
This is the fourth article in our series on data quality problems for process mining. Make sure you also read the previous articles on formatting errors, missing data, and Zero timestamps.
In the article on Zero timestamps we have seen how timestamp problems can lead to faulty case durations. But faulty timestamps do not only influence the case durations. They also impact the variants and the process maps themselves, because the order of the activities is derived based on the timestamps.
For example, take a look at the following data set with just one faulty timestamp. There is one case with a 1970 timestamp (see screenshot below - click on the image to see a larger version). As a result, the ‘Create case’ activity is positioned before the ‘Import forms’ activity.
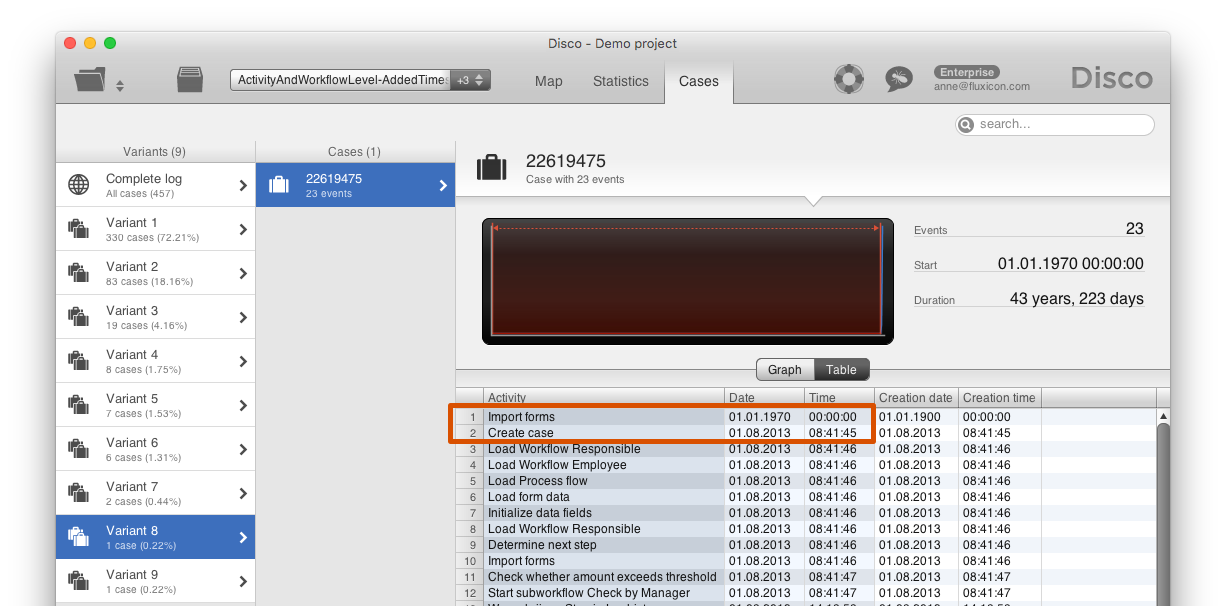
If we look at the process map, then you see that in all other 456 cases the process flows the other way. Clearly, the reverse sequence is caused by the 1970 timestamp.
