
One of the big advantages of Process Mining is that it starts with the data that is already there, and usually it starts very simple. There is no need to first set up a data collection framework. Instead you can use data that accumulate as a byproduct of the increasing automation and digitization of your business processes. These data are collected right now by the various IT systems you already have in place to support your business.
If you are interested in Process Mining but are still new to this area, you probably have the following question:
What kind of data do I need to do process mining?
Or, if you have heard about process mining through academia, you might ask:
What exactly is an event log?
This posts aims to answer both questions.
The core idea of process mining is to analyze data from a process perspective. You want to answer questions such as “How does my As-is process currently look like?”, “Are there waste and unnecessary steps that could be eliminated?”, “Where are the bottlenecks?”, and “Are there deviations from the rules and prescribed processes?”.
To be able to do that, Process Mining approaches data with a mental model that maps the data to a process view.
Classification in data mining
To understand what this means, let us first take a look at another mental model: The mental model for classification in data mining.
Assume that you have a widget factory and you want to understand which kinds of customers are buying your widgets. On the left side below, you see a very simple example of a data set. There are columns for the attributes Name, Salary, Sex, Age, and Buy widget. Each row forms one instance in the data set that can be used for learning the classification rules.
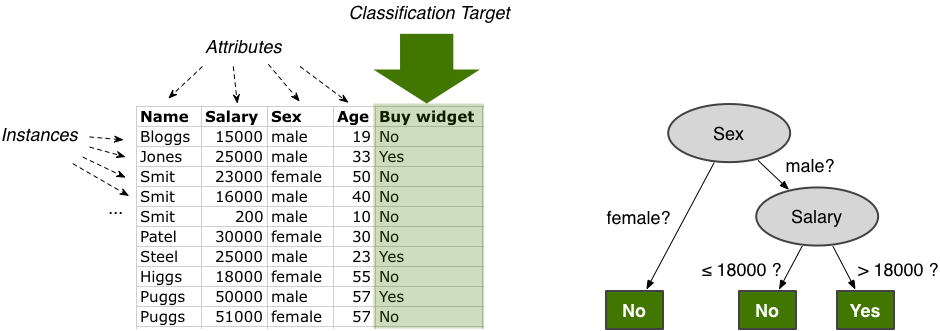
Before the classification algorithm can be started, one needs to determine which of the columns is the target class. Because we want to find out who is buying the widgets, we would make the Buy widget column the classification target. A data mining tool such as Weka would then be able to construct a decision tree like depicted on the right.
The result shows that only males with a high salary are buying the widgets. If we would want to derive rules for another attribute, for example, predict how old the customers will typically be that buy our widgets, then the Age column would be the classification target.
The mental model for process mining
For process mining, we have a slightly different meta model in mind because we look at the data from a process perspective.
Below, you see a simplified example data set from an internal call center case study. In contrast to the data mining example, an individual row does not represent a complete process instance, but just an event. That’s where the term event log comes from.
- Each event corresponds to an activity that was executed in the process.
- Multiple events are linked together in a process instance or case.
- Logically, each case forms a sequence of events—ordered by their timestamp.
From the data sample below, you can see why even doing simple process-related analyses, such as measuring the frequency of process flow variants, or the time between activities, is impossible using standard tools such Excel. Process instances are scattered over multiple rows in a spreadsheet (not necessarily sorted!) and can only be linked by adopting a process-oriented meta model.
