Do you have some data that you want to analyze using process mining? Or would you just like to get some hands-on experience, but you don’t have any data? Then this post is for you.
In a previous post we had looked at the steps that need to be done before an event log can be loaded in ProM.
In this post, we continue with a first analysis of the call center demo file that you can download together with Nitro. You can step in right here and either use your own data or follow the steps using our example.
{kind=link}
Update 1: You should check out Disco. Disco does everything Nitro does (and much more) and is the successor of Nitro. You can still go from Disco to ProM if you want to (see the Disco User Manual here).
Update 2: I also recommend to take a look at this 1-hour introduction of ‘How to get started with Process Mining’ on YouTube! It explains all the basics and includes a live demo plus real-live application success stories.
Construct the Event Log
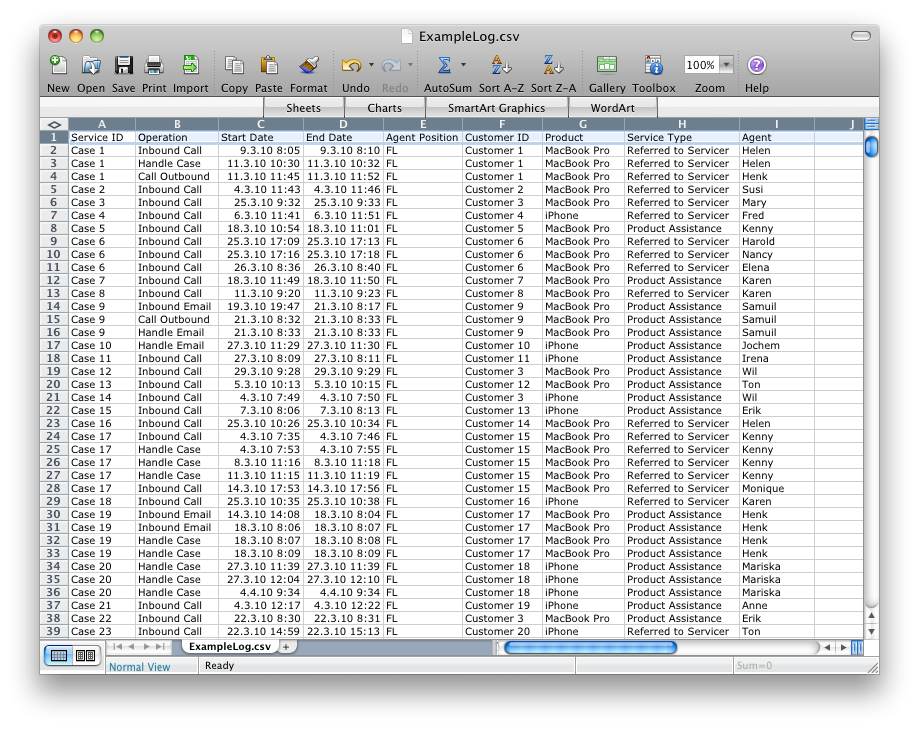
We start with the log data interpretation in Nitro as shown in the screenshot below. (Download the free demo version of Nitro here.)
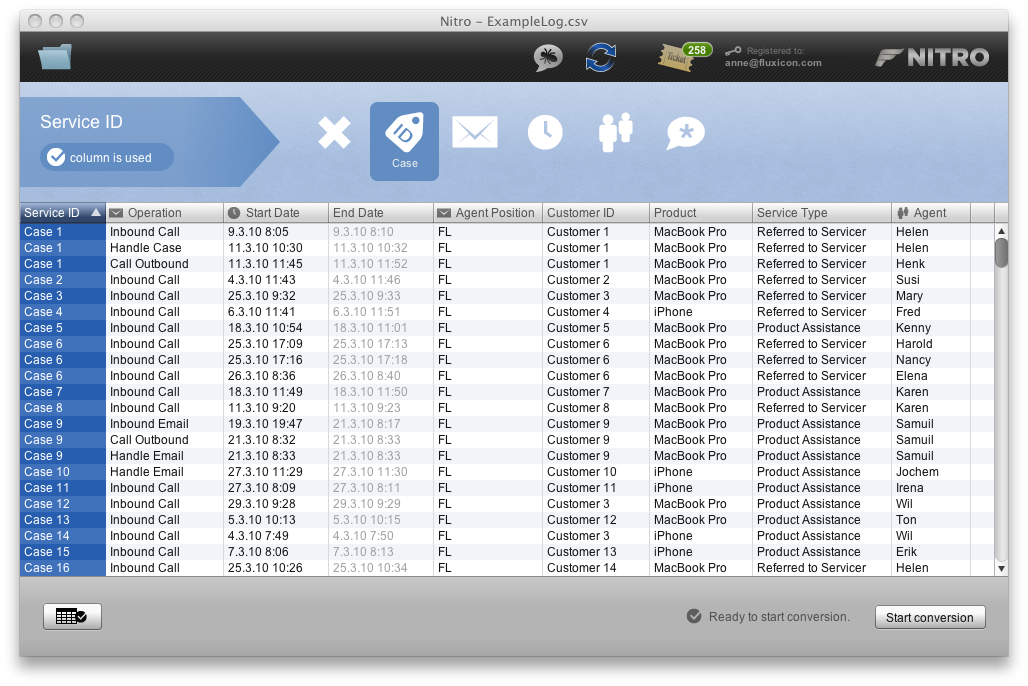
We will focus on the process flow and ignore the timing of the activities for now. Therefore, we only use the ‘Start Date’ column as a Timestamp. Ignore the ‘End Date’ column by setting it to Remove (the cross at the left). The other columns are configured as follows:
-
‘ServiceID’ column: Case (the case identifier);
-
‘Operation’ and ‘Agent Position’ column: Activity (together form the activity name);
-
‘Agent’ column: Resource (the person performing the activity);
-
All the remaining columns can be set to Other (which includes them as additional data attributes).