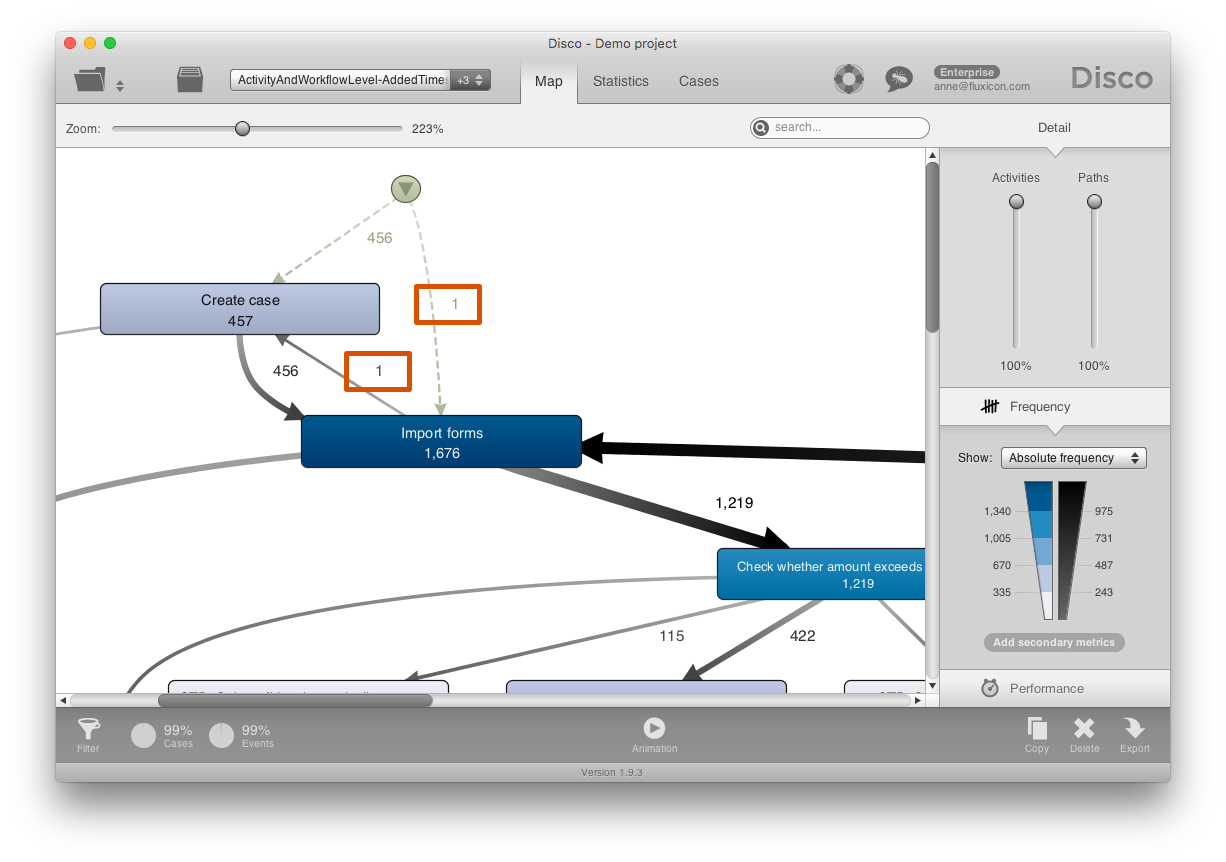
And if we look at the average waiting times in the process map, then this one faulty timestamp creates further problems and shows a huge delay of 43 years.
