
This is the third part in a series about managing complexity in process mining. We recommend to read Part I and Part II first if you have not seen them yet.
Part III: Divide and Conquer
The third set of strategies are called Divide and conquer because they are about breaking up your data in various ways to make it more manageable. The divide and conquer strategies have a lot to do with the fact that you do not want to compare apples with pears.
Strategy 4) Multiple Process Types
A first way to split up your data is to realize that very often your process actually consists of multiple process types. You may get the whole data set in one file, because this is how it is extracted, but this does not necessarily mean that you have to analyze all that data at once.
For example, the customer service refund process used as example in the previous sections has an attribute that indicates the channel by which the process was started: Customers can (a) initiate the refund themselves through the internet by filling out a form, (b) they can call the help desk, or (c) they can go back to the dealership chain, where they bought the product in the first place (see below).
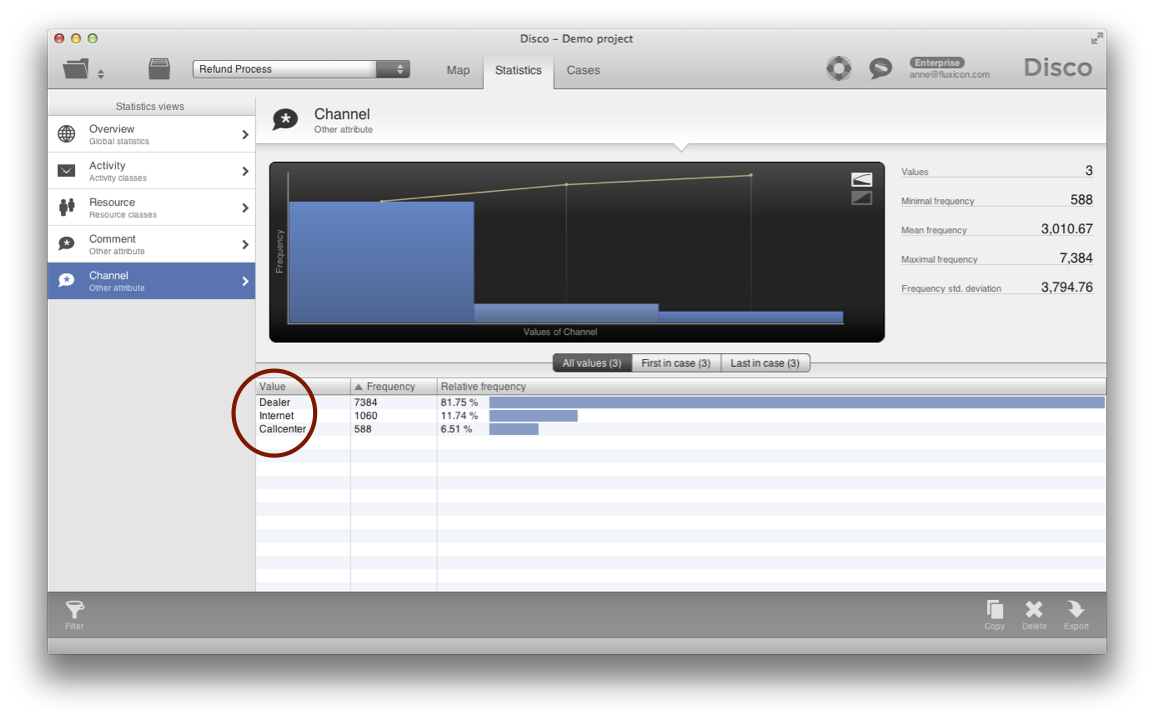
The processes for these different channels are not the same. For example, the refund process for the dealer channel involves completely different process steps than for the other two channels. However, if we do not separate them from each other then we get all of the different processes in one picture, making the process map unnecessarily complicated.
