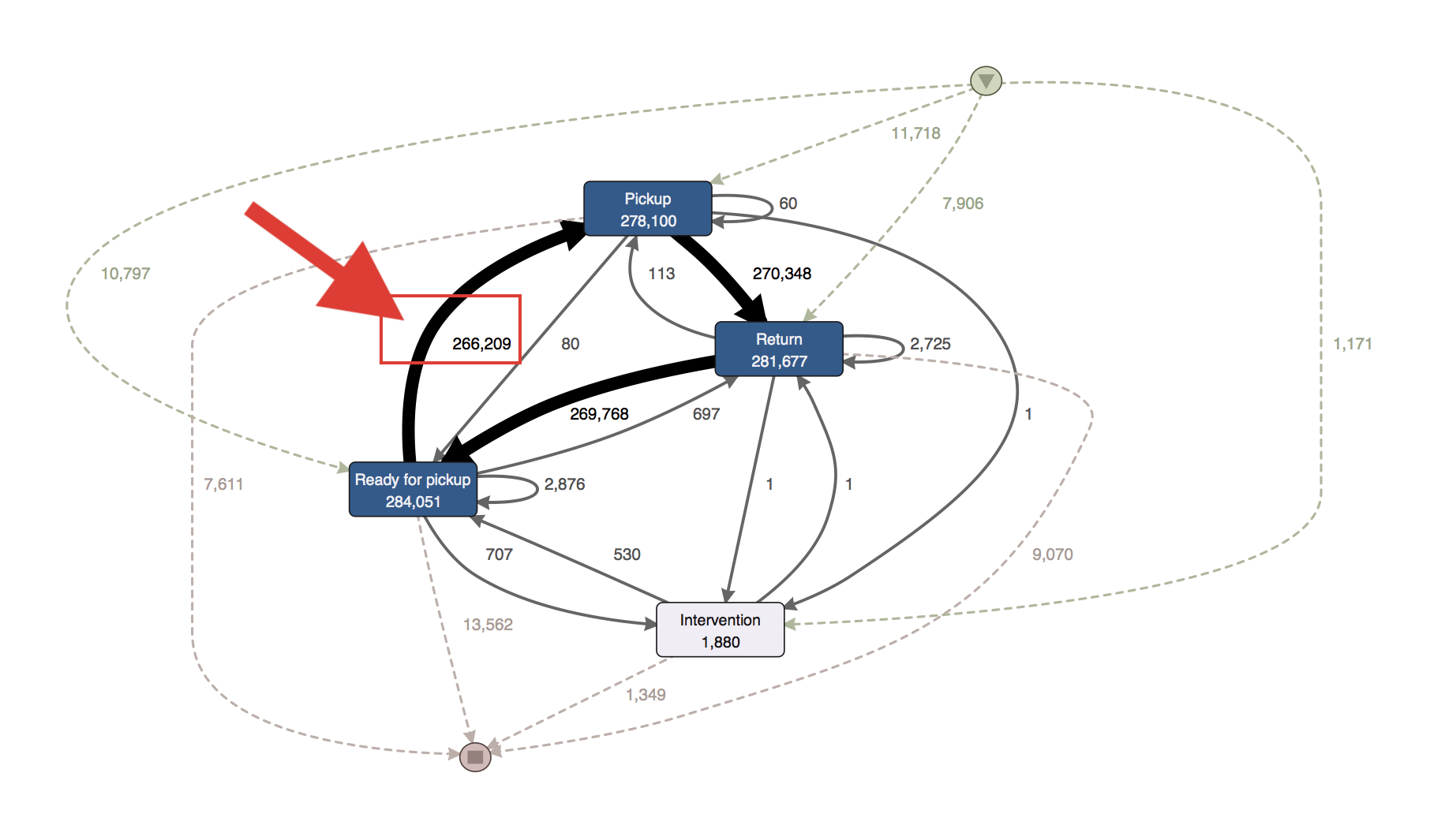
As you can see in the process map by following the thick paths, there is a very dominant loop in this process: Each of the 31,592 tools is picked up, returned, and prepared for the next customer several times See the red arrow that points to the place where the tool rental cycle is restarted again for the next customer.
