
This is the sixth article in our series on data quality problems for process mining. Make sure you also read the previous articles on formatting errors, missing data, Zero timestamps, wrong timestamp configurations, and same timestamp activities. You can find an overview of all articles in the series here.
In the previous article on same timestamp activities we have seen how timestamps that do not have enough granularity can cause problems. For example, if multiple activities happen at the same day for the same case then they cannot be brought in the right order, because we don’t know in which order they have been performed. Another timestamp-related problem you might encounter is that your dataset has timestamps of different granularities.
Let’s take a look at the example below. The file snippet shows a data set with six different activities. However, only activity ‘Order received’ contains a time (hour and minutes).
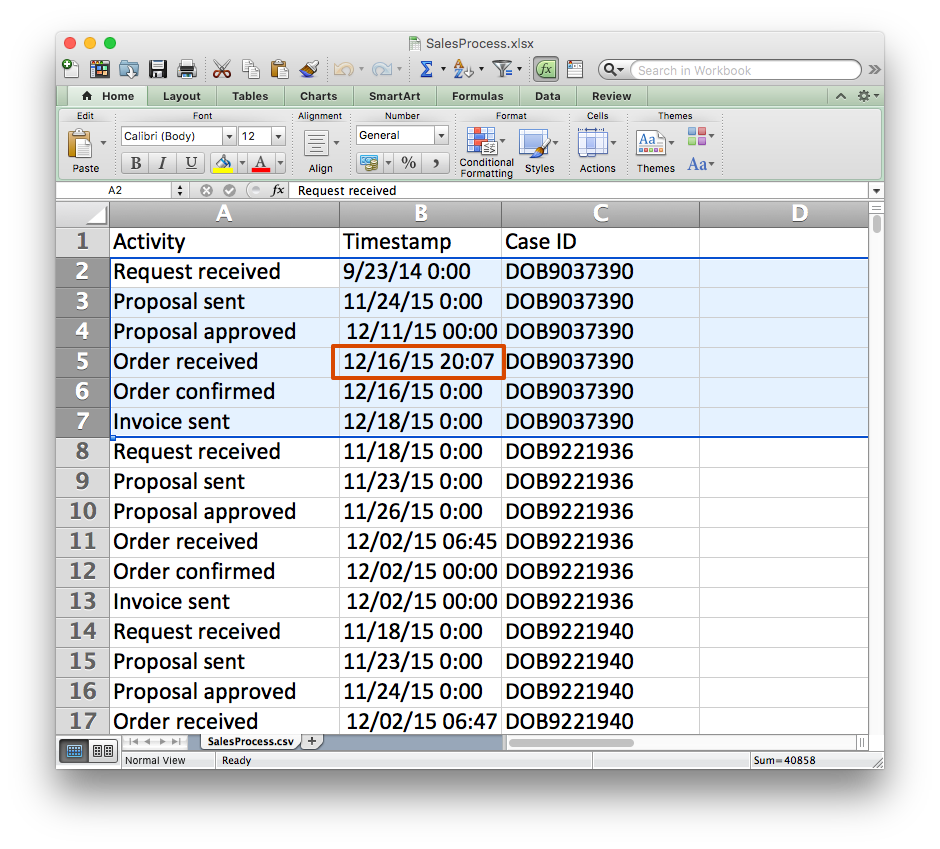
Note that in this particular example there is no issue with fundamentally different timestamp patterns. However, a typical reason for different timestamp granularities is that these timestamps come from different IT systems. Therefore, they will also often have different timestamp patterns. You can refer to the article How To Deal With Data Sets That Have Different Timestamp Formats to address this problem.
In this article, we focus on the problems that different timestamp granularities can bring. So, why would this be a problem? After all, it is good that we have some more detailed information on at least one step in the process, right? Let’s take a look.
When we import the example data set in Disco, the timestamp pattern is automatically matched and we can pick up the detailed time 20:07 for ‘Order received’ in the first case without a problem (see screenshot below).