A similar situation can be found in IT Service Desk processes. For example, in a change management process the actual process steps can be quite different depending on the change category: Implementing a change to the SAP system is not the same as creating a new user account. The change category attribute can be used to separate the data for these different process types.
In Disco, you can easily filter data sets on any process attribute that you have imported. Simply add an Attribute filter and select the attribute indicating your process type in the Filter by drop-down list (see below).
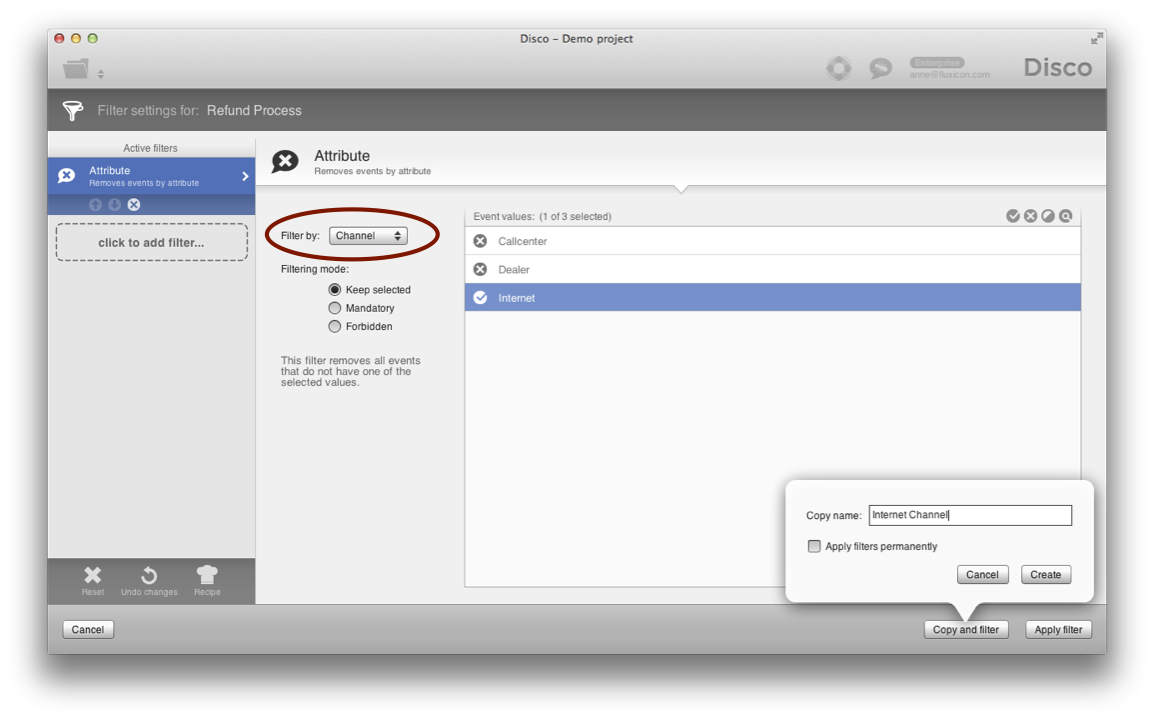
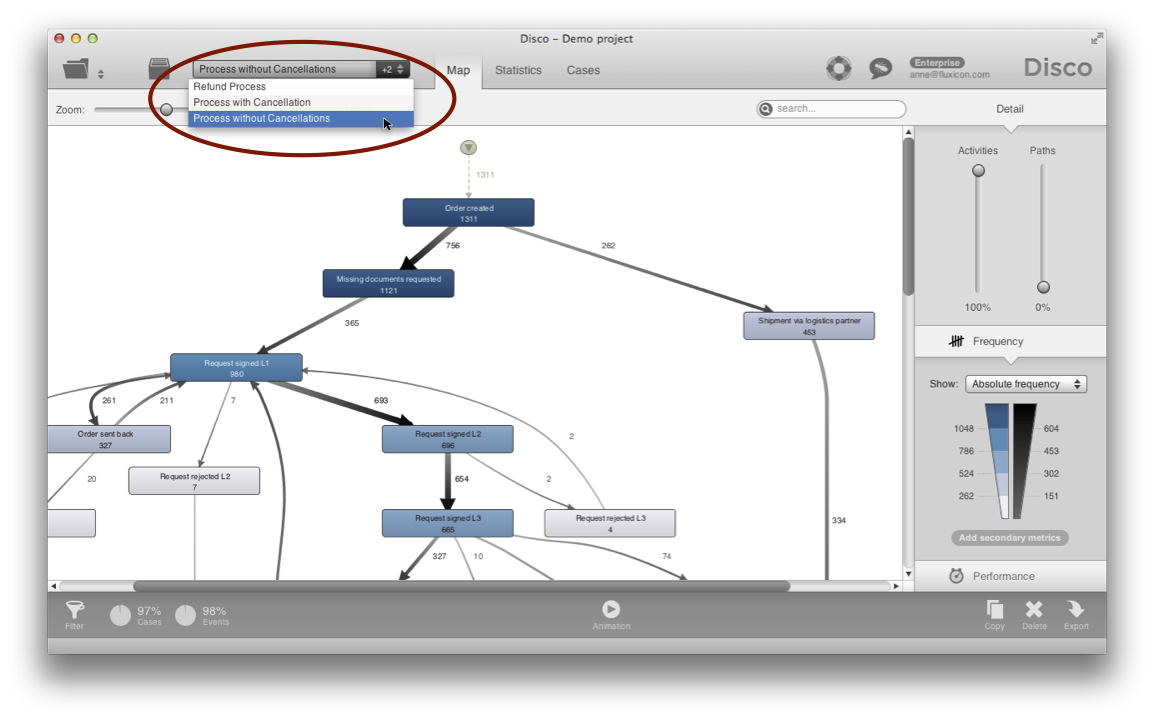
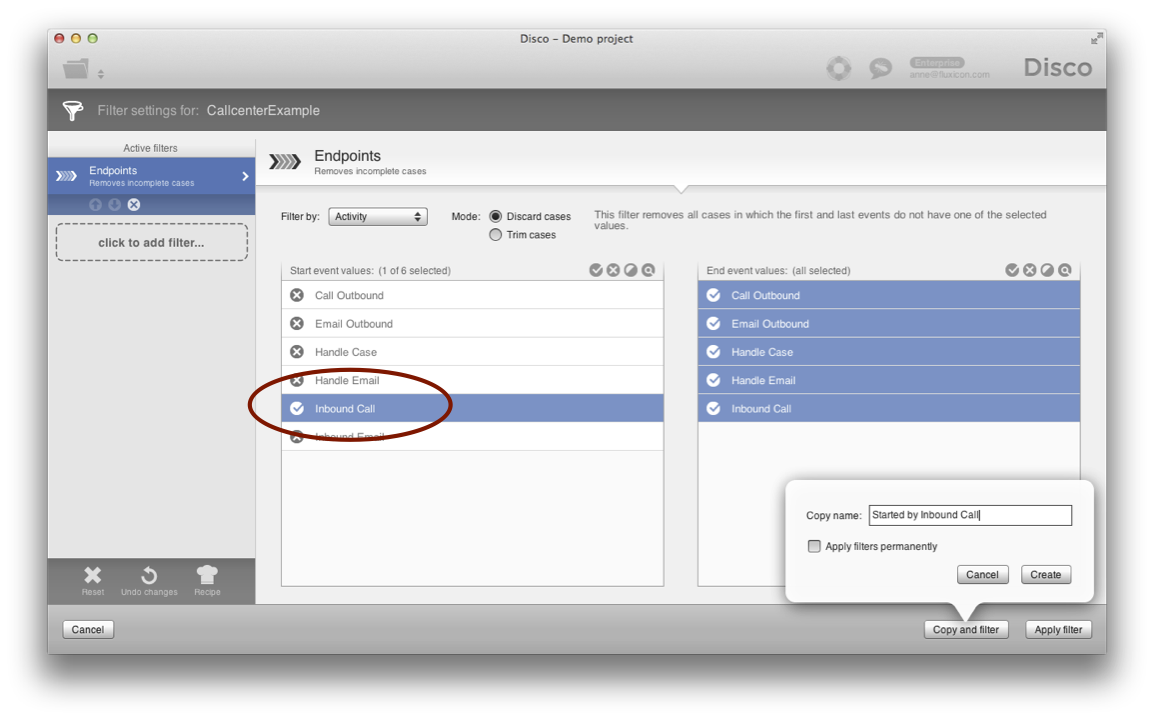
What we recommend when you split up data sets is that you use the Copy and filter button instead of the Apply filter button to apply the filter to a copy (see above). For example, for three different process types, you can simply create three copies, one for each process type, to further analyze these processes in isolation.
In fact, creating copies is a very good idea for many situations: Every copy is preserved in your Disco project view, and you can easily switch back and forth between them, record notes about your observations, and so on.
When you create the copy, make sure to give it a name that is meaningful, for example, indicating the process type that is analyzed. This way, you can find them back quickly.
(Note: Copies are managed efficiently in Disco (pointing to the same underlying data set where possible), so you do not need to be afraid to use them also for very large data sets.)