The problem with this loop is that some questions cannot be answered from this process perspective. For example, what if you want to know:
How many times it took more than two days before a tool was ready for pickup after it was returned by the customer?
Right now, we can only answer this question based on how many tools took more than two days at least once between ‘Return’ and ‘Ready for pickup’, because the tool’s barcode is currently our case ID.
To understand how many times in total a tool took more than two days between ‘Return’ and ‘Ready for pickup’ we need to shift the case ID perspective from the tool ID to a single rental cycle. But to do this, we need a “rental cycle counter” for each tool.
Here is how you can achieve this and break up a loop in your process into multiple case IDs.
Step 1: Sort your dataset
In this first step, you need to make sure that your data is sorted based on your case ID (here the tool’s barcode) and the timestamps. It is not important that the case IDs are in a particular order. But all events that belong to the same case need to be grouped in such a way that they appear after each other in the right sequence (so, you want to have the events in the right order for each case).
There are several ways to do this. For example, you can sort the data in Excel, in your database, or via an ETL tool. But the simplest way of all is to just import your data into Disco and export it as a CSV file again. You will see that the result is a neatly sorted event log.
Step 2: Transform your data
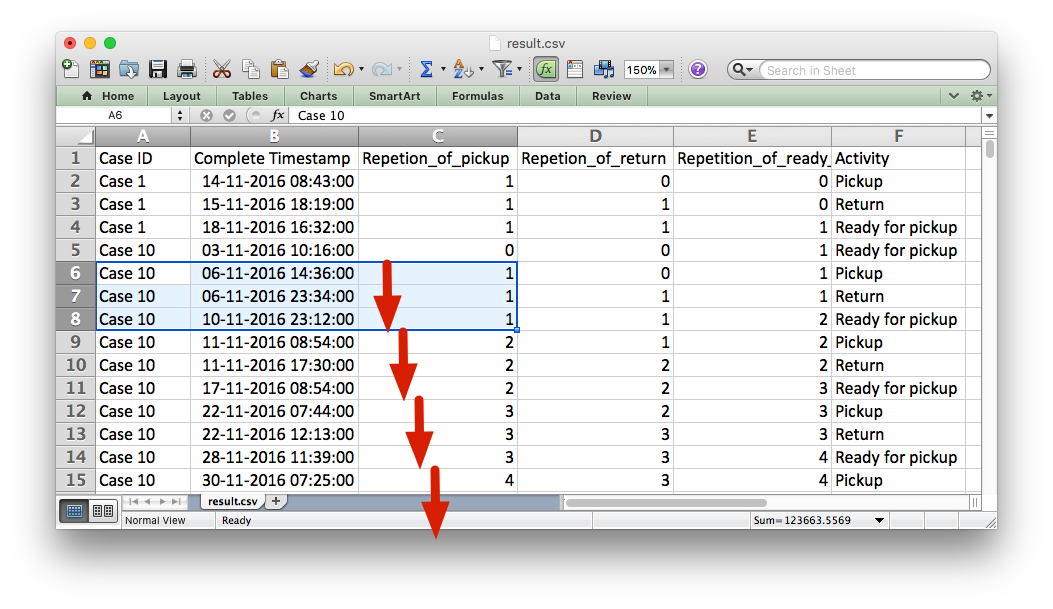
When you look at the sorted data set (see below), then you can see how a single tool ID (here ‘Case 10’) goes through multiple cycles of ‘Pickup’, ‘Return’, and ‘Ready for pickup’.
![]()
To be able to analyze each rental cycle separately, this loop needs to be broken up into multiple case IDs: We want to start a new case each time that the cycle repeats again. So, in addition to knowing that the drill with the barcode ‘Case 10’ was rented out, we also want to know whether it was rented out the first, the second, or the 100th time.
Because we do not have such a rental cycle counter yet, we will add it ourselves in this data transformation step. I have used a Python script to generate the sequence counter. But you can do the same with a Visual Basic script or any other programming language of your preference.