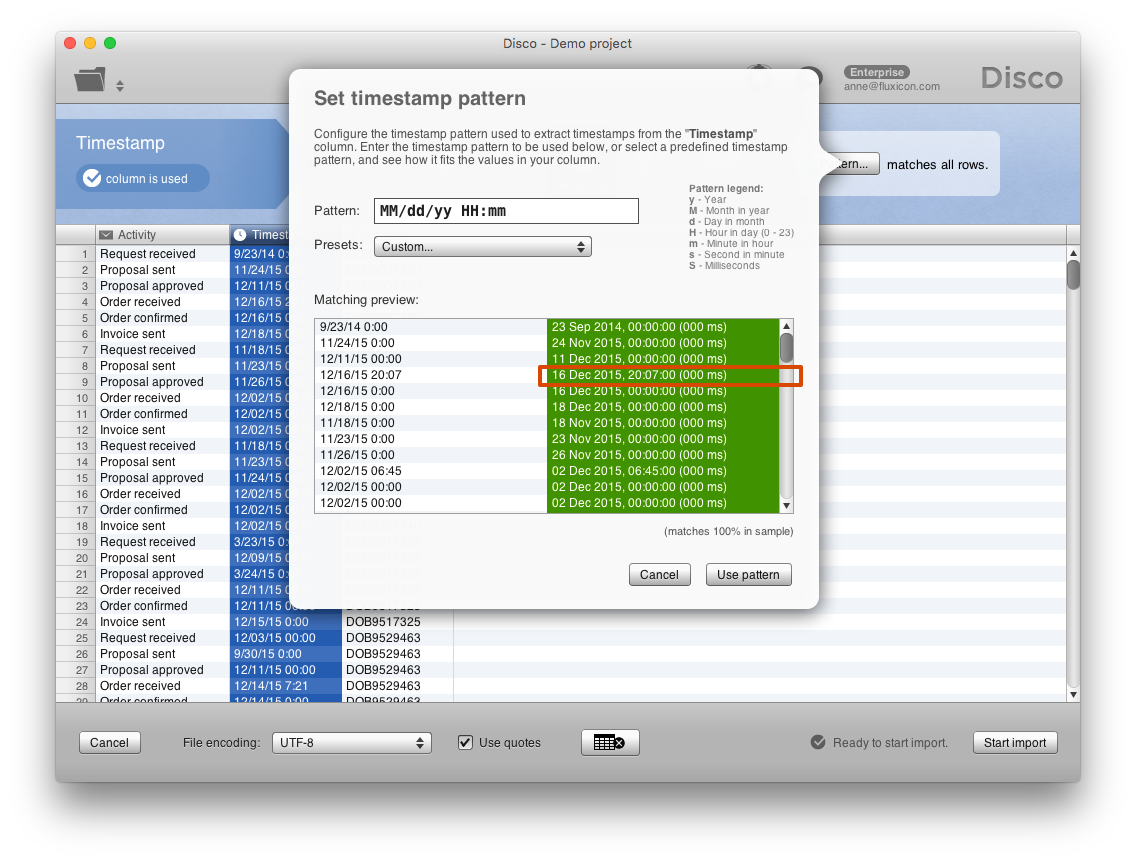
The problem only becomes apparent after importing the data. We see strange and unexpected flows in the process map. For example, how can it be that in the majority of cases (1587 times) the ‘Order confirmed’ step happened before ‘Order received’?
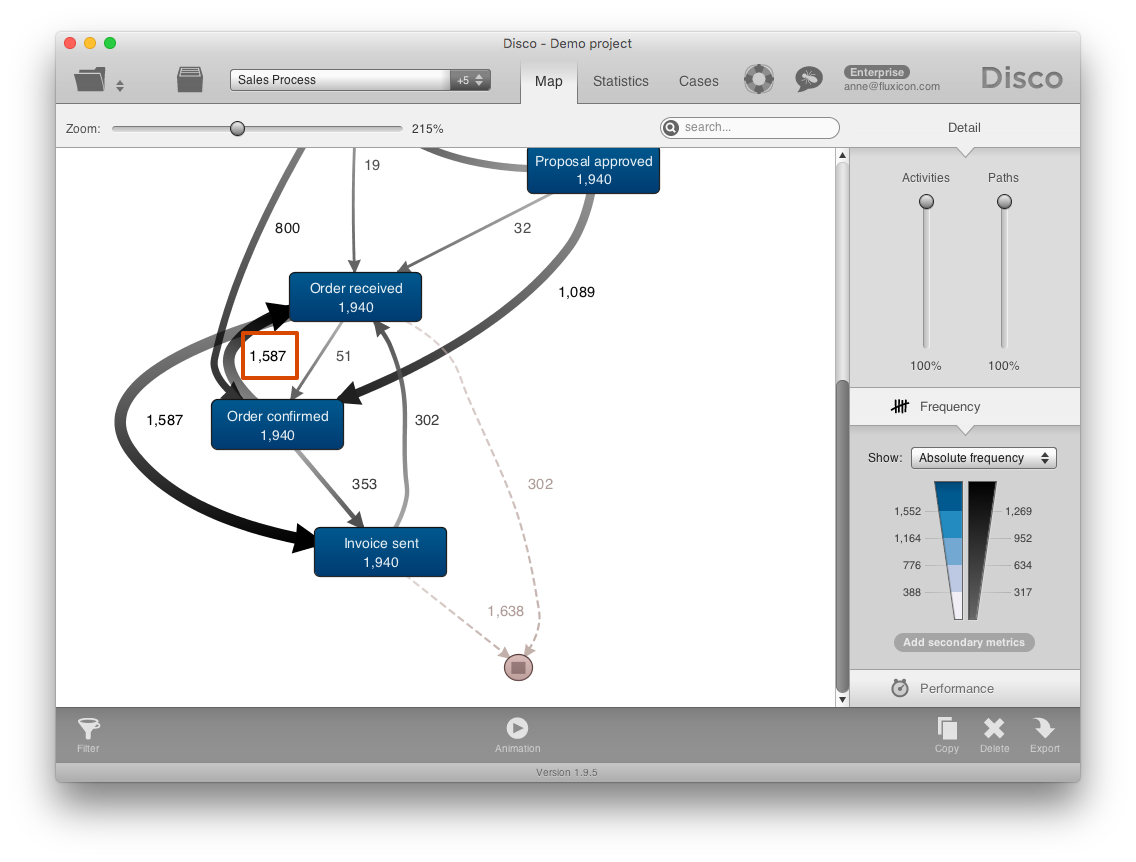
That does not seem possible. So, we click on the path and use the short-cut Filter this path… to keep only those cases that actually followed this particular path in the process (see screenshot below).
We then go to the Cases tab to inspect some example cases (see screenshot below). There, we can immediately see what happened: Both activities ‘Order received’ and ‘Order confirmed’ happened on the same day. However, ‘Order received’ has a timestamp that includes the time while ‘Order confirmed’ only includes the date. For activities that only include the date (like ‘Order confirmed’) the time automatically shows up as “midnight”. Of course, this does not mean that the activity actually happened at midnight. We just don’t know when during the day it was performed.
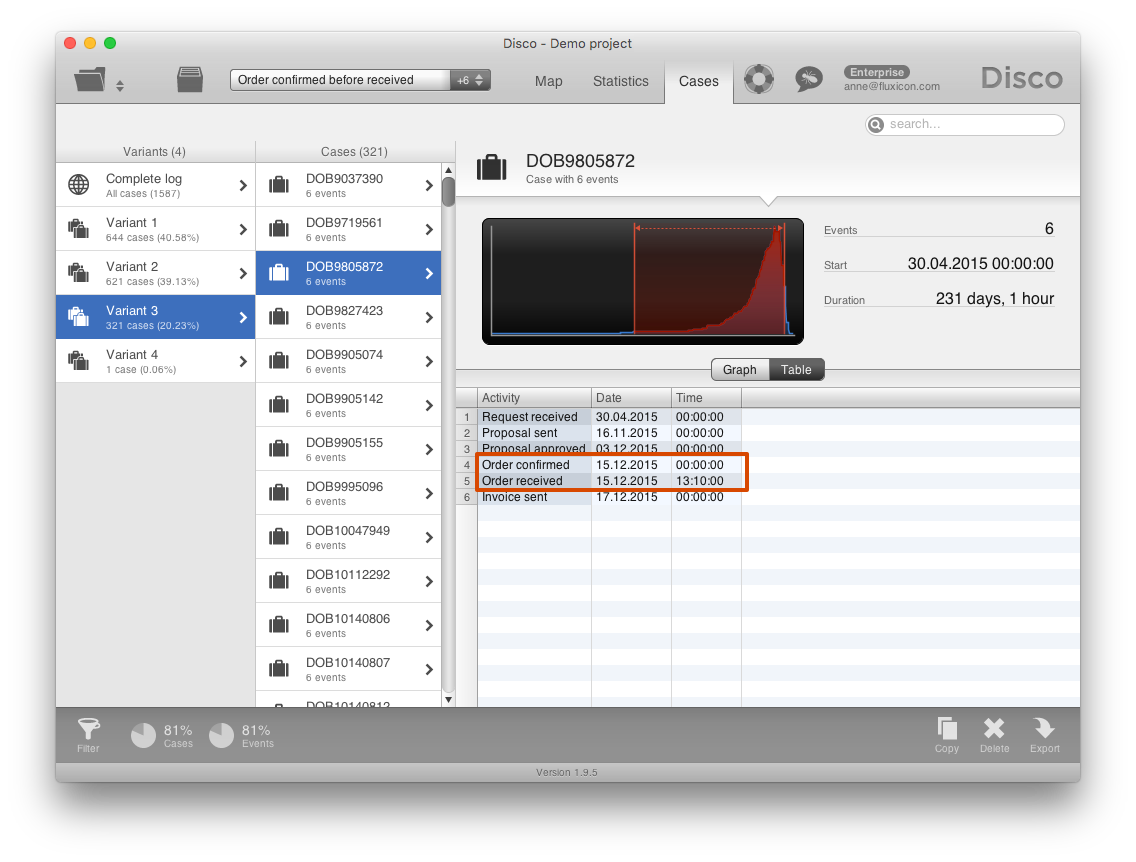
So, clearly ‘Order confirmed’ must have taken place on the same day after ‘Order received’ (so, after 13:10 in the highlighted example case). However, because we do not know the time of ‘Order confirmed’ (a data quality problem on our end) both activities show up in the wrong order.
How to fix:
If you know the right sequence of the activities, it can make sense to ensure they are sorted correctly (Disco will respect the order in the file for same-time activities) and then initially analyze the process flow on the most coarse-grained level. This will help to get less distracted from those wrong orderings and get a first overview about the process flows on that level.
You can do that by leaving out the hours, minutes and seconds from your timestamp configuration during import in Disco (see an example below in this article).
Later on, when you go into the detailed analysis of parts of the process, you can bring up the level of detail back to the more fine-grained timestamps to see how much time was spent between these different steps.
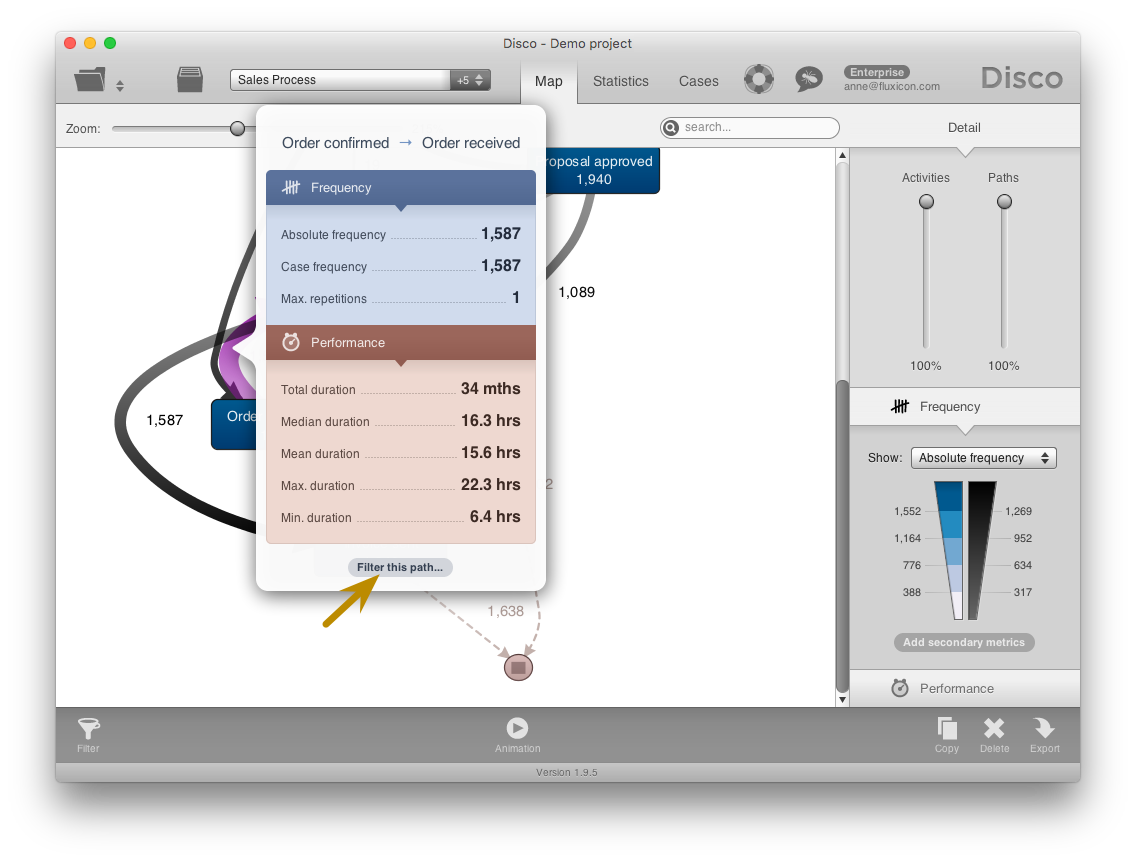
