Let’s assume you have heard about process mining and are all excited about trying it out in your own organization. Maybe you want to make a showcase to further promote the topic in your company. Or you are a researcher who wants to apply process mining with one of your industrial partners.
How do you actually get started?
I’ll try to give you a checklist for the very first steps here in this post.
Step 1: Which process?

At first, you will have to pick a process that you want to analyze. It is best if the process is clearly defined (you know what actions belong to it) and executed frequently. Ideally, you start with a somewhat simple process that is still relevant and could be improved.
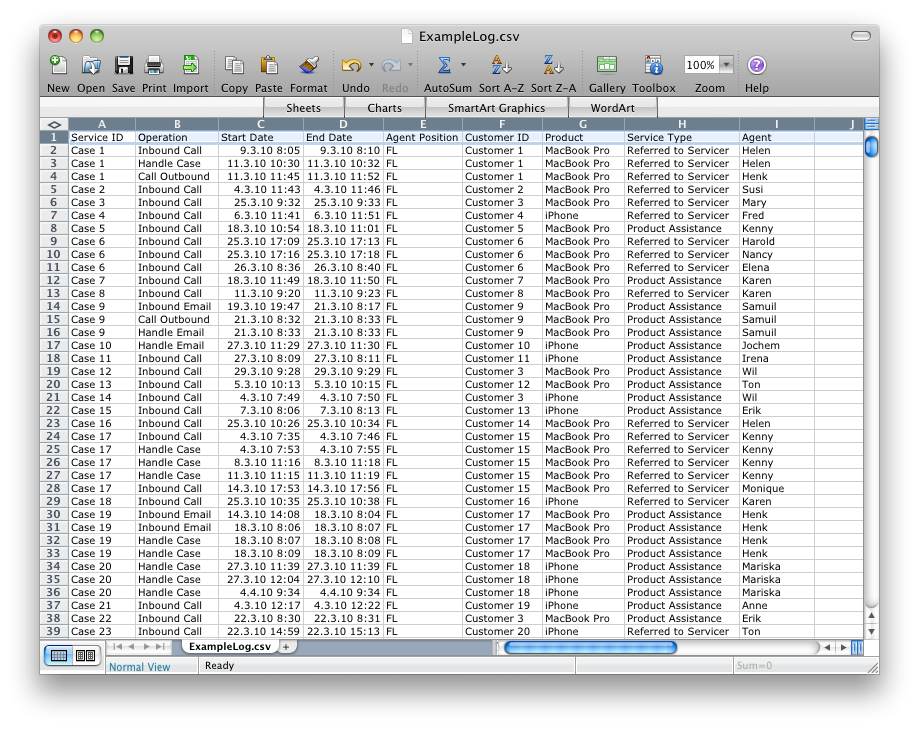
For example, in the picture above you can see a simplified example of a customer service process at a call center. In this call center, customers can get in touch either via phone or via a web form (which sends an email to the call center).
Also think about the questions that you want to answer: Do you want to know how the process looks like? Which the most frequent and/or slowest paths and activities are? Or do you also want to analyze the organizational perspective, for example, how work is being transferred between different departments?
The questions that you have can influence the data that you want to extract.
Step 2: Which IT systems are involved?