To preserve the flexibility to decide later where exactly the rental cycle restarts (at ‘Pickup’, ‘Return’, or ‘Ready for pickup’?), I have simply added a loop counter for each of these activities.
Here is my Python code snippet:
|
|
The result of this transformation is a new data set with three additional columns, which count the number of repetitions for the activities ‘Pickup’, ‘Return’ and ‘Ready for pickup’ for each case, respectively (see below).
![]()
Step 3: Pick the right perspective and analyze
Let’s say that we want to start a new rental cycle with each ‘Pickup’ activity. This means that, for example, the case with the tool ID ‘Case 10’ should be broken up into multiple cases such as ‘Case 10-0’ (no ‘Pickup’ has occurred yet), ‘Case 10-1’ (the drill has been picked up once), ‘Case 10-2’ (the drill has been picked up a second time), ‘Case 10-3’ (the drill has been picked up a third time), etc.
Each of these cases are much shorter (see the red arrows in the screenshot below) than the previous, very long case ‘Case 10’.
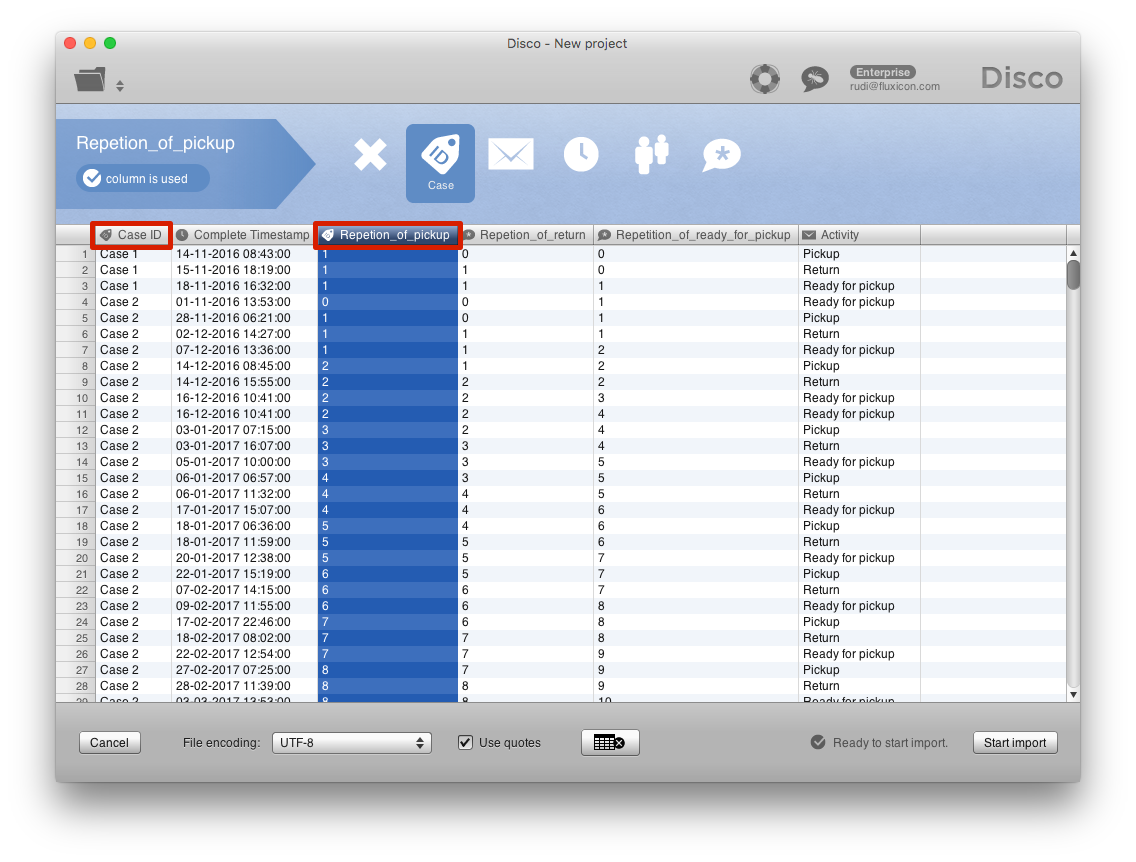
Now that we have added the repetition counter columns, taking this perspective is easy: We can simply configure both the ‘Case ID’ column (this is the tool ID from the barcode) and the new ‘Repetition_of_pickup’ column as a Case ID column in the import step (note the little Case ID symbol in the header row of both columns):
After importing the data into Disco, we remove all tool rental cycle cases that do not start with the ‘Pickup’ activity or that do not reach the ‘Ready for pickup’ activity in their cycle (see our article on ‘how to deal with incomplete cases’ here). This leaves us with 261,594 rental cycles for all tools together (see below).