To make sure that ‘Order confirmed’ activities are not sometimes recorded multiple days earlier (which would indicate other problems), we filter out all other activities in the process and look at the Maximum duration between ‘Order confirmed’ and ‘Order received’ in the process map (see screenshot below). The maximum duration of 23.3 hours confirms our assessment that this wrong activity order appears because of the different timestamp granularities of ‘Order received’ and ‘Order confirmed’.
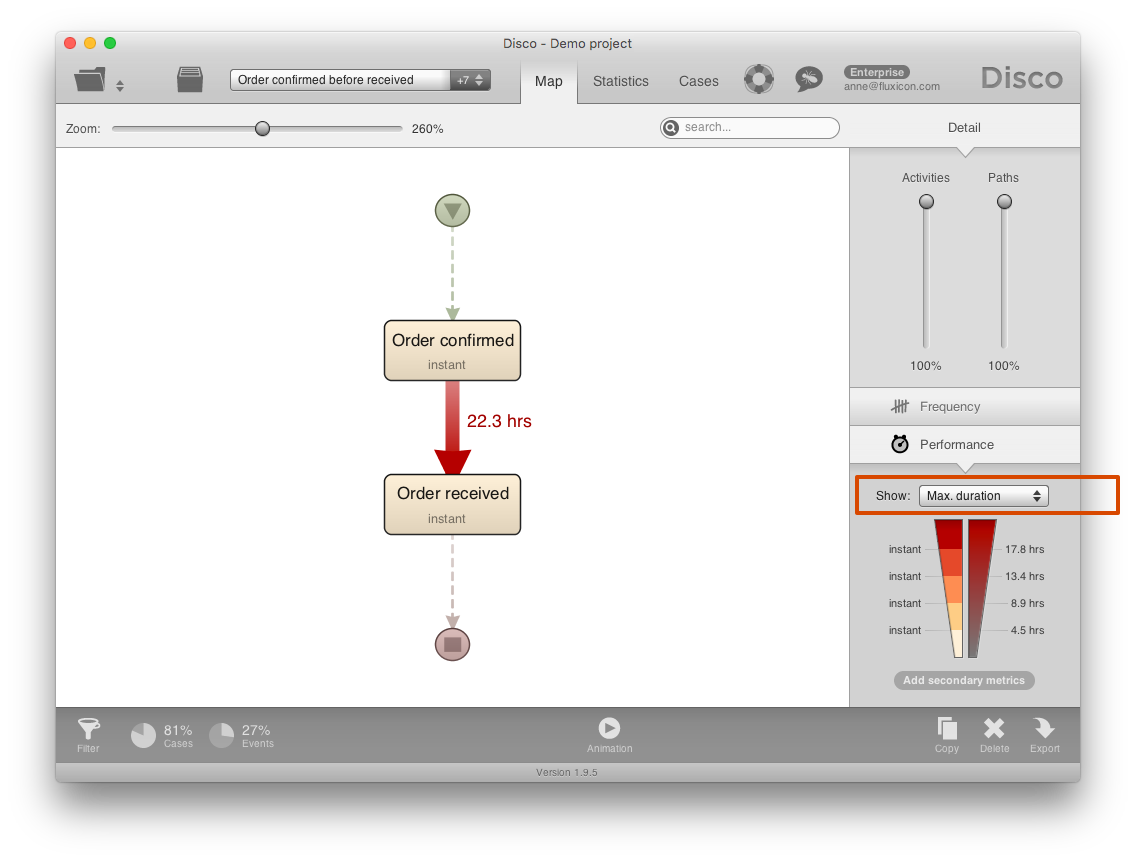
So, what can we do about it? In this particular example, the additional time that we get for ‘Order received’ activities does not help that much and causes more confusion than good. To align the timestamp granularities, we choose to omit the time information even when we have it.