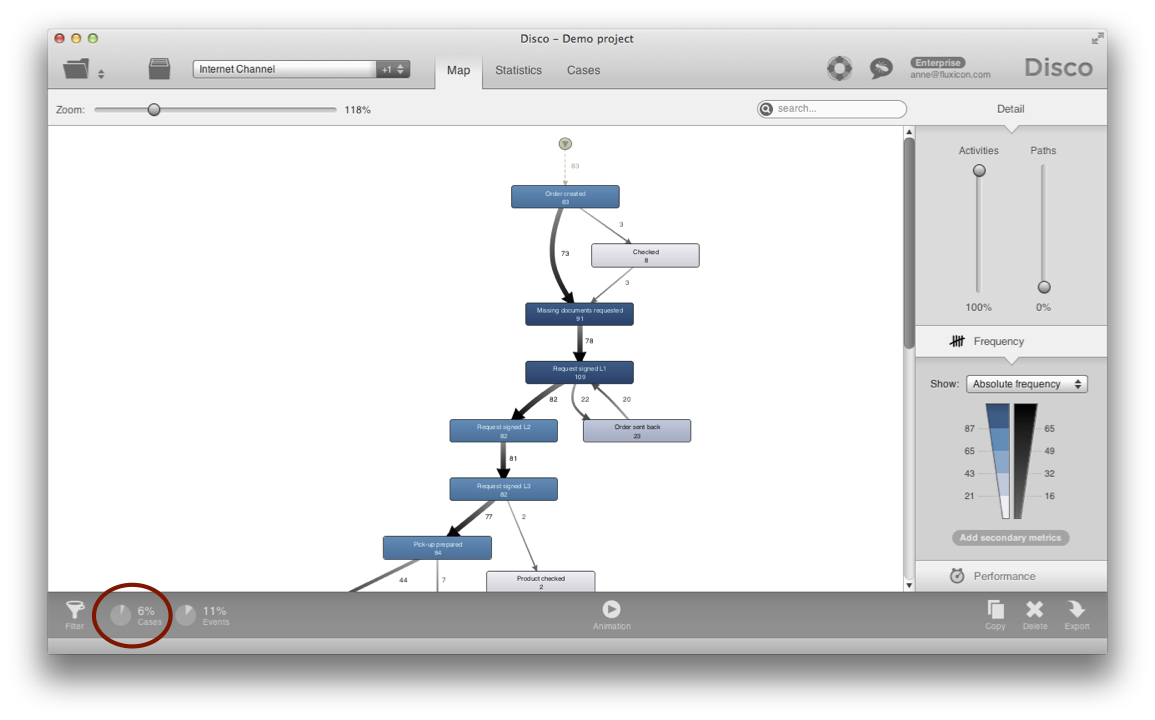
For example, here you see the refund process, filtered for the Internet channel (covering 6% of the cases).
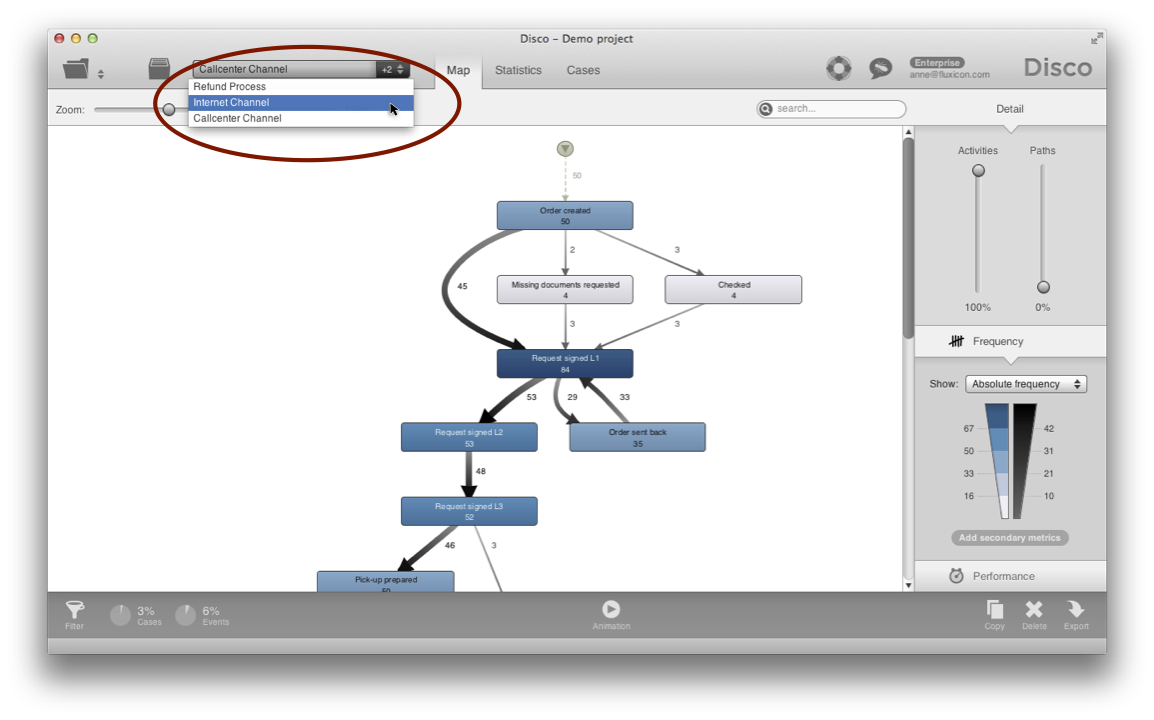
And this is the process for the Callcenter channel. Through the drop-down list you can quickly switch back and forth between them.
Strategy 5) Semantic Process Variants
A second way to split up the data set is by so-called semantic process variants. The idea here is that, again, there are multiple process types that should be separated, but in this case there is no attribute available that can be simply used to filter for this category.
Instead, the process variant exists implicitly, defined by the business perspective, based on the behavior in the process. For example, for the refund service process discussed above, the process owner made a clear distinction between cancelled and non-cancelled orders. They had made a separate process documentation for when cancellations are possible, so for them cancelled and non-cancelled processes were different process types and needed to be separated.
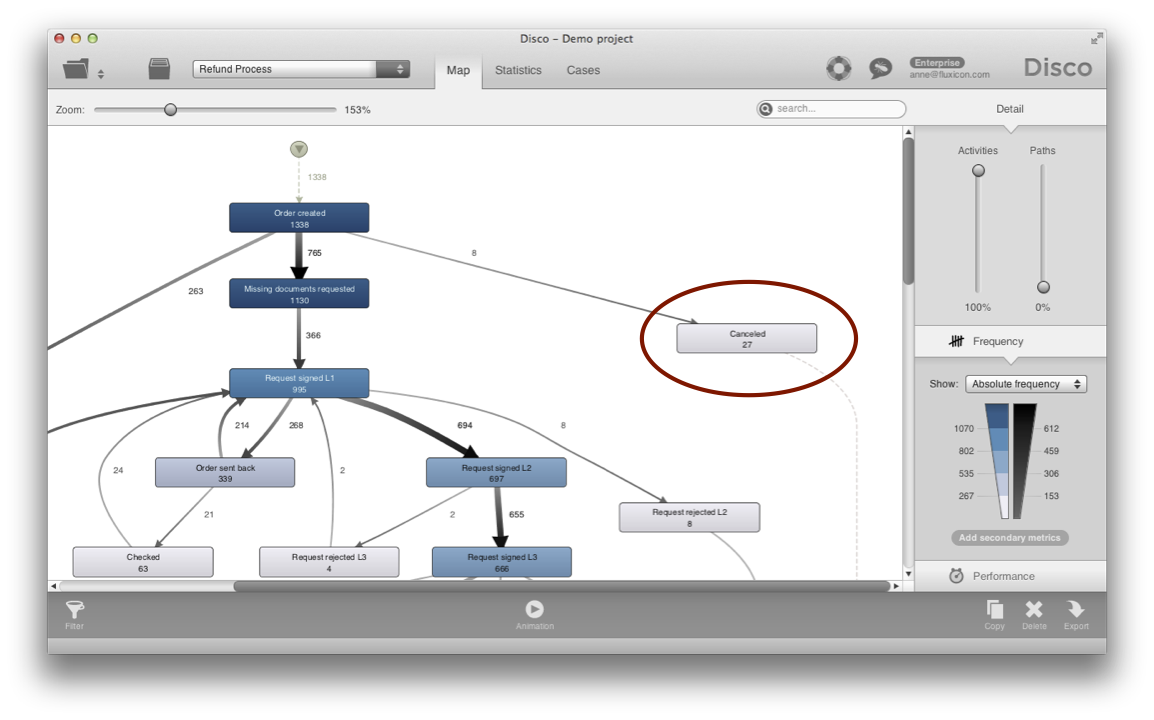
In Disco, you can simply click on an activity to filter cases that perform or do not perform a certain activity. A pop-over dialog with a button Filter this activity appears (see below).