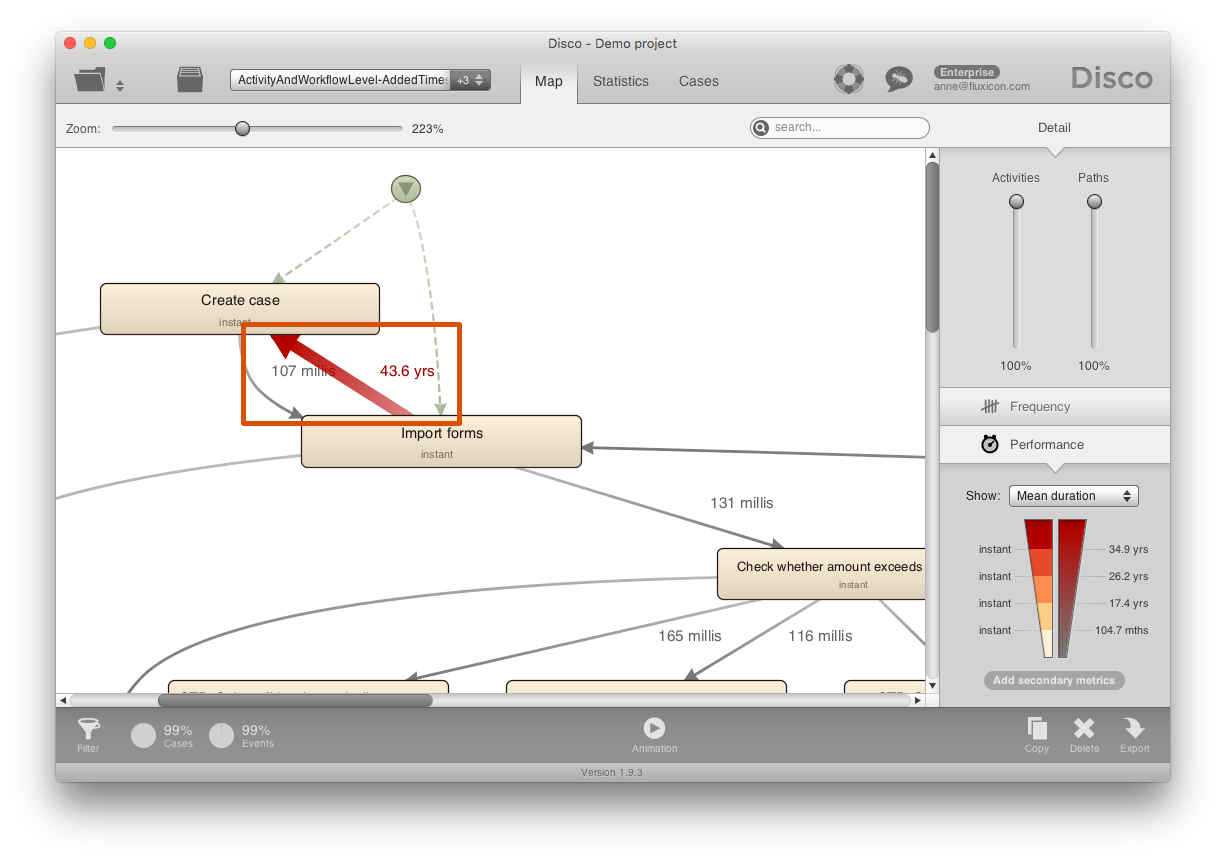
As you can see, data quality problems due to timestamp issues can distort your process mining analysis in many different places. Therefore, it is important to carefully assess the process map and the variants, if possible together with a domain expert, to spot any suspicious orderings of activities.
If you have found a problem with the timestamps, then there can be different reasons for why this is happening. Zero timestamps are just one possible reason. Here is the next one: Wrong timestamp configuration during import.
Wrong Timestamp Pattern Configuration
When you import a CSV or Excel file into Disco, the timestamp pattern is normally detected automatically. You don’t have to do anything. If it is not automatically detected, Disco lets you specify how the timestamp pattern should be interpreted rather than forcing you to convert your source data into a fixed timestamp format. And you can even work with different timestamp patterns in your data set.
However, if you have found that activities show up in the wrong order, or if you find that your process map looks weird and does not really show the expected process, then it is worth verifying that the timestamps are correctly configured during import.
You can do that by going back to the import screen: Either click on the Reload button from the project view or import your data again. Then, select the timestamp column and press the Pattern button in the top-right corner. You will see a few original timestamps as they are in your file (on the left side) and a preview of how Disco interprets them (in green, on the right side).
