
(This article previously appeared in the Process Mining News Sign up now to receive regular articles about the practical application of process mining.)
It can be really easy to extract data for process mining. Some systems allow you extract the process history in such a way that you can directly import and analyze the file without any changes. However, sometimes it is not so easy and some preparation work is needed to get the data ready for analysis.
One typical problem in ERP systems is that the data is organized in business objects rather than processes. In this case you need to piece these business objects (for example document types in SAP) together before you can start mining.
The first challenge is that a common case ID must be created for the end-to-end process to be able to analyze the complete process with process mining. For example the process may consist of the following phases:
-
Sales order: traced by Sales order ID
-
Delivery: traced by Delivery ID
-
Invoicing: traced by Invoicing ID
To be able to analyze the complete process, all three phases must be correlated for the same case in one case ID column. For example, if a foreign key with the Sales order ID reference exists in the delivery and invoice phase, these references can be used for correlation and the case ID of the Sales order can be used as the overall case ID for the complete process.
A second–and somewhat trickier–challenge is that often there is not a clear one-to-one relationship between the sub case IDs. Instead, you may encounter so-called many-to-many relationships. In many-to-many relationships each object can be related to multiple objects of the other type. For example, a book can be written by multiple authors, but an author can also write multiple books.
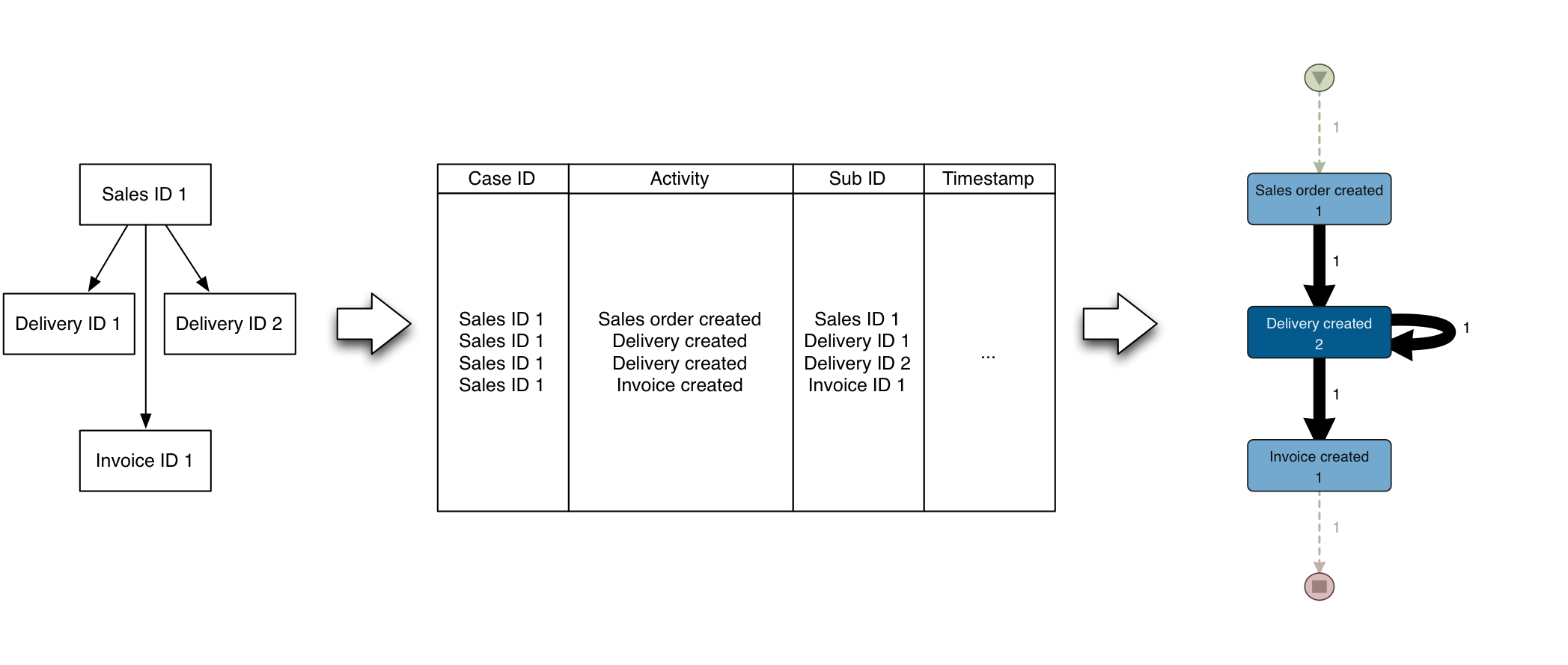
Imagine the following situation: A sales order can be split into multiple deliveries (see illustration below on the left). To construct the event log from the perspective of the sales order, in this case both deliveries should be associated with the same case ID (see middle). The resulting process map after process mining is shown on the right.
