In a guest article earlier this year, Nick talked about what a pain timestamps are in the data preparation phase.
Luckily, Disco does not force you to provide timestamps in a specific format. Instead, you can simply tell Disco how it should read your timestamps by configuring the timestamp pattern during the import step.
This works in the following way:
-
You select your timestamp column (it will be highlighted in blue)
-
You press the ‘Pattern…’ button in the upper right corner
-
Now you will see a dialog with a sample of the timestamps in your data (on the left side) and a preview of how Disco currently interpets these timestamps (on the right side).
In most cases, Disco will automatically discover your timestamp correctly. But if it has not recognized your timestamp then you can start typing the pattern in the text field at the top and the preview will be automatically updated while you are typing, so that you check whether the date and time are picked up correctly.
You can use the legend on the right side to see which letters refer to the hours, minutes, months, etc. Pay attention to the upper case and lower case, because it makes a difference. For example ‘M’ stands for month while ’m’ stands for minute. The legend shows only the most important pattern elements, but you can find a full list of patterns (including examples) here.
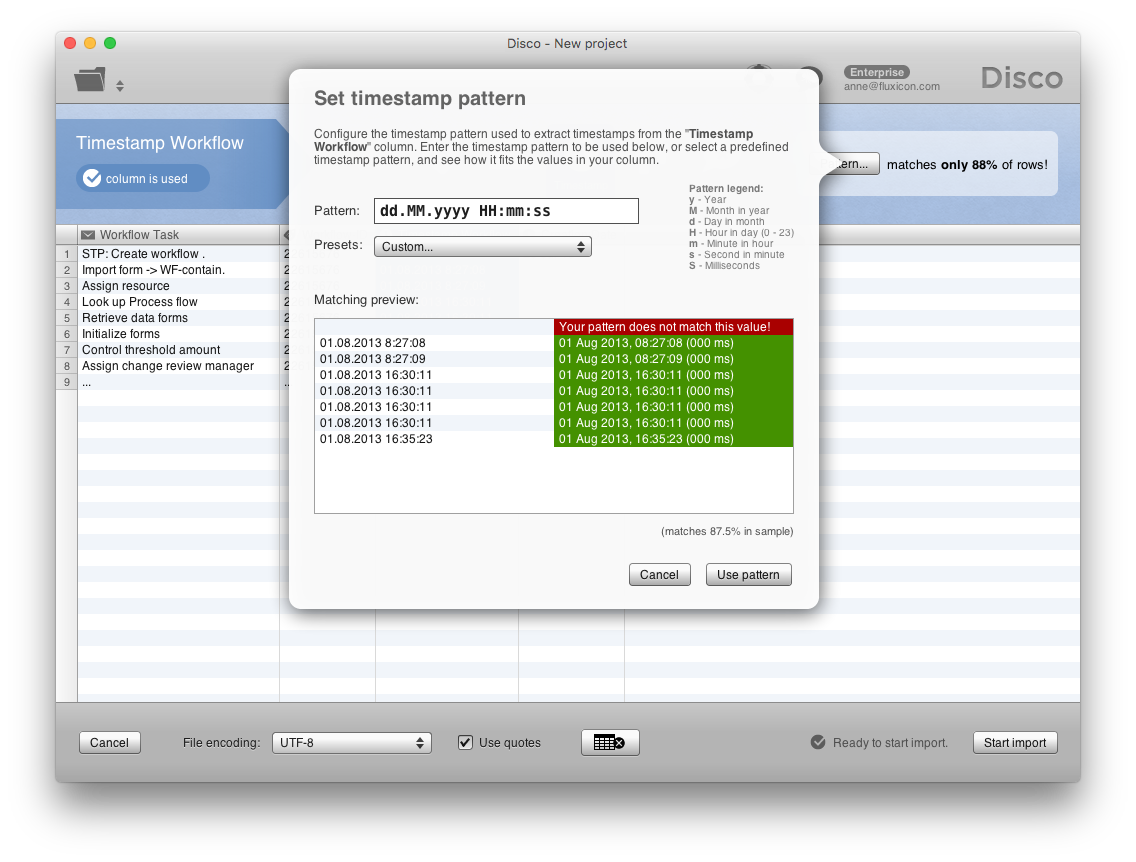
_But what do you do if you have combined data from different sources, and they come with different timestamp patterns? _
Let’s look at the following example snippet, which contains just a few events for one case. As you can see, the first event has only a creation date and it is in a different timestamp format than the other workflow timestamps.