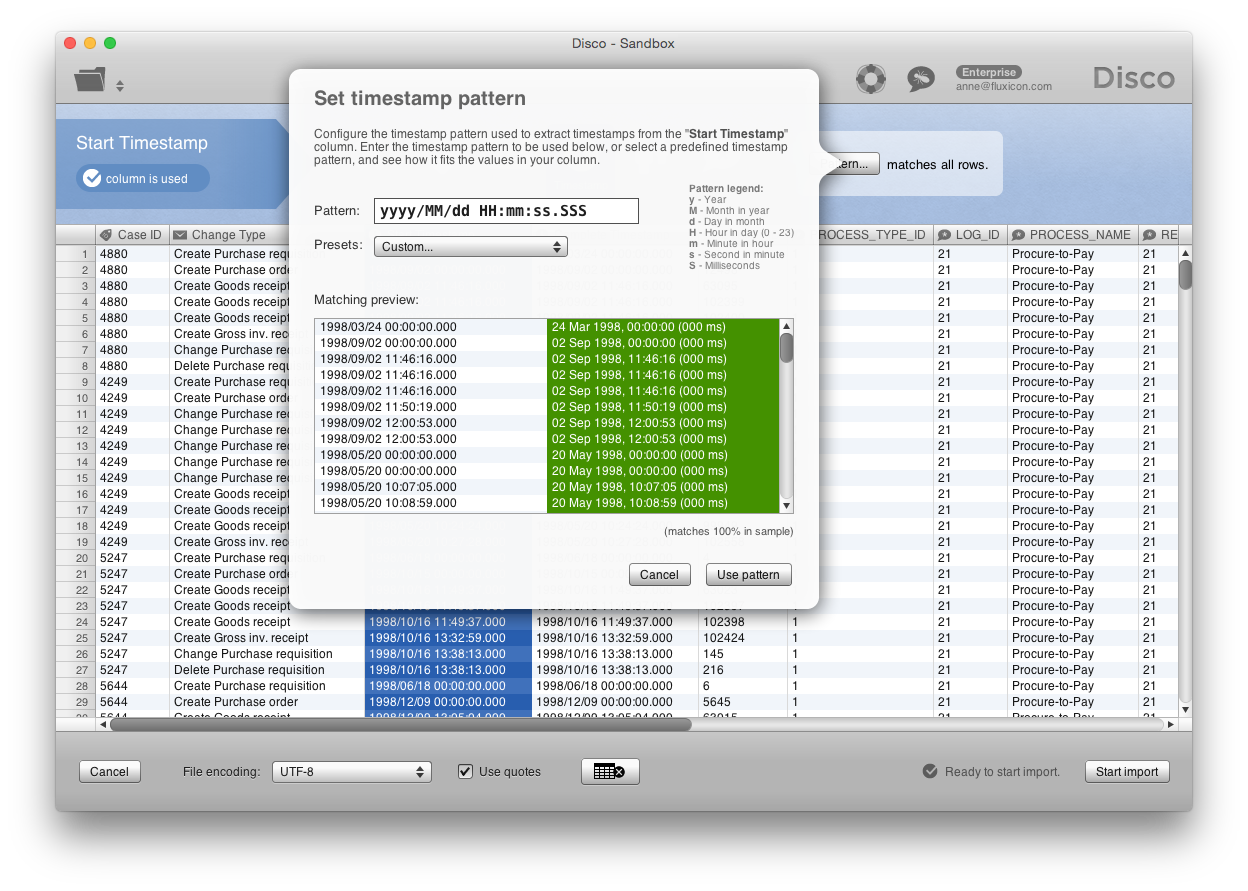
Check in the green column whether the timestamps are interpreted correctly. Pay attention to the lower and upper case of the letters in the pattern, because it makes a difference. For example, the lower case ’m’ stands for minutes while the upper case ‘M’ stands for months.
How to fix: If you find that the preview does not pick up the timestamps correctly, configure the correct pattern for your timestamp column in the import screen. You can empty the Pattern field and start typing the pattern that matches the timestamps in your data set (use the legend on the right, and for more advanced patterns see the Java date pattern reference for the precise notation and further examples). The green preview will be updated while you type, so that you can check whether the timestamps are now interpreted correctly. Then, press the Use Pattern button.