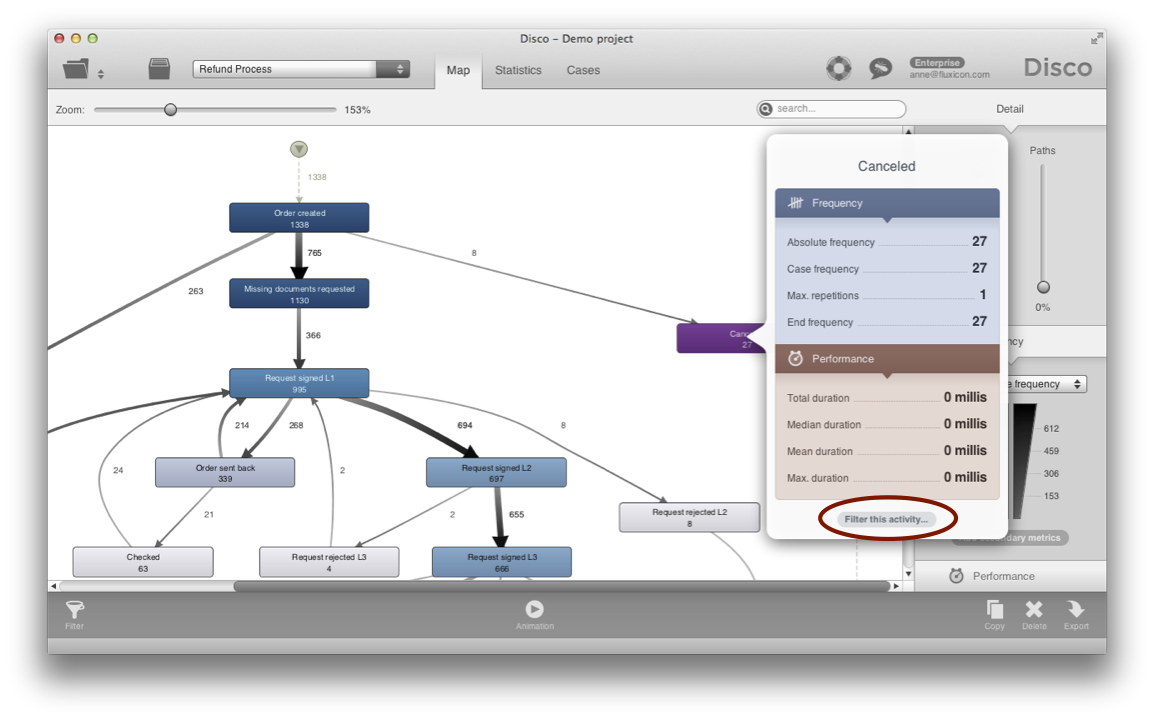
If you press this button, a pre-configured Attribute filter in Mandatory mode will be created (see below).
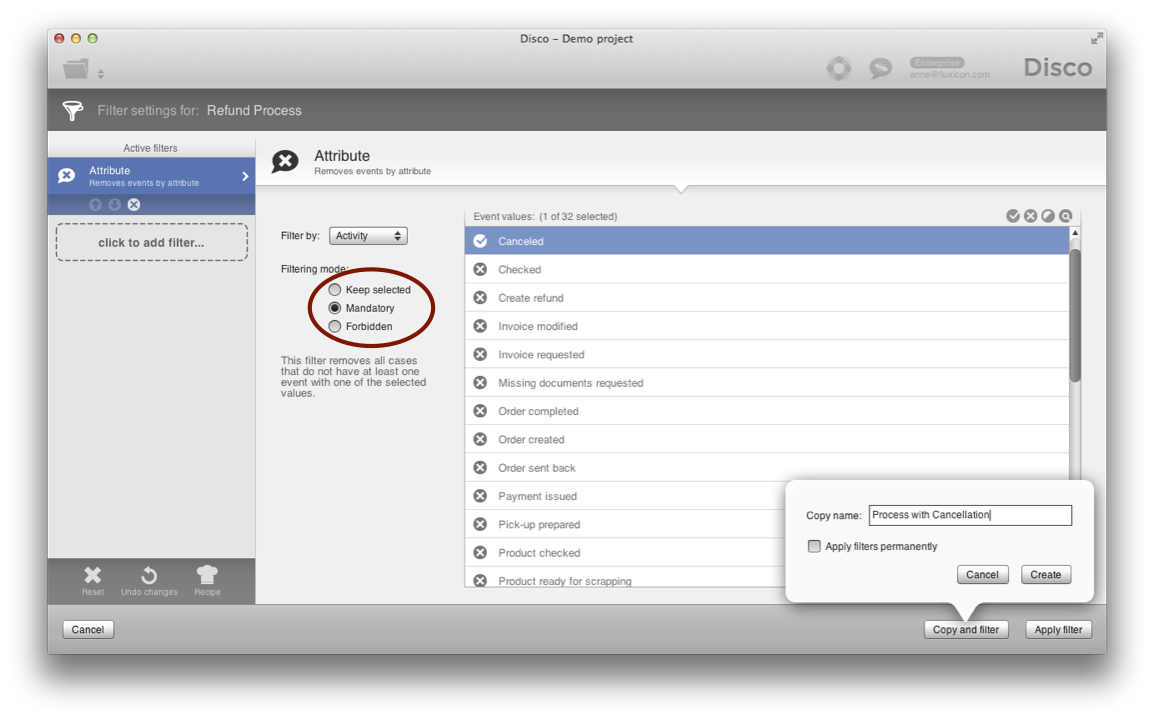
Applying this filter keeps only cases that at any point in the process performed the ‘Canceled’ activity (see below).