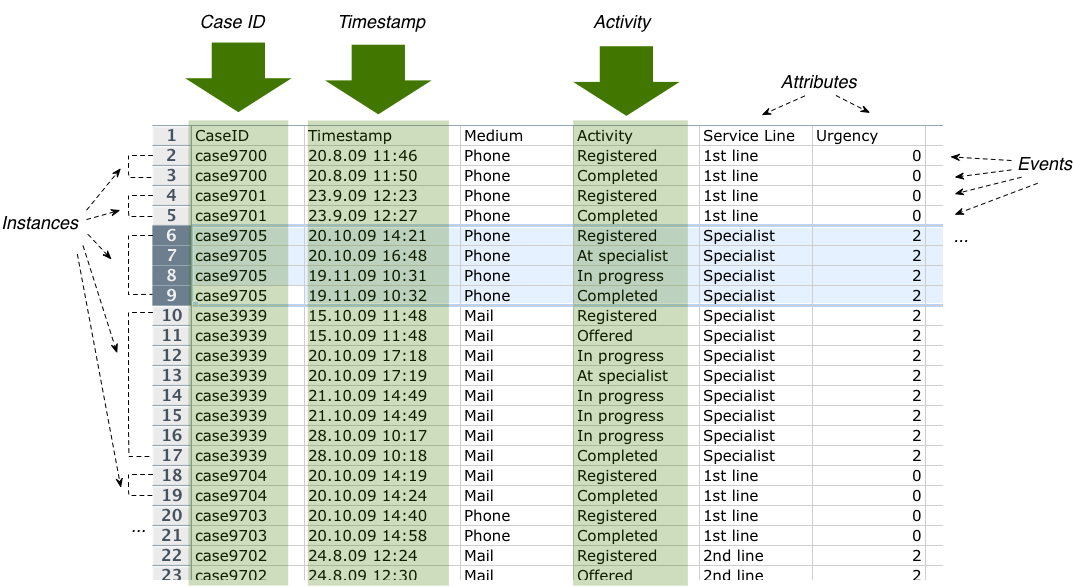
If you look at the highlighted rows 6–9, you can see one process instance (case9705) that starts with the status Registered on 20 October 2009, moves on to At specialist and In progress, and ends with status Completed on 19 November 2009.
The three requirements
The basis of process mining is to look at historical process data precisely with such a “process lens”. It’s actually quite simple. Regardless of where your data come from (database, log files, Excel sheet, data warehouse, etc.), the three minimal requirements are the following:
- Case ID: A case identifier, also called process instance ID1, is necessary to distinguish different executions of the same process. What precisely the case ID is depends on the domain of the process.
For example, in a call center, the case ID would be a service request number. In a hospital, this would be the patient ID.
- Activity: There should be names for different process steps or status changes that were performed in the process. If you have only one entry (one row) for each process instance, then your data is not detailed enough.
Your data needs to be on the transactional level (you should have access to the history of each case) and should not be aggregated to the case level.
- Timestamp: At least one timestamp is needed to bring the events in the right order. Of course you also need timestamps to identify delays between activities and identify bottlenecks in your process.
If you have a start and complete timestamp for each activity in the process, then a distinction between active and idle times in the process becomes possible.
Additional columns can be included for the analysis if available. For example, in the data sample there are further attributes that categorize the service request: A case was opened by phone, resolved by an external specialist, and the urgency was categorized as level 2. We might also include the resource or department that performed an activity. But the mandatory columns are just the three requirements above.
Summary
To summarize, all you need are data that can be linked to a case ID, activities, and timestamps. It does not matter where these data come from (ERP, CRM, workflow logs, ticketing system, PDM, HIS records, legacy log files, and so on), and you don’t need a BPM system with pre-modelled process models to get started with process mining.
It is one of the big advantages that process mining does not depend on specific automation technology or specific systems. It is a source system-agnostic technology, precisely because it is centered around the process-oriented mental model explained above.
I’ll do a follow-up post with answers to further questions about the data requirements for process mining. If you have questions, please leave a comment below or drop an email. Thanks!
-
Interestingly, it seems like BPM folks prefer the term process instance and case is used more in the context of ACM. For process mining, both terms are used interchangeably because it does not matter from which kind of system the data came from. ↩︎

Anne Rozinat
Market, customers, and everything else
Anne knows how to mine a process like no other. She has conducted a large number of process mining projects with companies such as Philips Healthcare, Océ, ASML, Philips Consumer Lifestyle, and many others.