Alright! Now just press ‘Start conversion’. On the next screen, press ‘Export MXML file…’, choose a location, and save the event log. The exported log file can now be opened in ProM. (Download ProM here.)
Inspect the Event Log
Once you have loaded the log file in ProM, you will see the dashboard view of the log dialog as shown in the screenshot below.

It provides some overview information, such as:
-
The earliest event in the log occurred on March 1st and the last event on April 30th 2010 (see Start date and End date).
-
There are 3885 service instances in the event log (see Cases).
-
7548 activities were performed for these service calls (see Events).
-
9 different activities were recorded in the log (see Event classes).
-
48 agents have performed activities in the recorded time frame (see Originators).
Furthermore, in the chart in the upper middle part one can see that at least 1 and up to 30 activities were performed per case.
We can also inspect the event log in detail in the inspector tab of the log window, as is shown below.
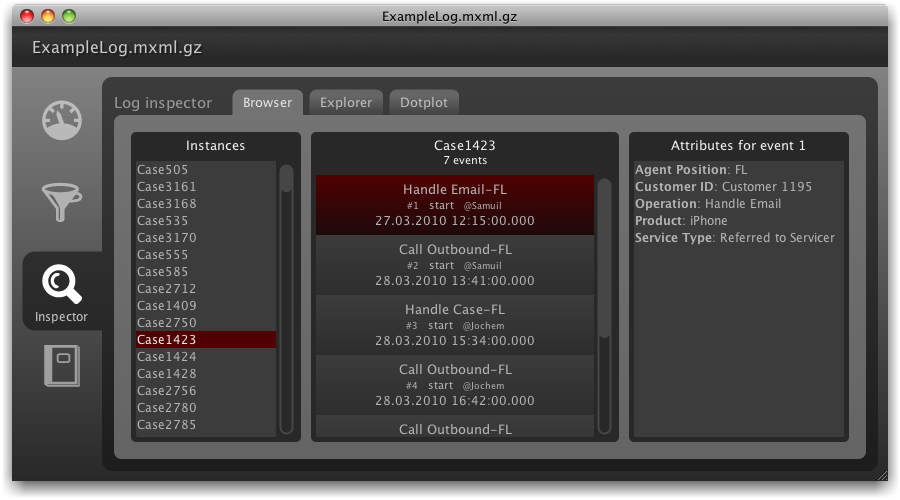
In the log inspector tab, you can view the particular event sequence for each individual process instance. The case shown in the screenshot above, service instance ‘Case1423’, starts with the activity ‘Handle Email-FL’, which means that an incoming customer email is being handled at the front line of the call center.
The person that handled the email was ‘Samuil’ and we can also see the date and time at which the activity started, plus some extra information about the product and service type on the right. The subsequent activity in this case was an outbound call, also done by Samuil, and so on.
As a next step, we want to discover a process model for the overall service process. The model will be constructed from the 3885 observed instances in the event log without any previous knowledge of how the process should look like.
Mining a Process Model
One good mining tool to start with is the Fuzzy miner: Go to the menu and select Mining –> Raw ExampleLog.mxml.gz (unfiltered) –> Fuzzy Miner from the menu. On the next screen, leave the default settings and press ‘start mining’.
The Fuzzy miner lets you interactively adjust the level of accuracy of the shown model. If you drag the slider in the ‘Node filter’ tab on the right to the very bottom, it shows you the process model that you can see in the screenshot below.