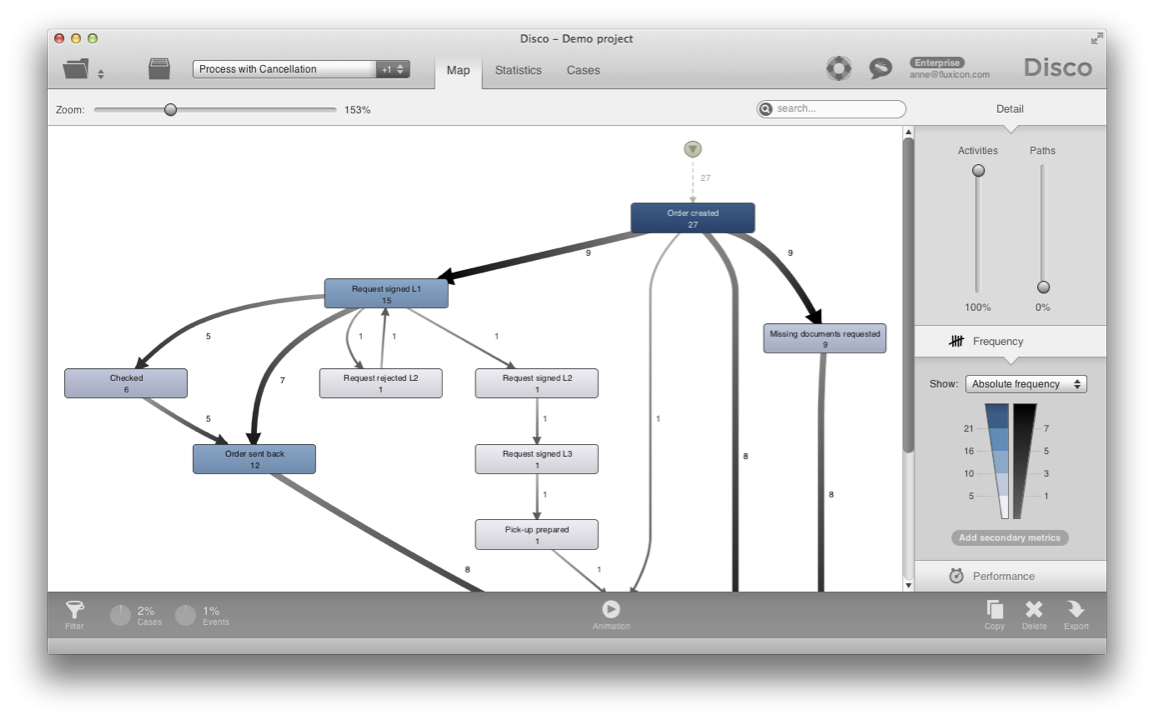
Conversely, you can use the Forbidden mode to remove all orders with the ‘Canceled’ activity from the data set (see below).
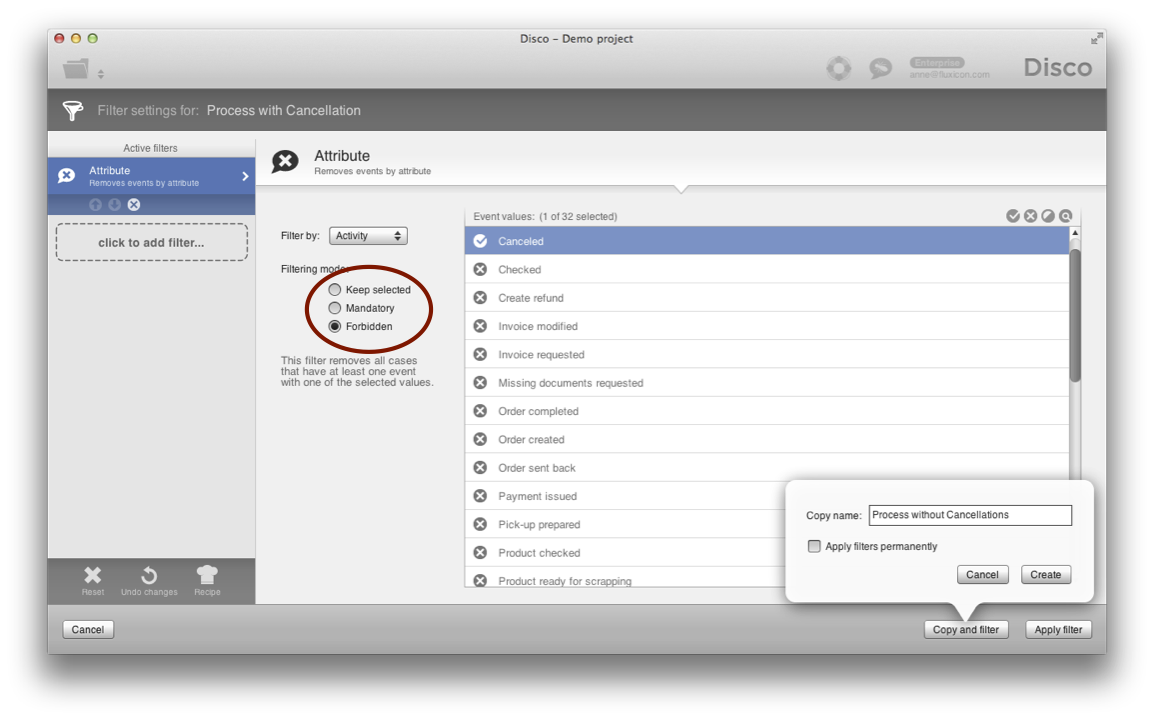
In this case, only those cases that never at any time in the process performed the Canceled activity remain. Again, you can make copies to keep your divided data sets separated and analyze what happened in canceled orders and in your normal process in isolation.
Compared to the process types filtered by attribute (see strategy No. 4), the semantic process variants are a bit more tricky. You need to talk to the process owner to understand how they look at the process. If they have documented their process, have they created different versions based on some variation of behavior in the process? Do they look at claims that need to be approved by the supervisor differently from the standard claims that can be handled directly by the clerk?
Once you have found out how the process is viewed from the stakeholders who work with it every day, process mining gives you a very powerful tool to quickly split up the process in the same way.
Next to the simple presence and absence of activities that was shown above, you can use many more behavior-based patterns for filtering. For example, the Follower filter can define rules about combinations of activities over time (does something happen before or after something else - directly in the next step or any time later, how much time has passed in between, was it done by the same person, etc.), and you can combine all of the above.
This is one of the greatest powers of process mining: That you can easily define behavior-based process patterns for filtering, without programming, in an interactive and explorative way!
Strategy 6) Breaking up Process Parts
A third way to break up your data set is to focus on a certain part of the process only. You can compare it to taking a pair of scissors and cutting out a part of the process.
Especially for very long processes with many different phases it can be useful to split up the different process parts and analyze them in isolation before putting everything together.