So, how do you deal with such different timestamp patterns in your data?
In fact, this is really easy: All you have to do is to make sure you put these differently formatted timestamps in different columns. And then you can configure different timestamp patterns for each column.
For example, the screenshot at the top shows you the pattern configuration for the workflow timestamp. And in the screenshot below you can see the timestamp pattern for the creation date.
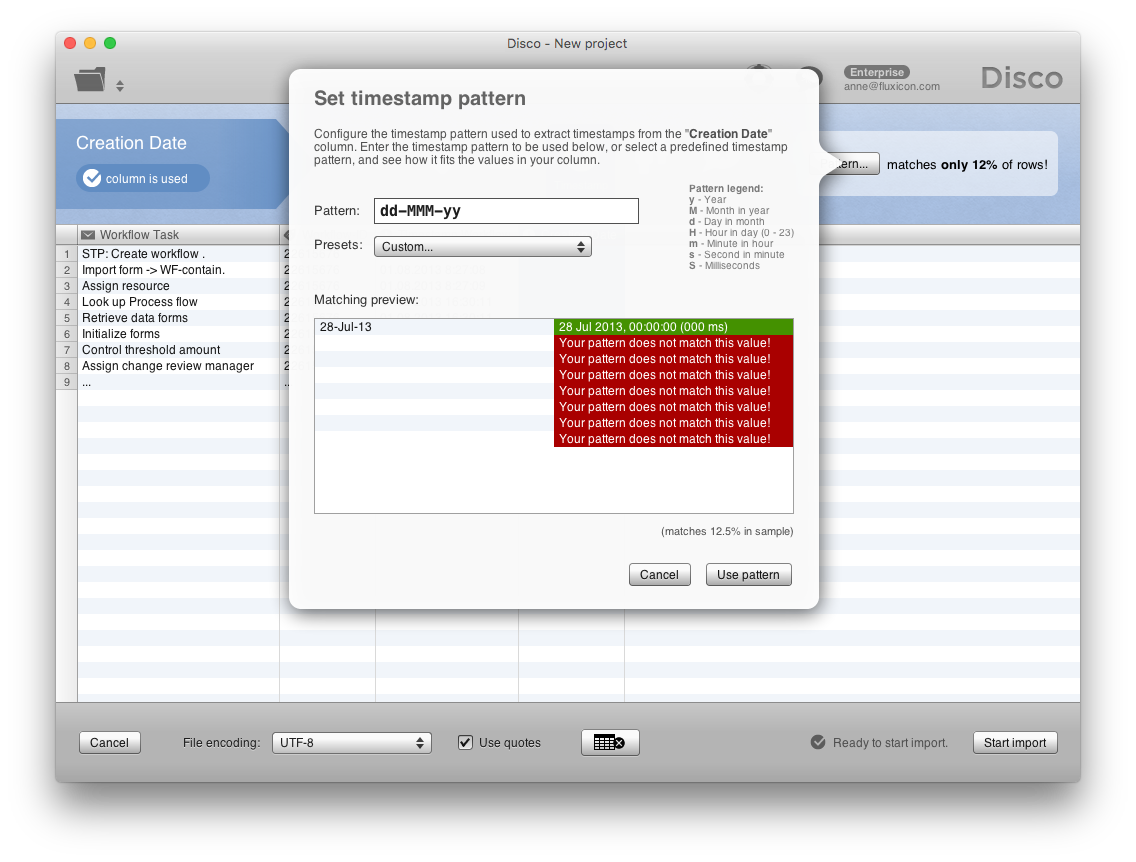
So, now both columns have been configured as timestamps (each with a different pattern) and you can click the ‘Start import’ button. Disco will pick the correct timestamp for each event.