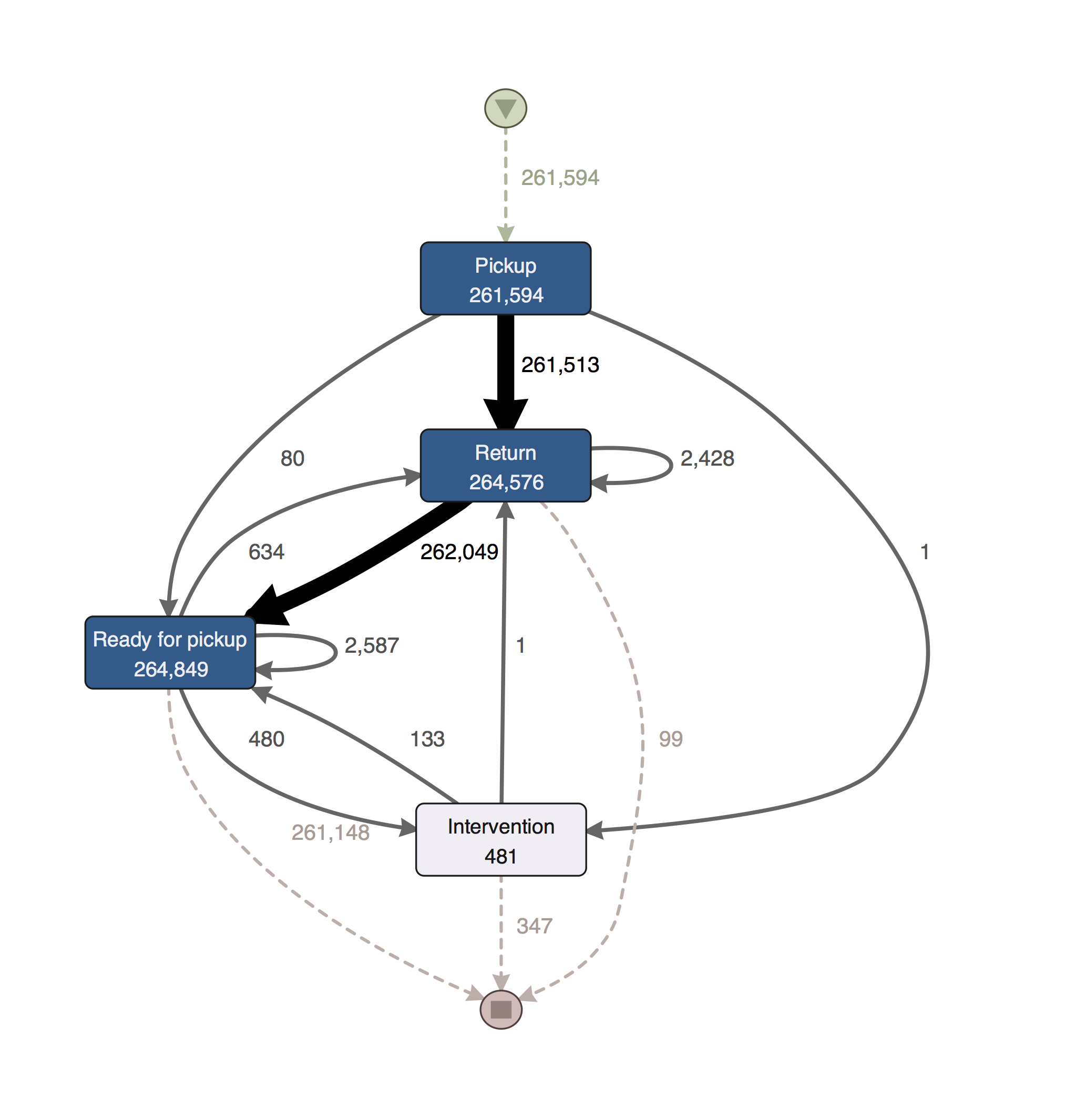
Out of these 261,594 cases, we can now answer our original question and determine how many times a tool was not ‘Ready for pickup’ again after the ‘Return’ activity within two days. One way to answer this question is to use the Follower filter (see screenshot below).