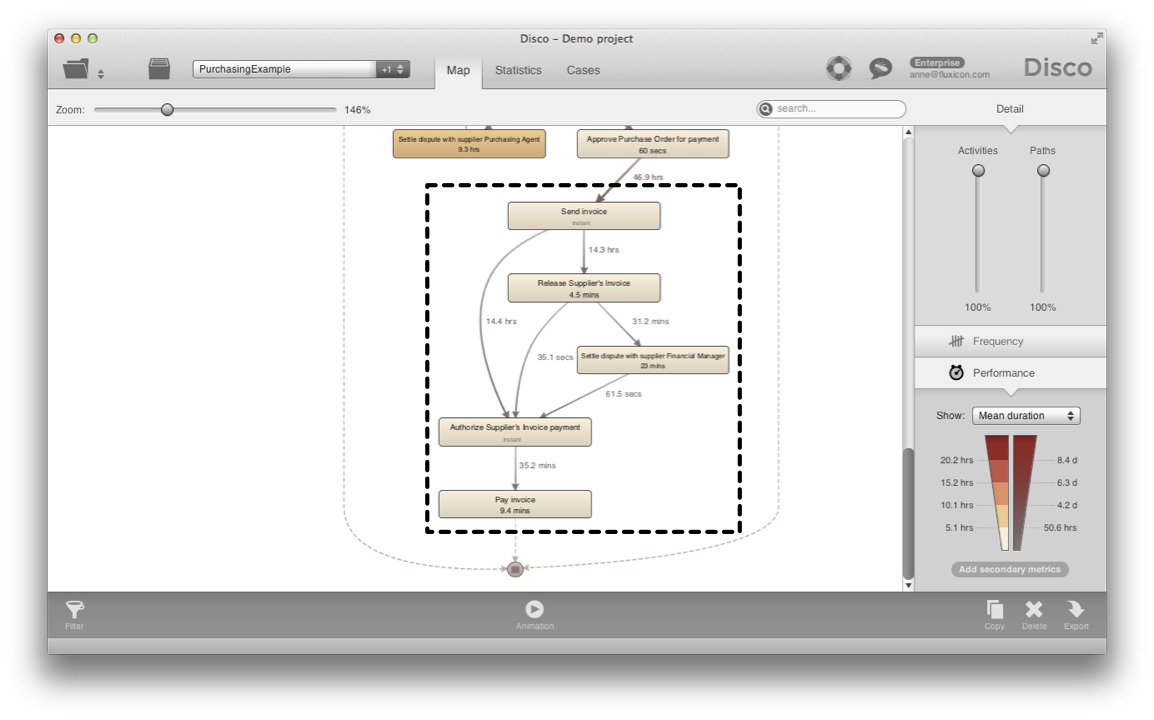
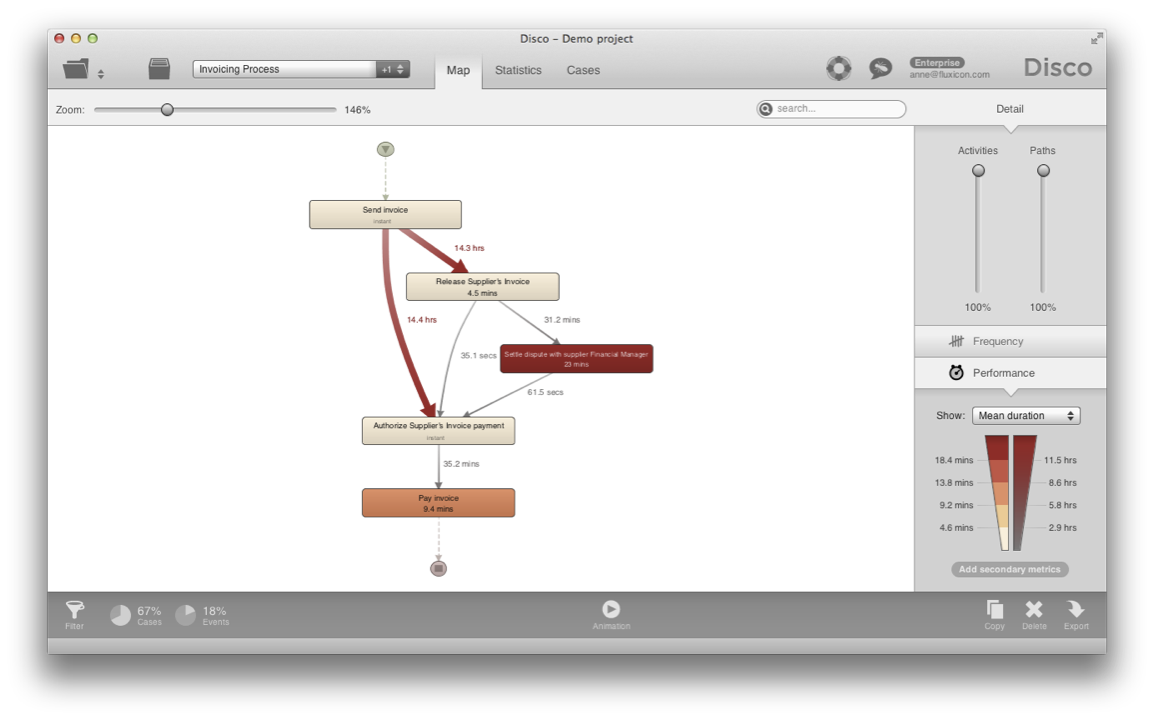
For example, let’s take the purchasing example that comes with the sandbox of Disco (see below). Now assume that you want to focus on the invoicing part of the process only, from the time that the invoice was sent until it was paid (and anything that happened in between).
We would like to cut out this part of the process (see dashed area mark-up for the part we want to focus on).
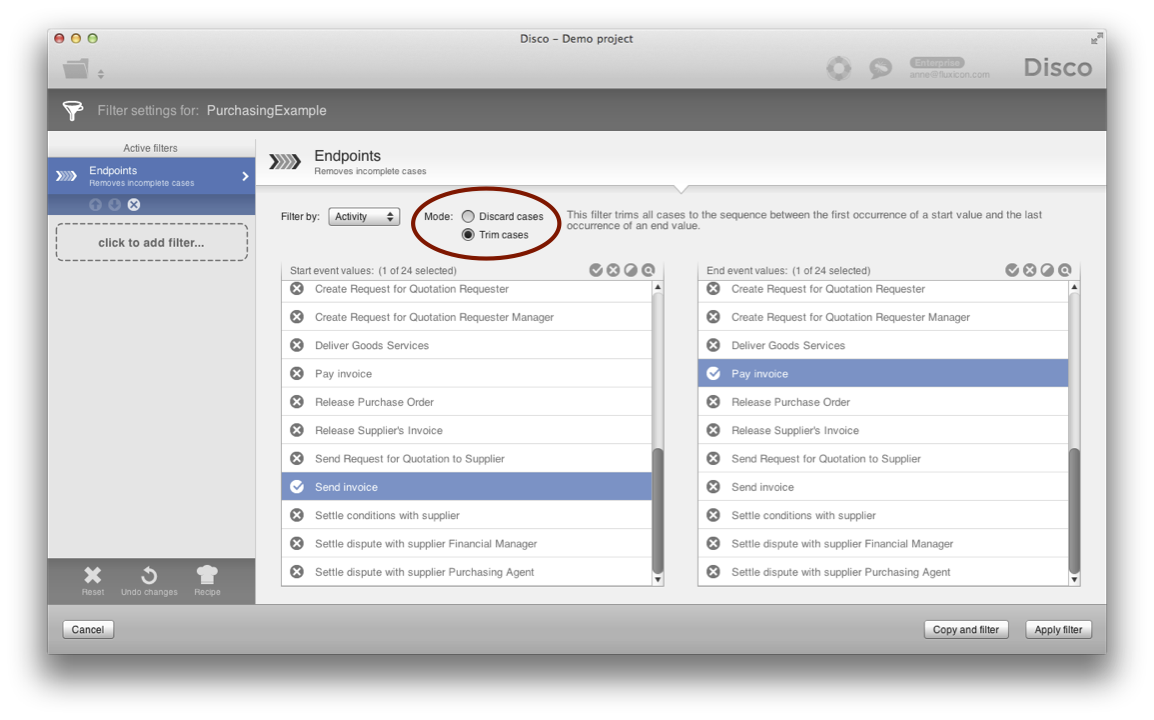
The Endpoints filter in Trim mode can be used for this (simply cuts all events before start and after end value):
As a result, we have now split up the invoicing process part from the rest of the process and can analyze it in isolation (see below).