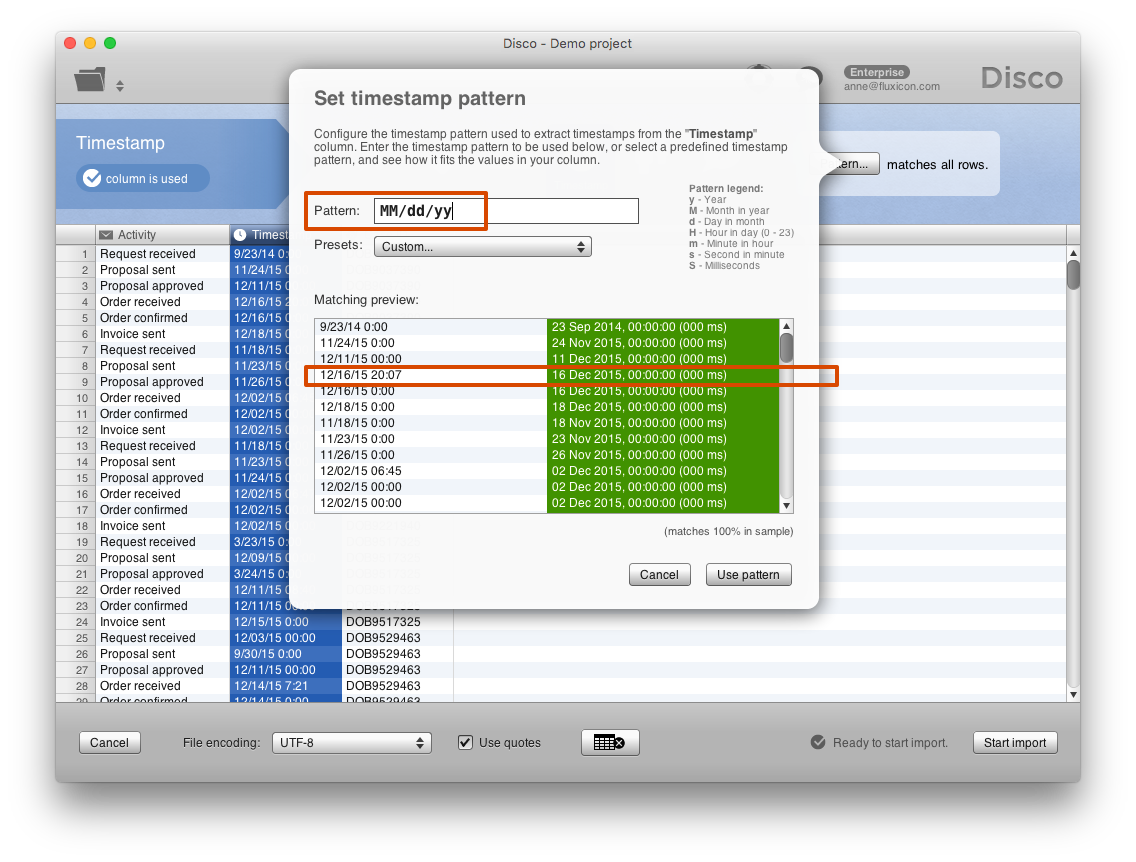
To scale back the granularity of all timestamps to just the date is easy: You can simply go back to the data import screen, select the Timestamp column, press the Pattern… button to open the timestamp pattern dialog, and then remove the hour and minute component by simply deleting them from the timestamp pattern (see screenshot below). As you can see on the right side in the matching preview, the timestamp with the time 20:07 is now only picked up as a date (16 December 2015).