Any IT system involved in the execution of the process may contain relevant data! Look out especially for workflow systems, CRM systems, and ERP systems. Their data is often most closely related to the executed process, and contains the most interesting information. However, also custom systems and spreadsheets can be analyzed.
Depending on the type of involved systems you have identified, your data may be stored in a number of places. Databases are typical for large process-supporting systems and custom or legacy systems. Other systems store event logs in flat file formats. You may have to turn the logging functionality of your systems on before data is recorded.
In the call center example, all activities are recorded in a Siebel CRM system.
You probably want to sit together with an administrator to help you with the data extraction. While he most likely will create the data dump for you, you will have to tell him exactly what kind of data you need, in which format, and so on.
Step 3: The required format
Often, when people ask about the “required format” they mean everything, including content, time frame, etc. - not just the actual file format.
So, let’s look at the different ingredients step by step.
The actual file format
It’s usually easiest to extract a plain Comma Separated Values (CSV) file, where each row corresponds to an activity that happened in the process and each column gives some information about the context of that activity.
Just watch out that the delimiting character (comma, semicolon, tab, space, or any other character) does not occur in the actual content of any of the columns.
Which columns you should have
This is the meat. The data columns determine the analysis possibilities that you have later on and here is where the real process mining requirements come into play.
Let’s look at the basics first.
Case ID
A case is a specific instance of your process. If you look at an ordering process, for example, handling one order is one case. For every event, you have to know which case it refers to, so that the process mining tool can compare several executions of the process to one another.
So, you need to have one or more columns that together uniquely identify a single execution of your process, which form a case ID.
Rule #1: The case ID determines the scope of the process.
Be aware that there may be more than one way to set up a case ID. For example, in the call center service process above you might see the processing of a particular service request as the process you want to analyze. Then the service request ID is your case ID. At the same time, you may want to see the overall service process for a customer as your process scope. Then the customer ID is your case ID.
In your analysis you may take different views on the process and analyze it from different perspectives. The important part for now is that you have at least one column that can be used to distinguish your process instances and serve as a case ID.
Activity name
An activity forms one step in your process. For example, a document authoring process may consist of the steps ‘Create’, ‘Update’, ‘Submit’, ‘Approve’, ‘Request rework’, ‘Revise’, ‘Publish’, ‘Discard’ (performed by different people such as authors and editors). Some of these steps might occur more than once for a single case while not all need to happen every time.
Events can record not only activities you care about, but also less interesting debug information. Look for events which describe the interesting activities. While you can also filter out less relevant events later in the analysis, it is helpful to start off with data that is as clean as possible.
Rule #2: The activity name determines the level of detail for the process steps.
Again, there may be more than one view on what makes up an activity. For example, in the call center service process above the operation attribute (‘Inbound Call’, ‘Handle Case’, etc.) contains the obvious process steps you want to analyze. Then the operation is your activity name.
A discovered process model based on just the operation as process step looks like the model below.
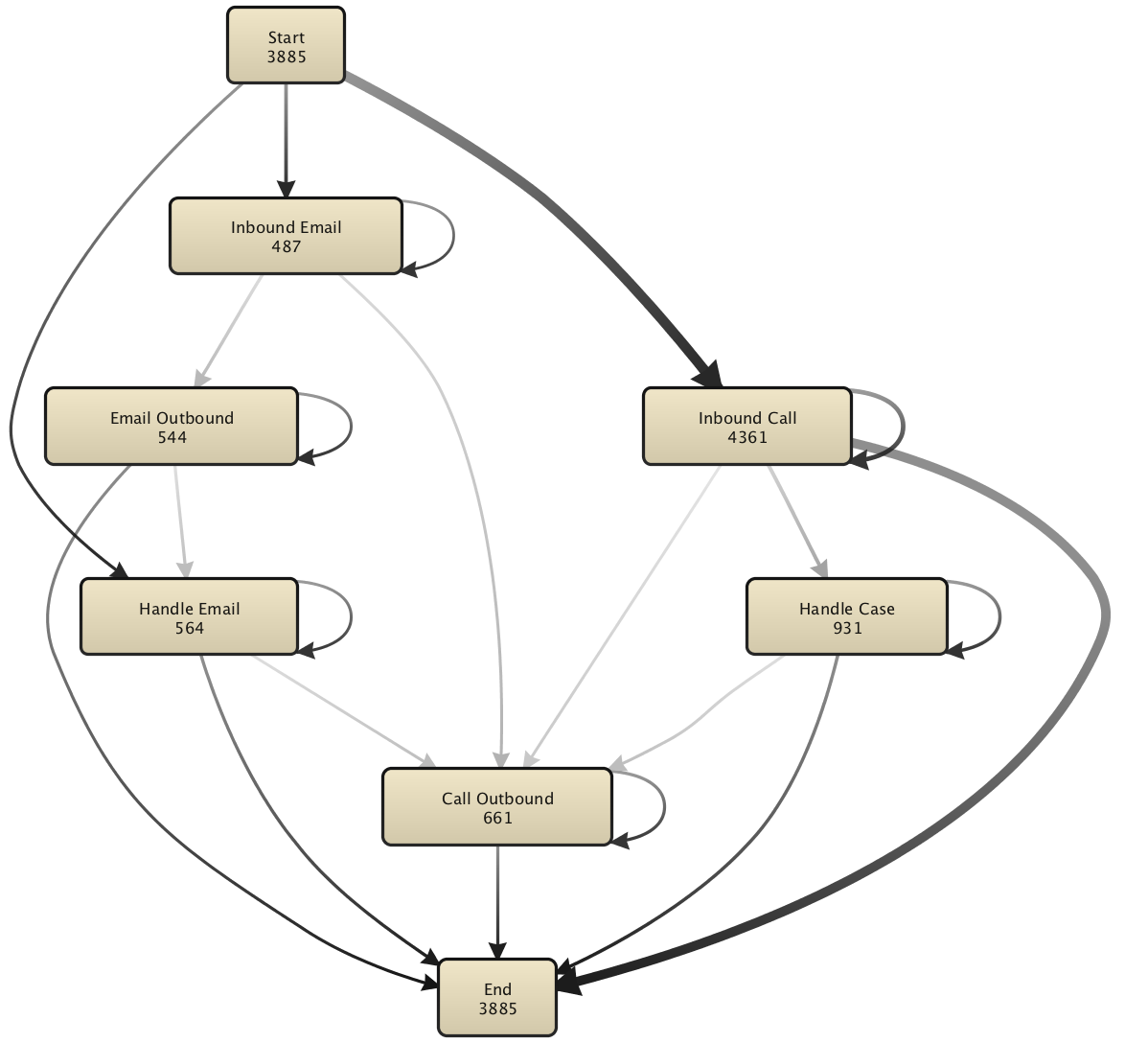
At the same time, you may want to distinguish activities that take place in the 1st level support (FL: Front Line) and in the 2nd level support (BL: Back Line) of the call center. Then the operation attribute and the agent position together form your activity name.
In this situation, the discovered process model distinguishes process steps based on the agent position as shown in the picture below.