Strategy 7) Different Start and End Points
A fourth divide and conquer strategy is to look at the start and end points of the process.
For example, in the following call center process the customer can start a service request either through a call or through an email, by filling out a form on the website. These different start points are highlighted in the process map by the two dashed lines from the start point (see below).
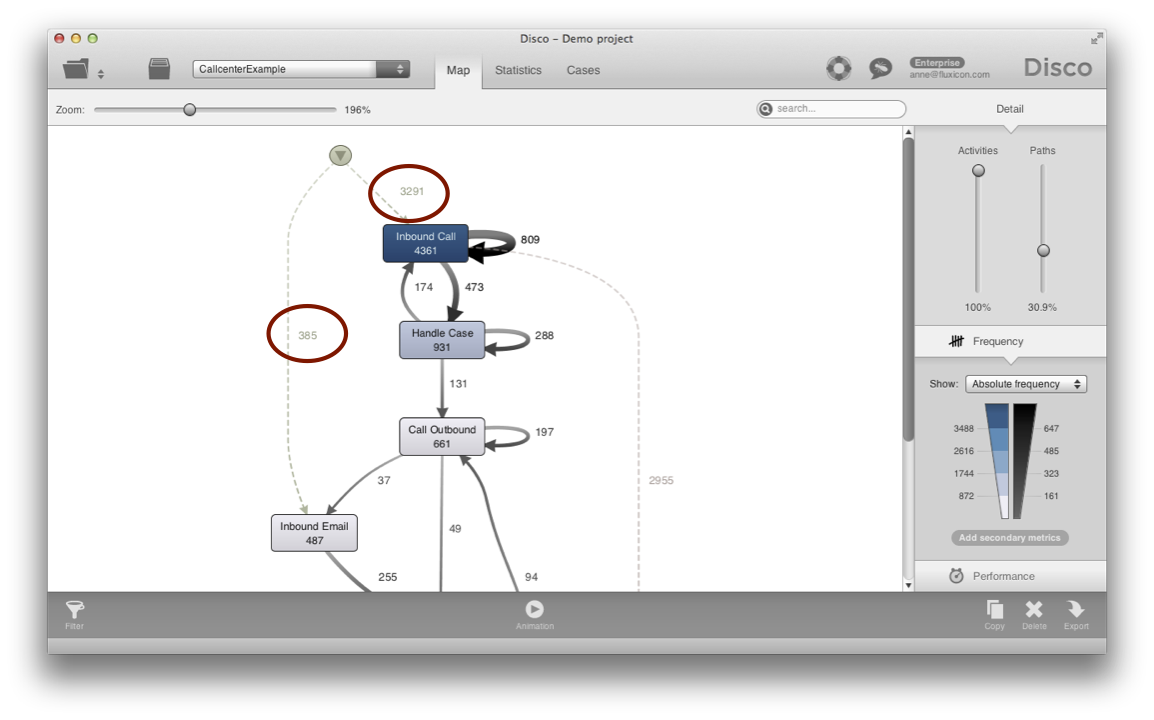
In some situations, the precise process and rules and expectations around the process change depending on how the process was initiated. For example, while it is often the goal to solve a customer problem in the first call (First call resolution rate) this is less realistic in an email thread, which typically needs more interactions to solve a request. This needs to be taken into account in the analysis.
While previously we have already looked at the Endpoints filter in Disco to remove incomplete cases, this time we can use the Endpoints filter to separate data sets based on their start or end points from a business perspective.
Note: _You will see that in many situations you can use the same filter either for cleanup or for analysis purposes, depending on the situation. _
In Disco, an Endpoints filter can also simply be added by clicking the dashed line in the process map (see below).
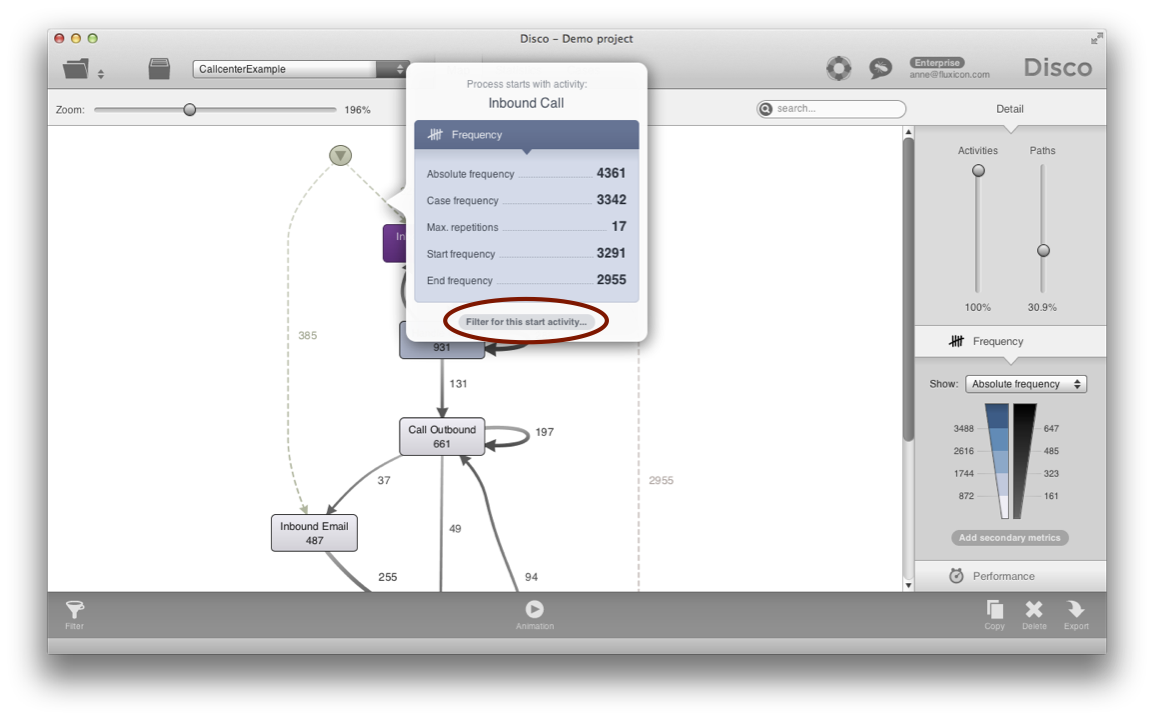
You can directly apply the pre-configured filter or, again, make copies to keep them separate (see below).