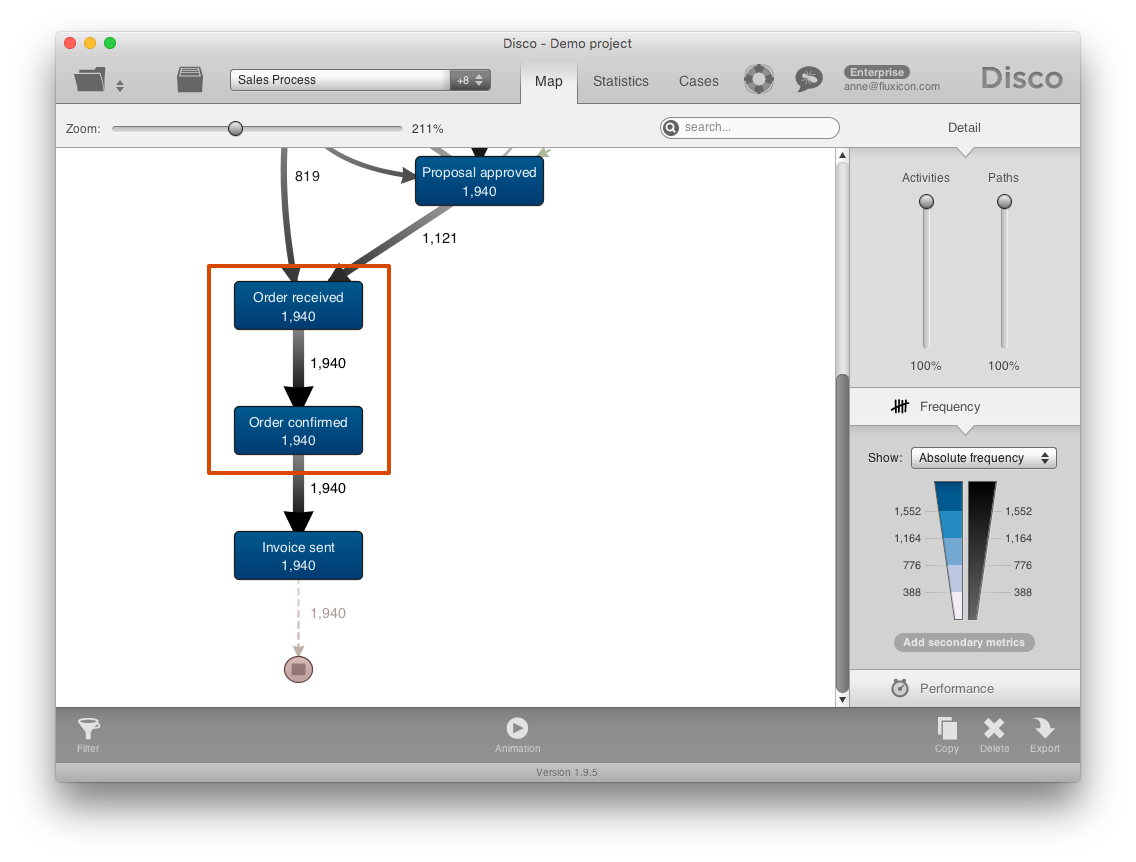
When the data set is imported with this new timestamp pattern configuration, only the dates are picked up and the order of the events in the file is used to determine the order of activities that have the same date within the same case (refer to our article on same timestamp activities for strategies about what to do if the order of your activities is not right).
As a result, the unwanted process flows have disappeared and we now see the ‘Order received’ activity show up before the ‘Order confirmed’ activity in a consistent way (see screenshot below).
Scaling back the granularity of the timestamp to the most coarse-grained time unit (as described in the example above) is typically the best way to deal with different timestamp granularities if you have just a few steps in the process that are more detailed than the others.
If your data set, however, contains mostly activities with detailed timestamps and then there are just a few that are more coarse-grained (for example, some important milestone activities might have been extracted from a different data source and only have a date), then it can be a better strategy to artificially provide a “fake time” to these coarse-grained timestamp activities to make them show up in the right order.
For example, you can set them at 23:59 if you want them to go last among process steps at the same day. Or you can give a time that reflects the typical or expected time at which this activity would typically occur.
Be careful if you do this and thoroughly check the resulting data set for problems you might have introduced through this change. Furthermore, it is important to keep in mind that you have created this time when interpreting the durations between activities in your analysis.

Anne Rozinat
Market, customers, and everything else
Anne knows how to mine a process like no other. She has conducted a large number of process mining projects with companies such as Philips Healthcare, Océ, ASML, Philips Consumer Lifestyle, and many others.