Going down the chain, a delivery can also be split-invoiced etc. The same principle applies.
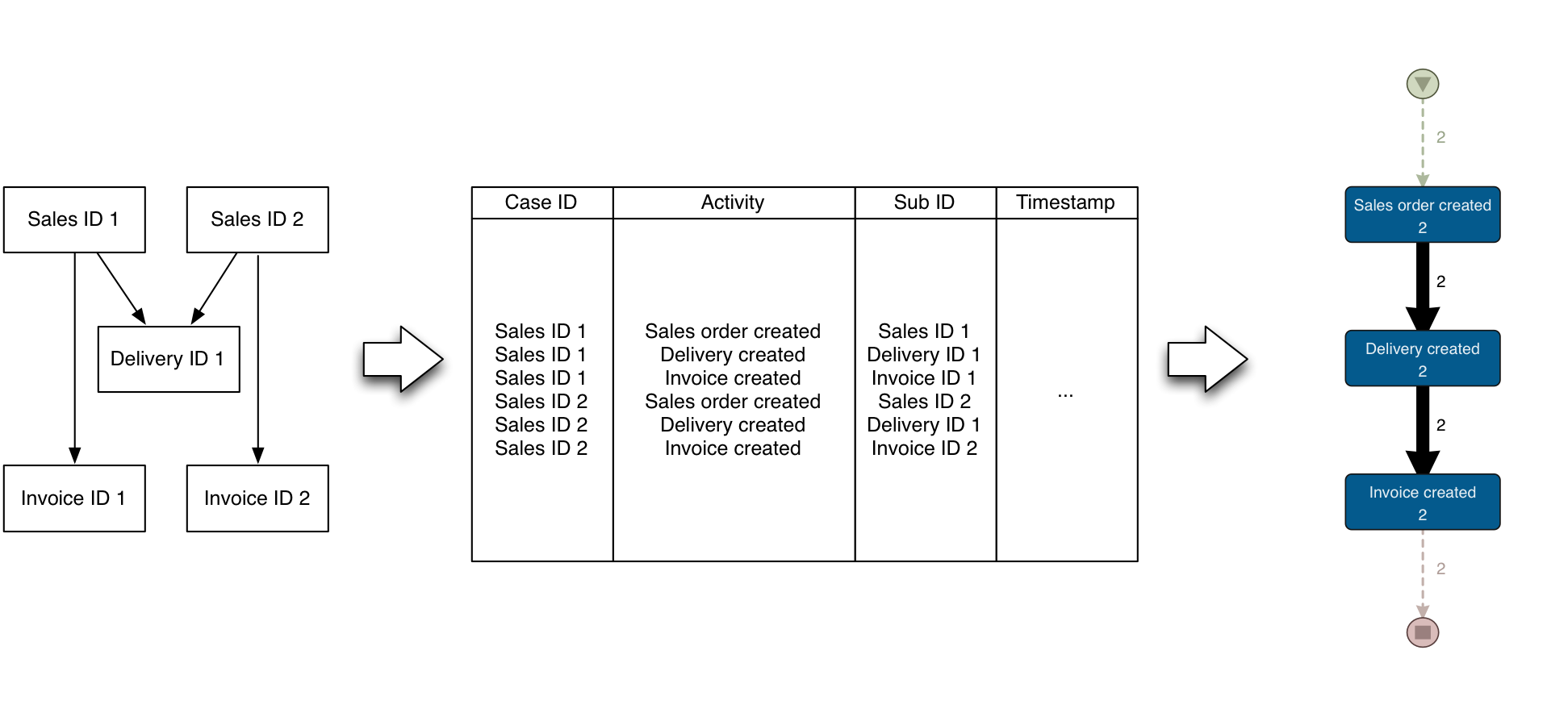
Conversely, it may also be the case that a delivery can combine multiple sales orders (see illustration below on the left).
In this case, again, to construct the event log from the perspective of the sales order, the combined delivery should be duplicated to reflect the right process for each case (see middle). As a result, the complete process is shown for each sales order and, for example, performance measurements between the different steps can be made (no performance measurements can be made in process mining between different cases).
The resulting process map is shown on the right.
To illustrate what would happen when the delivery is only associated to the first sales order, consider the example below.
It looks as if there was no delivery for sales order 2, which is not the case.
In return, one needs to be aware that the number of deliveries in the above mapping may be higher than the actual number of deliveries that took place. There were no two deliveries, just one!