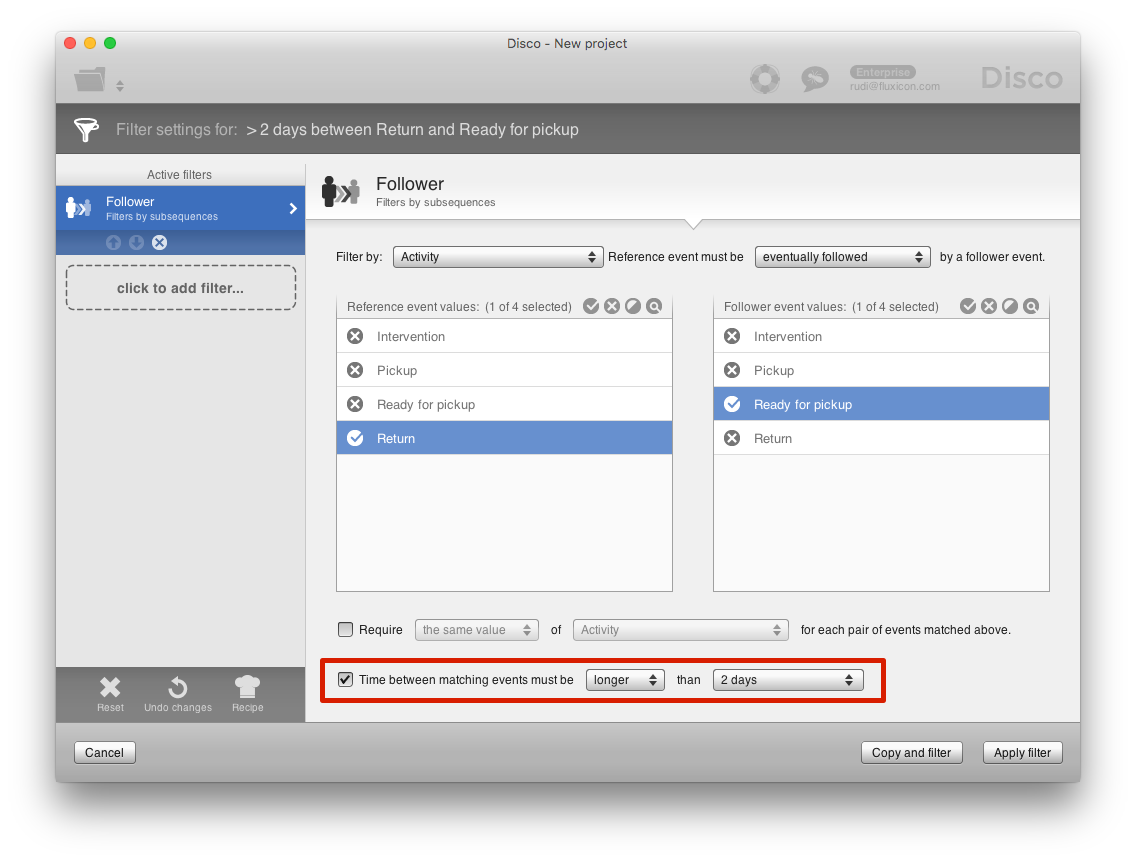
After applying this filter, we can see that in 83% of the cases it took more than two days2 to have the tool ready for pickup again (see below).