The important part for now is that you have at least one column that can be used to distinguish your process steps and serve as an activity name.
Timestamp
The third important prerequisite for process mining is to have a timestamp column that indicates when the activity took place. This is not only important for analyzing the timing behavior of the process but also to establish the order of the activities in your event log1.
Rule #3: If you don’t have a sequentialized log file, you need timestamps to determine the order of the activities in your process.
Often, an activity is represented by multiple events. For example, you may have information about when an activity was started and when it was completed. This is good. It allows you analyze the processing time of an activity (the time someone actively spent on performing that task). Include the start and the end time in two separate columns2.
Finally, there may be more attributes that describe specific properties that are relevant to answer the questions that you have about your process. What kind product was the service request about (needed to compare performance for different product categories)? By which person was the activity handled (needed for organizational handover analysis)? Is there more information, for example the value of an order?
Include any attributes you find relevant because they can improve the significance and value of the analysis. However, the Case ID, the Activity name, and the Timstamp information are the only fixed requirements.
Which time frame the log should cover
As a rule of thumb, try to get data for at least 3 months. Depending on the run time of a single process instance it may be better to get data for up to a year. For example, if your process usually needs 5-6 months to complete, a 3-month-long sample will not get you even one complete process instance!
Step 4: Create the event log

If you understood your data and selected the columns that you want to include, then the actual event log construction is a snap. We created Nitro to help you save time in this technical translation step while giving you some flexibility to alter what columns you see as the Case ID, Activity name, and so on.
Simply tell Nitro for each column what it means, and it will try to be smart about it. For example, you can combine multiple columns into the Case ID, Activity name, etc. to take different views on your process. We also adapt to your timestamp pattern rather than making you use ours.
Try it out with the call center example log, which comes with Nitro, or with your own data.
Update 1: You should check out Disco. Disco does everything Nitro does (and much more) and is the successor of Nitro. You can also find an updated version of this How-To post in the data extraction guide in the Disco User Manual here.
Update 2: I also recommend to take a look at this 1-hour introduction of ‘How to get started with Process Mining’ on YouTube! It explains all the basics and includes a live demo plus real-live application success stories.
Step 5: Open event log in ProM

The exported event log can be directly opened in ProM 5 or ProM 6.
How to get started with the analysis does not fit anymore in this (already too long) article. It will be covered in a future post.
Was this useful? Did you miss something or did not get it? Let me know what you think.
-
It is a problem if your timestamps capture only the date but not the time of the event if there can be more than one event for the same process instance on the same day. The order of the activities in your process model may be distorted if the event sequences cannot be constructed correctly. Similarly, errors in manually entered timestamps can cause problems because they tamper with the true process flows. ↩︎
-
If you have just one timestamp you can still analyze the time between two process steps, although you won’t be able to distinguish the inactive waiting time (where nobody actually worked on the process instance) and the active processing or execution time. ↩︎

Anne Rozinat
Market, customers, and everything else
Anne knows how to mine a process like no other. She has conducted a large number of process mining projects with companies such as Philips Healthcare, Océ, ASML, Philips Consumer Lifestyle, and many others.