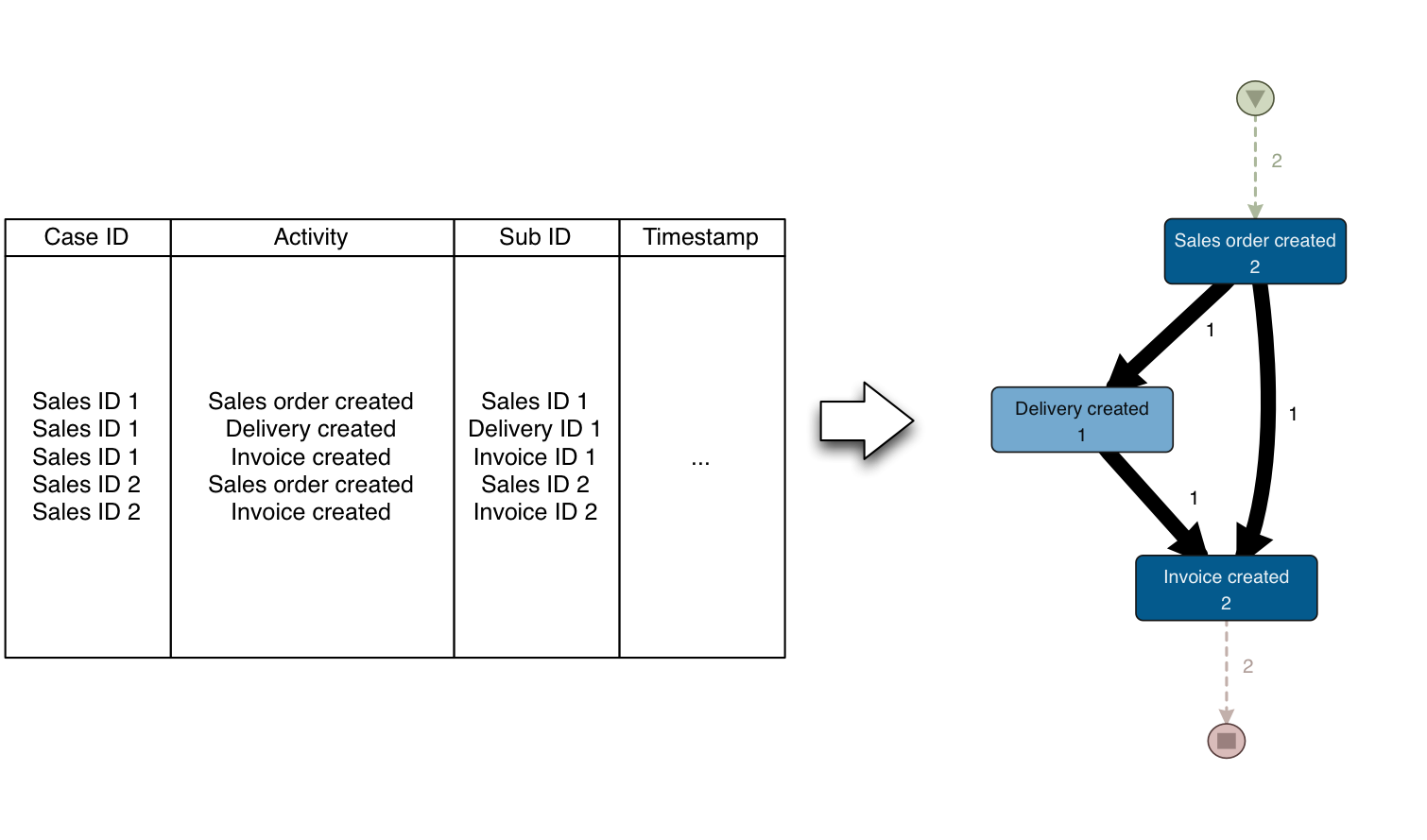
The point is that there is no way around this. Wil van der Aalst sometimes calls this “flattening reality” (like putting a 3D-world in a 2D-picture). You need to choose which perspective you want to take on your process.
What you can take away is the following:
-
Sometimes, multiple pieces of data need to be connected before you can start mining the end-to-end process
-
You need to think about the perspective that you want to take on your process (for example, sales order or delivery perspective?)
-
Often, different views can be taken during the extraction and may be needed for the analysis
What other challenges have you encountered when creating event logs from relational databases? Let us know in the comments!

Anne Rozinat
Market, customers, and everything else
Anne knows how to mine a process like no other. She has conducted a large number of process mining projects with companies such as Philips Healthcare, Océ, ASML, Philips Consumer Lifestyle, and many others.