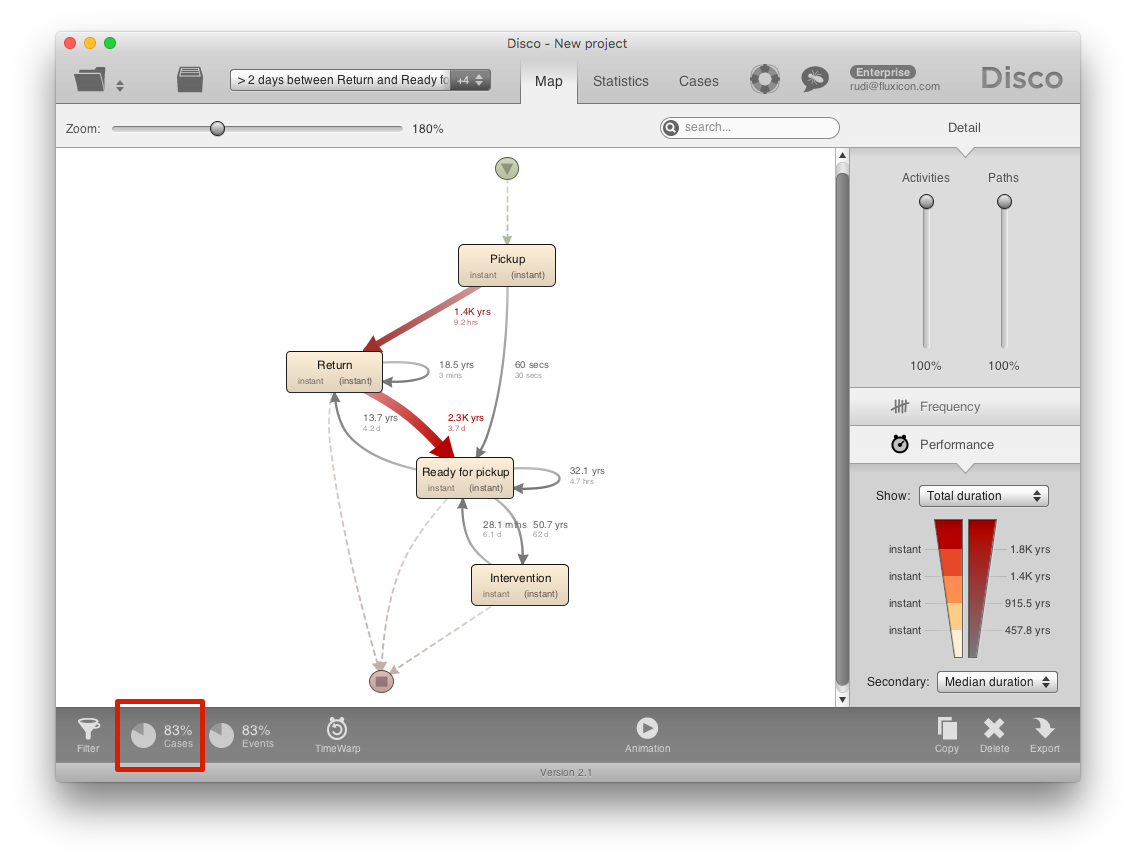
So, if having the tool ready for pickup within two days is our ambition, then currently only 17% of the rental cycles meet this goal and we need to find ways to improve our process.
-
Note that this process has multiple start and end points, because the data set was extracted for a certain timeframe. Different tools were in different stages of the rental cycle at the beginning and at the end of the data set. ↩︎
-
Note that we are looking at calendar days in this example. If we wanted to analyze this question based on business days, we could do this by removing weekends and holidays using the TimeWarp functionality in Disco as shown here. ↩︎

Rudi Niks
Process Mining and everything else
Rudi has been a process mining pioneer since 2004. As a Process Mining expert and Lean Six Sigma Black Belt, he has over ten years of practical, hands-on experience with applying process mining to improve customers’ processes. At Fluxicon, he is sharing his vast experience to make sure you succeed.