As a result, you can focus on the process just for cases that were started by an ‘Inbound call’ (see below) and, for example, analyze the first call resolution rate (looking at how many cases fall into the variant for just one ‘Inbound call’ and no further steps in the process).
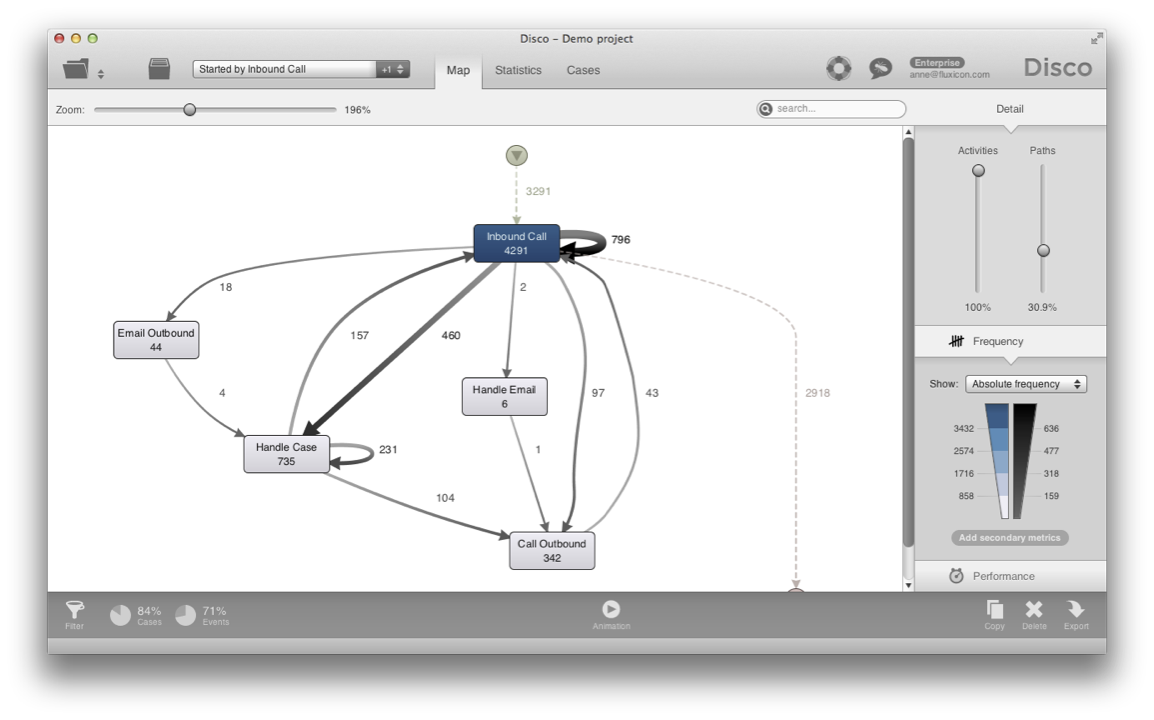
In the same way, we can also focus on the cases that were started by an incoming email, which involve more steps, because the agent needs to reply on the customer email before the case can be resolved (see below).
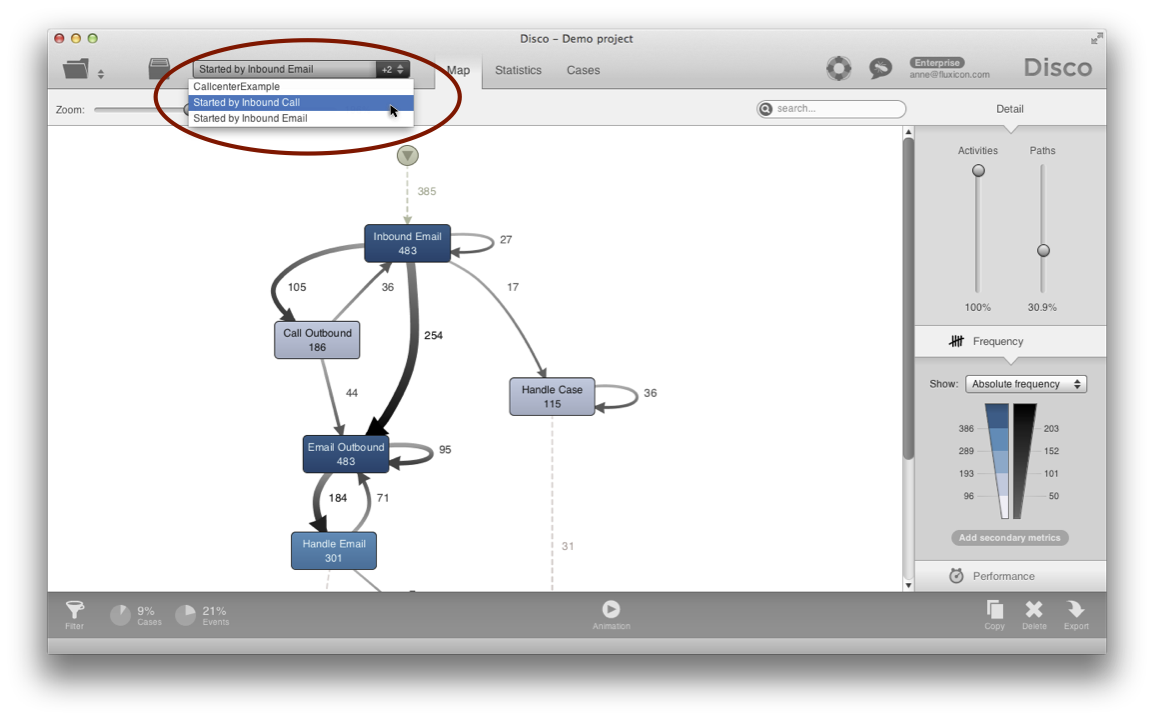
These were the four divide and conquer strategies. Watch out for Part IV, where we explain how leaving out details can help to significantly simplify your process maps.

Anne Rozinat
Market, customers, and everything else
Anne knows how to mine a process like no other. She has conducted a large number of process mining projects with companies such as Philips Healthcare, Océ, ASML, Philips Consumer Lifestyle, and many others.