Wrong Timestamp Column Configuration
Another timestamp problem that can result from mistakes during the import step is that you may have accidentally configured some columns as a timestamp that are not actually a timestamp column in the sense of a process mining timestamp (but, for example, indicate the birthday of the customer).
In the customer service refund example below, the purchase date in the data has the form of a timestamp. However, this is a date that does not change over time and should actually be treated as an attribute. You can see that both the ‘Complete Timestamp’ as well as the ‘Purchase Date’ column have the title clock symbol in the header, which indicates that currently both are configured as a timestamp.
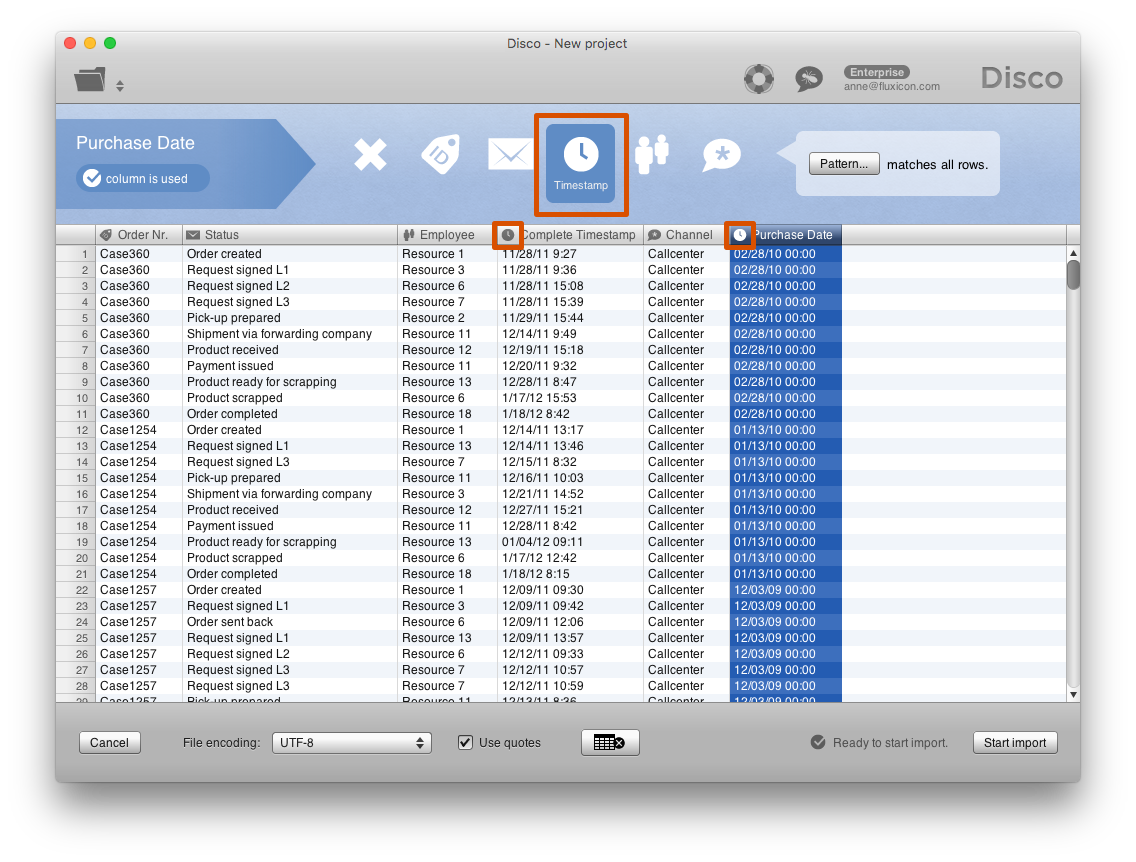
If columns are wrongly configured as a timestamp, Disco will use them to calculate the duration of the activity. As a consequence, activities can show up in parallel although the are in reality not happening at the same time.