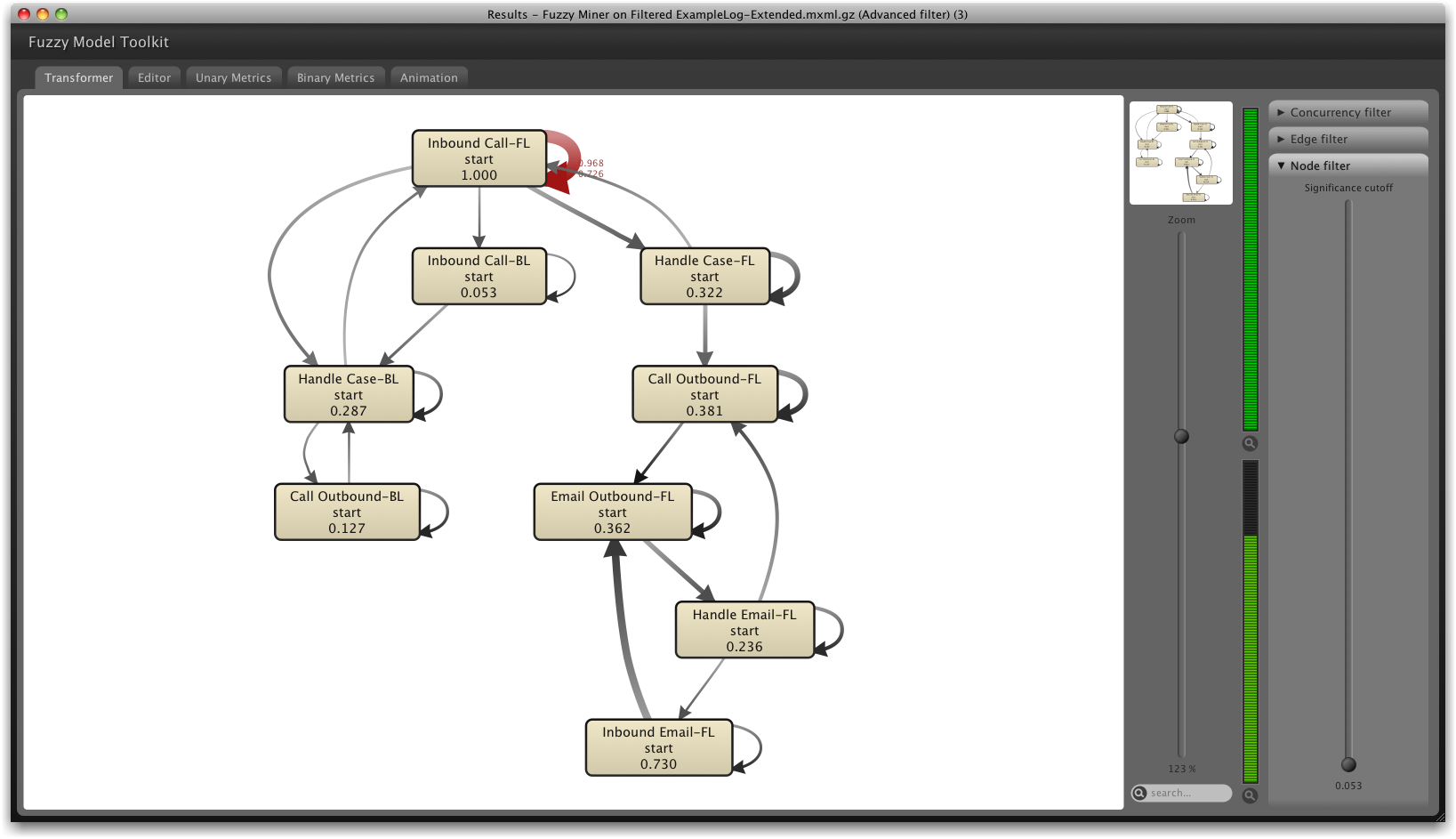
On the left side of the model, there are several activities that are happening in the back line of the call center (BL). The frontline activities (FL) are on the right. The numbers in the activity boxes indicate the relative frequency. So, the most frequent activity is the ‘Inbound call-FL’ activity at the top.
The thickness of the arcs indicates how often two activities have been executed after another. For example, one can see that there are quite a number of repeat inbound calls (highlighted by the red arc). With the goal of “First contact resolution” these repeat calls are something you would want to minimize in a call center setting.
Animating a Process Model
One of the nice features of the Fuzzy miner is that you can also animate the process model. This means that you can create an animation of the activities in the event log directly in the process model that was created from the same event log.
To do this, go to the ‘Animation’ tab in the Fuzzy miner. I suggest to pull the ‘Lookahead’ slider to the very left, which means that you will see just one token moving around the process for each case. Then, press ‘view animation’.
The resulting animation for the call center example log is shown in the video below.
Well that’s it! There is a lot more functionality in ProM, and finding your way can be quite daunting. However, getting a first process model and creating an animation from it is not difficult at all.
So, have a try and let me know if you could do it, or if you got lost somewhere on the way.

Anne Rozinat
Market, customers, and everything else
Anne knows how to mine a process like no other. She has conducted a large number of process mining projects with companies such as Philips Healthcare, Océ, ASML, Philips Consumer Lifestyle, and many others.