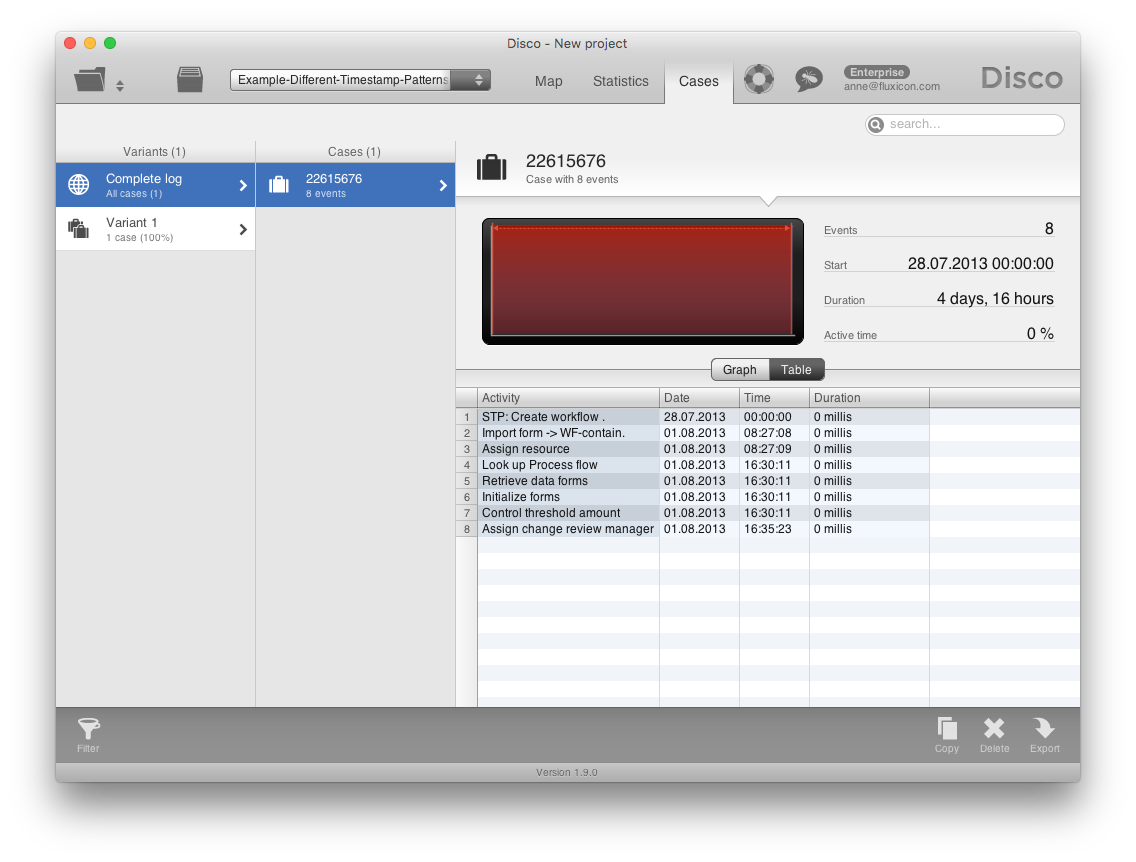
The discovered process map shows you the correct waiting times between the steps.

And this is the case in the Cases view, showing all 8 steps in the right sequence.
That’s it!
So, keep this in mind when you encounter data with different timestamp formats. There is no need to change the date or time format in the source data (which can be quite a headache). All you have to do is to make sure they go into different columns.

Anne Rozinat
Market, customers, and everything else
Anne knows how to mine a process like no other. She has conducted a large number of process mining projects with companies such as Philips Healthcare, Océ, ASML, Philips Consumer Lifestyle, and many others.