How to fix: Make sure that only the right columns are configured as a timestamp: For each column, the current configuration is shown in the header. Look through all your columns and make sure only your actual timstamp columns are showing the little clock symbol that indicates the timestamp configuration. Then, press again the Start import button.
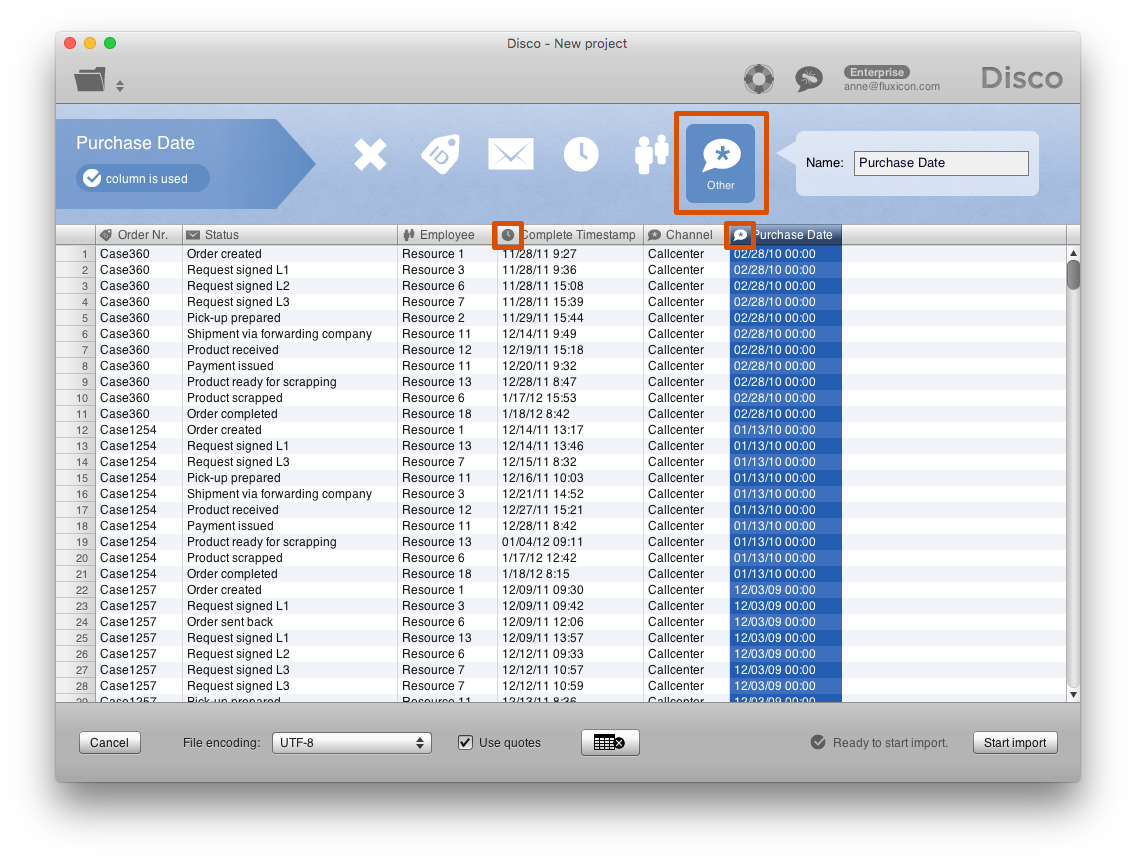
For example, in the customer service data set, we would change the configuration of the ‘Purchase Date’ column to a normal attribute as shown below.

Anne Rozinat
Market, customers, and everything else
Anne knows how to mine a process like no other. She has conducted a large number of process mining projects with companies such as Philips Healthcare, Océ, ASML, Philips Consumer Lifestyle, and many others.